上面我们已经演示了基本的文档 CRUD 功能,然而 Elasticsearch 的核心功能是搜索,所以在学习之前,为更好的演示这个功能,我们先往 Elasticsearch 中插入一些数据:
PUT /movies/movie/1
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": [
"Crime",
"Drama"
]
}
PUT /movies/movie/2
{
"title": "Lawrence of Arabia",
"director": "David Lean",
"year": 1962,
"genres": [
"Adventure",
"Biography",
"Drama"
]
}
PUT /movies/movie/3
{
"title": "To Kill a Mockingbird",
"director": "Robert Mulligan",
"year": 1962,
"genres": [
"Crime",
"Drama",
"Mystery"
]
}
PUT /movies/movie/4
{
"title": "Apocalypse Now",
"director": "Francis Ford Coppola",
"year": 1979,
"genres": [
"Drama",
"War"
]
}
PUT /movies/movie/5
{
"title": "Kill Bill: Vol. 1",
"director": "Quentin Tarantino",
"year": 2003,
"genres": [
"Action",
"Crime",
"Thriller"
]
}
PUT /movies/movie/6
{
"title": "The Assassination of Jesse James by the Coward Robert Ford",
"director": "Andrew Dominik",
"year": 2007,
"genres": [
"Biography",
"Crime",
"Drama"
]
}
_search端点
现在已经把一些电影信息放入了索引,可以通过搜索看看是否可找到它们。 为了使用 ElasticSearch 进行搜索,我们使用 _search 端点,可选择使用索引和类型。也就是说,按照以下模式向URL发出请求:
换句话说,为了搜索电影,可以对以下任一URL进行POST请求:
- http://localhost:9200/_search - 搜索所有索引和所有类型。
- http://localhost:9200/movies/_search - 在电影索引中搜索所有类型。
- http://localhost:9200/movies/movie/_search - 在电影索引中显式搜索电影类型的文档。
搜索请求正文和ElasticSearch查询DSL
如果只是发送一个请求到上面的URL,我们会得到所有的电影信息。为了创建更有用的搜索请求,还需要向请求正文中提供查询。 请求正文是一个JSON对象,除了其它属性以外,它还要包含一个名称为 “query” 的属性,这就可使用ElasticSearch的查询DSL。
{
"query": {
//Query DSL here
}
}
你可能想知道查询DSL是什么。它是ElasticSearch自己基于JSON的域特定语言,可以在其中表达查询和过滤器。你可以把它简单同SQL对应起来,就相当于是条件语句吧。
基本自由文本搜索:
查询DSL具有一长列不同类型的查询可以使用。 对于“普通”自由文本搜索,最有可能想使用一个名称为“查询字符串查询”。
查询字符串查询是一个高级查询,有很多不同的选项,ElasticSearch将解析和转换为更简单的查询树。如果忽略了所有的可选参数,并且只需要给它一个字符串用于搜索,它可以很容易使用。
现在尝试在两部电影的标题中搜索有“kill”这个词的电影信息:
GET /_search
{
"query": {
"query_string": {
"query": "kill"
}
}
}
执行上面的请求并查看结果,如下所示 -

正如预期的,得到两个命中结果,每个电影的标题中都带有“kill”单词。再看看另一种情况,在特定字段中搜索。
指定搜索的字段
在前面的例子中,使用了一个非常简单的查询,一个只有一个属性 “query” 的查询字符串查询。 如前所述,查询字符串查询有一些可以指定设置,如果不使用,它将会使用默认的设置值。
这样的设置称为“fields”,可用于指定要搜索的字段列表。如果不使用“fields”字段,ElasticSearch查询将默认自动生成的名为 “_all” 的特殊字段,来基于所有文档中的各个字段匹配搜索。
为了做到这一点,修改以前的搜索请求正文,以便查询字符串查询有一个 fields 属性用来要搜索的字段数组:
GET /_search
{
"query": {
"query_string": {
"query": "ford",
"fields": [
"title"
]
}
}
}
执行上面查询它,看看会有什么结果(应该只匹配到 1 行数据):
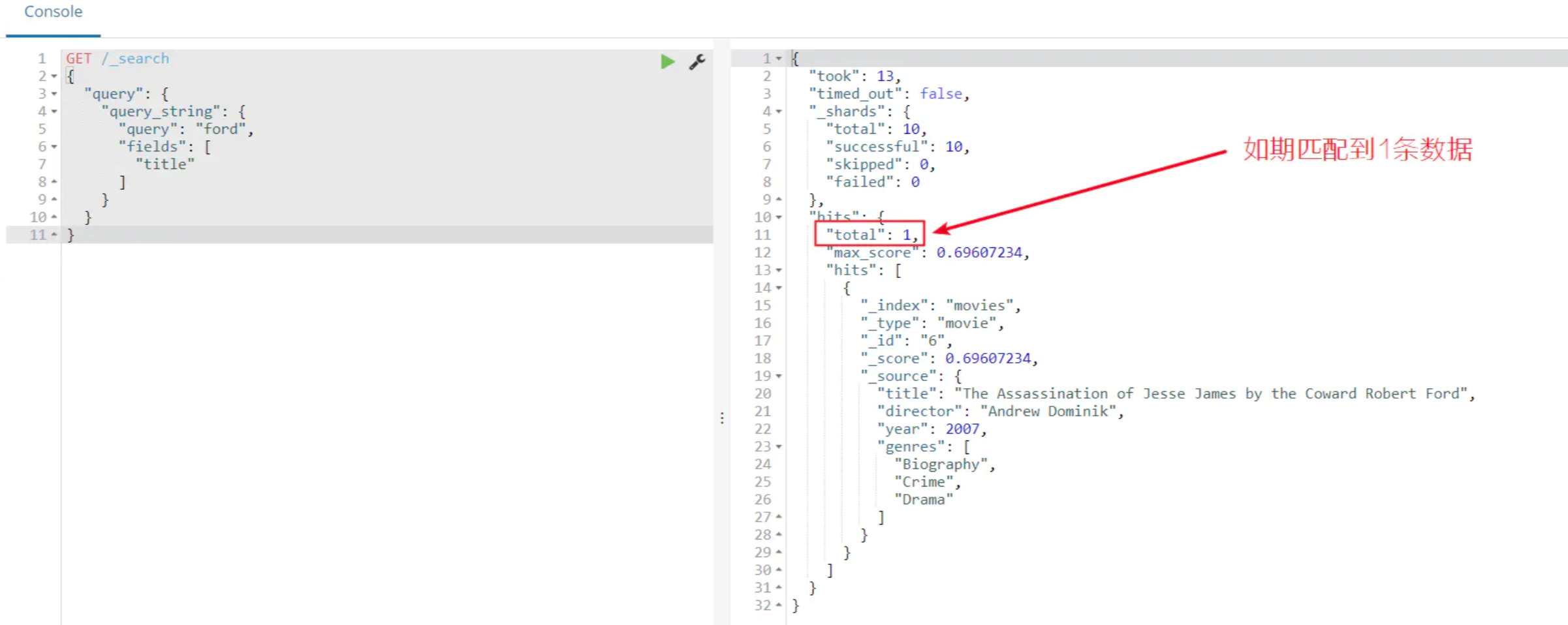
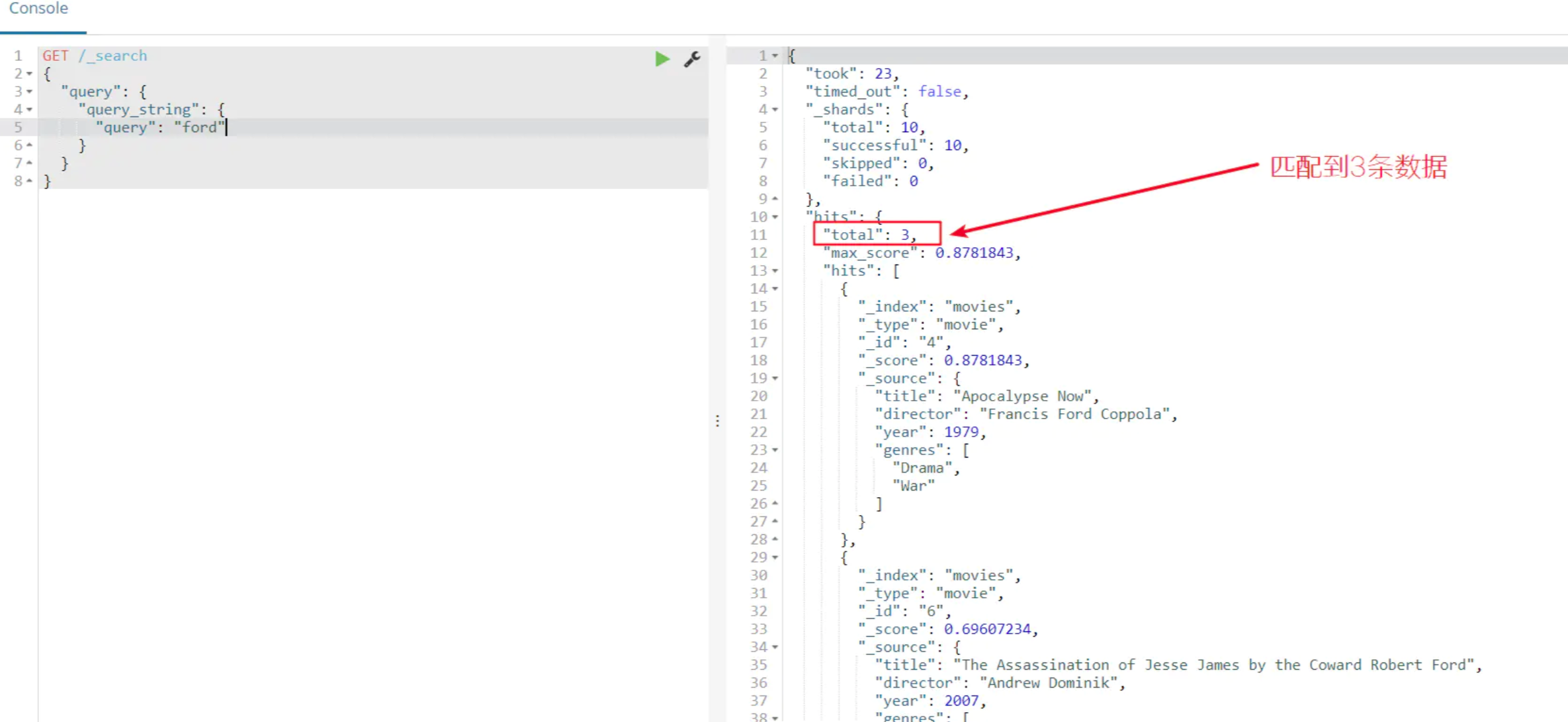
正如预期的得到一个命中,电影的标题中的单词“ford”。现在,从查询中移除fields属性,应该能匹配到 3 行数据:
过滤
前面已经介绍了几个简单的自由文本搜索查询。现在来看看另一个示例,搜索 “drama”,不明确指定字段,如下查询 -
GET /_search
{
"query": {
"query_string": {
"query": "drama"
}
}
}
因为在索引中有五部电影在 _all 字段(从类别字段)中包含单词 “drama”,所以得到了上述查询的 5 个命中。 现在,想象一下,如果我们想限制这些命中为只是 1962 年发布的电影。要做到这点,需要应用一个过滤器,要求 “year” 字段等于 1962。要添加过滤器,修改搜索请求正文,以便当前的顶级查询(查询字符串查询)包含在过滤的查询中:
{
"query": {
"filtered": {
"query": {
"query_string": {
"query": "drama"
}
},
"filter": {
//Filter to apply to the query
}
}
}
}
过滤的查询是具有两个属性(query和filter)的查询。执行时,它使用过滤器过滤查询的结果。要完成这样的查询还需要添加一个过滤器,要求year字段的值为1962。
ElasticSearch查询DSL有各种各样的过滤器可供选择。对于这个简单的情况,某个字段应该匹配一个特定的值,一个条件过滤器就能很好地完成工作。
"filter": {
"term": { "year": 1962 }
}
完整的搜索请求如下所示:
GET /_search
{
"query": {
"filtered": {
"query": {
"query_string": {
"query": "drama"
}
},
"filter": {
"term": {
"year": 1962
}
}
}
}
}
当执行上面请求,只得到两个命中,这个两个命中的数据的 year 字段的值都是等于 1962。
无需查询即可进行过滤
在上面的示例中,使用过滤器限制查询字符串查询的结果。如果想要做的是应用一个过滤器呢? 也就是说,我们希望所有电影符合一定的标准。
在这种情况下,我们仍然在搜索请求正文中使用 “query” 属性。但是,我们不能只是添加一个过滤器,需要将它包装在某种查询中。
一个解决方案是修改当前的搜索请求,替换查询字符串 query 过滤查询中的 match_all 查询,这是一个查询,只是匹配一切。类似下面这个:
GET /_search
{
"query": {
"filtered": {
"query": {
"match_all": {}
},
"filter": {
"term": {
"year": 1962
}
}
}
}
}
另一个更简单的方法是使用常数分数查询:
GET /_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"year": 1962
}
}
}
}
}