paper url: https://arxiv.org/abs/1811.08883
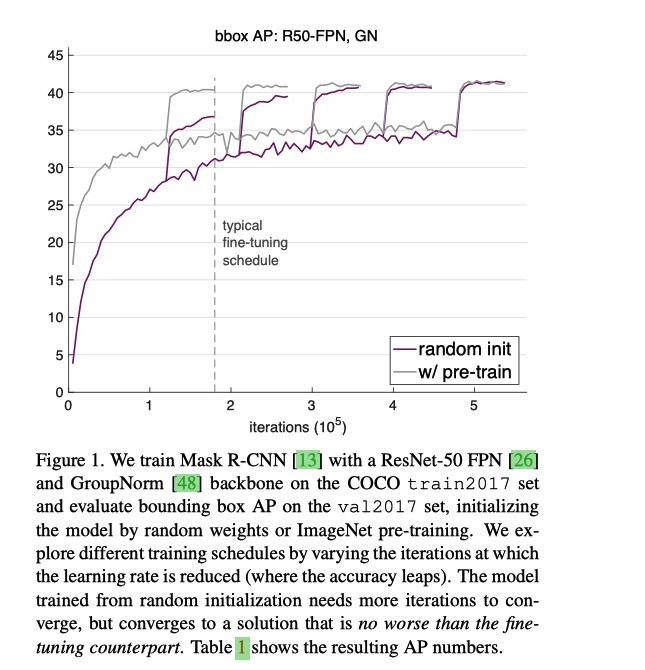 

当在数据量足够和训练iterations足够的情况下,ImageNet pretrain不会对最后的性能有帮助,但是会加速收敛(需要用GN或SyncBN);
当数据量不够的情况下, 模型是需要在 ImageNet 上预训练的
- training from scratch 是可行的, 但是需要合适的 normalization(如GN)和更多的迭代。
- 根据数据量等情况,training from scratch 可以不比 fine-tune 的效果差。
- fine-tune 的方式还是收敛速度快很多。
- 除非, 目标数据集规模很小, fine-tune 是没有办法减少过拟合的; fine-tune 时候, 需要让大的 lr迭代次数更多,如果小的lr迭代次数过多的话,很容易过拟合。
- 对于位置敏感的任务,在分类任务上预训练的模型进行 fine-tune 的效果会变小; 比如需要对目标精确定位的任务,在 ImageNet 上预训练的模型上 fine-tune 没效果,比如 keypoint 的任务。