一、数据来源
COCO中图片资源均引用自Flickr图片网站
二、数据集创建目的
进行图像识别训练,主要针对以下三个方向:
(1)object instances
(2)object keypoints
(3) image captions
每个方向均包含训练和验证集两个标注文件
三、标注体结构
三个方向均共享基本类型信息,包括info、image、license三个字段,而annotation字段则各不相同。
3.1 通用字段介绍
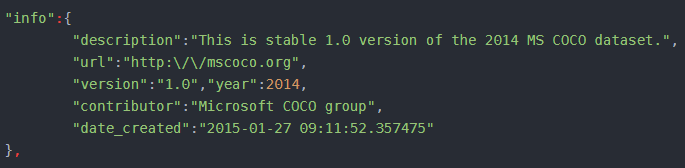
- 通用-Info字段
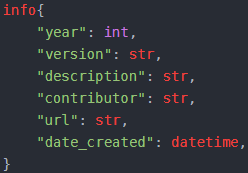
例:
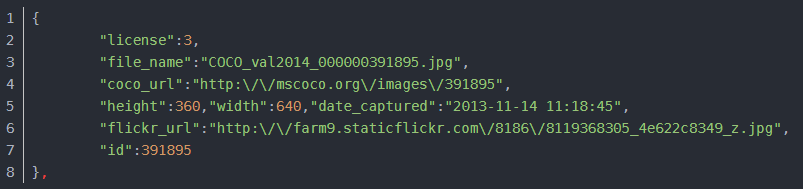
- 通用-image字段
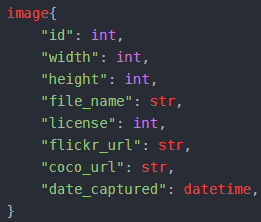
例:
- 通用-licence字段
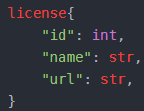
例:

3.2 变体字段介绍
- annotation-Object Instance
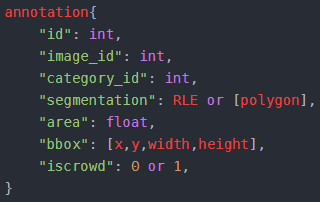
iscrowd=0:表示这是一个单独的物体,轮廓用Polygon(多边形的点)表示,即segmentation字段用Polygon表示
iscrowd=1:表示两个或多个没有分开的物体,轮廓用RLE编码表示,即segmention字段用RLE编码形式表示
- annotation-Object keypoint
相比于object Instance标注,增加了两个字段:Keypoints和num_keypoints
keypoints是一个长度为3*k的数组,其中k是keypoints的总数量。
keypoints[i][0] 和keypoints[i][1]为(x,y),keypoints[i][2]为标志位v
v=0-关键点未标注,v=2-关键点已标注且不可见,v=3-关键点已标注且可见
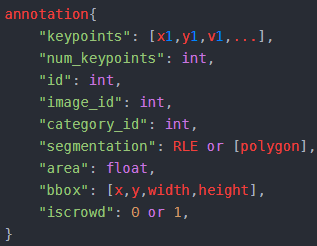
category字段:
keypoints字段记录了关键点名字数组,skeleton定义了各个关键点之间的连接性(如手腕和肘)。keypoints的supercategory只标注了person 。
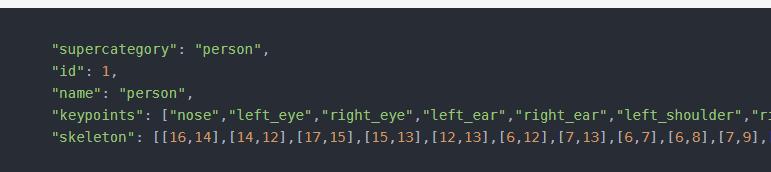
Image Caption类型的标注相对于上面来说很简单,这里就略过不表了