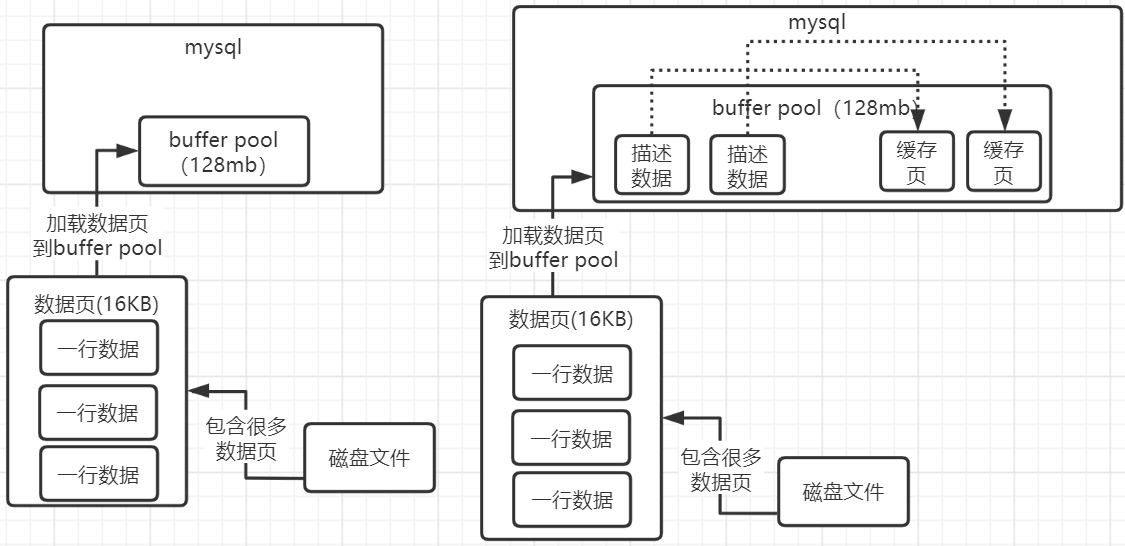
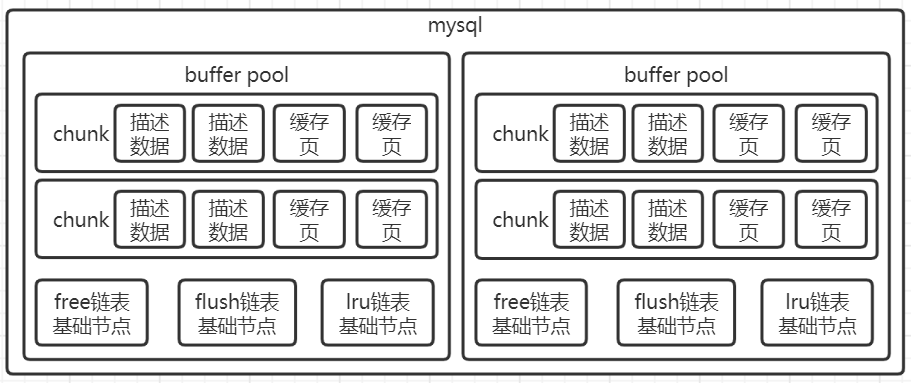
在innodb引擎执行流程中,我们已经知道了buffer pool的重要性,对数据库执行增删改查操作,其实都是在内存里的Buffer Pool中进行的。buffer pool的本质就是一片数据内存结构,默认比较小只有128mb,由一大堆的缓存页和描述数据块组成的,然后加上了各种链表(free、flush、lru)来辅助他的运行。
数据页
在操作数据的时候,都是基于buffer pool操作的。它会将数据加载到buffer pool的数据页(也叫缓存页)中,每一页都放了很多行数据,默认每个数据页的大小是16kb。 每个缓存页都会对应一个描述信息,这个描述信息本身也是一块数据存在Buffer Pool中,数据只有缓存页的5%左右。它包含了:这个数据页所属的表空间、数据页的编号、这个缓存页在Buffer Pool中的地址以及别的一些杂七杂八的东西。
free链表与flush链表
刚才已经知道mysql启动后初始化buffer pool会划分出一个个缓存页和描述数据。其实buffer pool中设计了一个free链表,它就是这些"描述数据"组成的双向链表,可以理解成每个描述数据块里都有两个指针,一个是free_pre,一个是free_next,分别指向自己的上一个free链表的节点,以及下一个free链表的节点。free链表中,只有一个基础节点不属于buffer pool,他是40字节大小的一个节点,里面就存放了free链表的头节点的地址,尾节点的地址,还有free链表里当前有多少个节点。
我们怎么知道哪些缓存页是空闲的呢?其实数据库还会有一个哈希表数据结构,他会用表空间号+数据页号,作为一个key,然后缓存页的地址作为value。当你要使用一个数据页的时候,通过“表空间号+数据页号”作为key去这个哈希表里查一下,如果已经有了,就说明数据页已经被缓存了;如果没有就读取数据页,然后从free链表中找到一个空闲的缓存页写入数据。最后写入数据页缓存哈希表
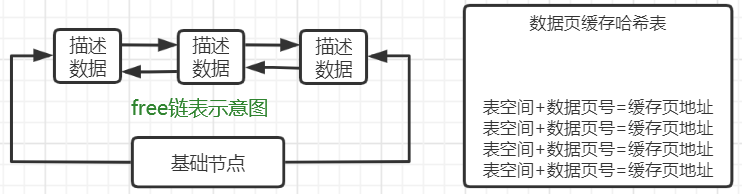
我们知道会有一个后台线程将缓存页的脏数据刷盘到磁盘文件,没有修改过的肯定不用刷盘,那buffer pool中那么多缓存页怎么知道哪些是需要刷盘的呢?所以数据库引入了和free链表类似的一个双向链表——flush链表,凡是修改过的内存页就会放到里面去,这就能知道哪些是脏页了。
缓存淘汰算法
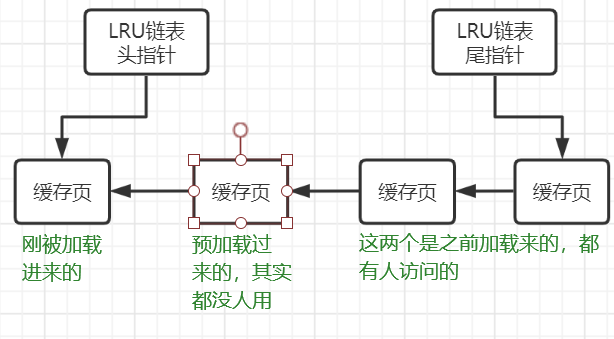
内存是有限的,buffer pool装满之后又该怎么办呢?这就牵扯到内存淘汰算法问题。mysql就是基于LRU算法实现的,LRU就是Least Recently Used,最近最少使用的意思。它会将最近使用的数据放在前面,然后每次回收末尾的数据,但是这样就有个问题,这样容易导致误伤清理掉需要经常用的数据,造成这个问题的原因有两个:
1. 全表扫描查出的冷门数据,最近使用的数据可能仅仅是很少使用的数据,这种数据一直留在内存中是意义不大的、最好尽快清理掉。
2. mysql的预读机制,举个例子现在有两个空闲缓存页,你在加载数据时会连带将它相邻的数据页页加载到缓存页中,可能这页数据都不怎么使用的。但是mysql这么设计,是它认为同一个数据页的数据被使用到的几率比较大才这么设计的。
冷热数据分离
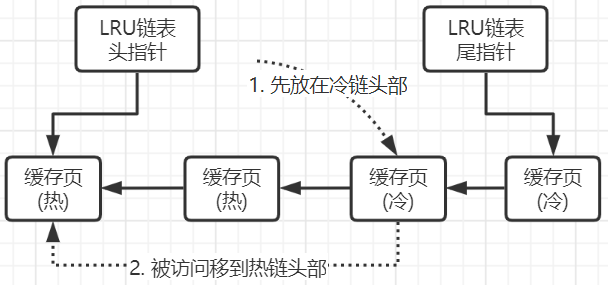
造成刚才问题的根本就是所有缓存页都在一个LRU链表里面,所以其实mysql的LRU链表是由两部分组成,一部分是热数据、一部分是冷数据。比例由innodb_old_blocks_pct参数控制的,他默认是37,也就是说冷数据占比37%。这样只需要定时淘汰冷链尾部和flush链表中的一些缓存页就好了。
第一次访问的数据都是放在冷链的头部,如果1s之后再次被访问则会放到热链头部中去,是由innodb_old_blocks_time参数控制的,默认值1000,也就是1000毫秒。但是你要知道,热数据区域里的缓存页可能是经常被访问的,所以这么频繁的进行移动是不是性能也并不是太好?也没这个必要。所以只有在热数据区域的后3/4部分的缓存页被访问了,才会给你移动到链表头部去。
buffer pool优化
一般我们设置buffer pool大小的时候,都是设置你的机器内存的50%~60%左右比如你有32GB的机器,那么给buffer设置个20GB的内存,剩下的留给OS和其他人来用,这样比较合理一些。然后一个buffer pool实际上是由很多chunk组成的,他的大小是innodb_buffer_pool_chunk_size参数控制的,默认值就是128MB。每个chunk就是一系列的描述数据块和缓存页。但每个buffer pool是只有一套free、flush、lru的链表的。
有一个很关键的公式就是:buffer pool总大小=(chunk大小 * buffer pool数量)的倍数。比如默认的chunk大小是128MB,那么此时如果你的机器的内存是32GB,你打算给buffer pool总大小在20GB左右,那么你得算一下,此时你的buffer pool的数量应该是多少个呢?假设你的buffer pool的数量是16个,这是没问题的,那么此时chunk大小 * buffer pool的数量 = 16 * 128MB =2048MB,然后buffer pool总大小如果是20GB,此时buffer pool总大小就是2048MB的10倍,这就符合规则了;又或者此时你可以设置多一些buffer pool数量,比如设置32个buffer pool,那么此时buffer pool总大小(20GB)就是(chunk大小128MB * 32个buffer pool)的5倍,也是可以的。
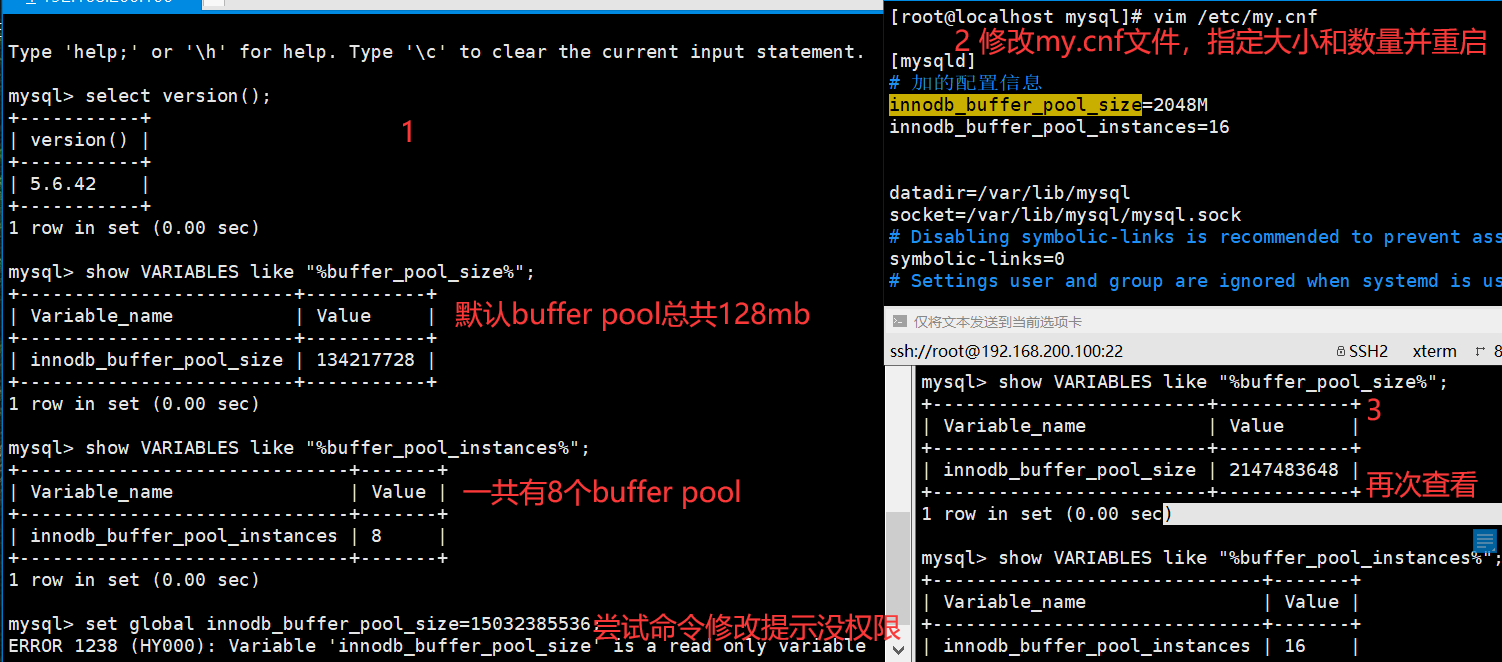
innodb_buffer_pool_size=2048M
innodb_buffer_pool_instances=16
我这里给buffer pool设置了2GB的总内存,然后设置了他应该有16个Buffer Pool,此时就是说,每个buffer pool的大小就是128m,每个buffer pool有1个chunk。
。