**************************************************20190825**************************************************
1. 分析问题应该是从多个角度来进行分析,这个出发点是正确的。
2. 量化投资不外乎就是数据+模型两个方面,多数人都是在研究模型以及各种算法来取得更好的结果。这种做法其实违反了基本假设的前提条件,比如说:某个模型都是基于某某假设的前提下得到某种结果,换句话说很多人在研究模型的时候都已经忘却了前提条件,这就好比温室养花与室外养花得到结果肯定是一致是不正确的。很多人又会说这就是现实和理论之间的差距,用偏差、参数优化等方式来解释和操作,那为什么不给模型一个更好的数据源呢?
不重视数据的处理,而只去研究模型的做法就好比缘木求鱼的道理是一样的。这篇论文就是研究数据的更合理的表示方式,让模型安放更好的更好、更合理的土壤上面去成长,当然不是说这么做就完全得到最好的结果,但是事实上来说这样做肯定会促进整体的效果。
3. 这里的金融数据指的是价格信息。理论基础是“价格反映一切信息”。这句话是没问题的。
4. 最常见的数据表达方式有K线、美国线、收盘线。不常见的数据表达方式有砖形图(Renko)、OX图、新价线、Heshi图等。
5. 最简单的一个分类就是价齐和时齐的两种数据表达方式。K线之类是按照规定的时间框架中去表达在这个时间框架内数据变动,比如有开、高、低、收等。另外,像Renko图之类规定价格在某个波动范围框架中去表达,满足波动范围形成新的数据结点。
6. 这两类那种表达数据更好?价齐的表达具有更好的“降噪”作用,因为在价齐的数据表达过程中价格是等量的表达。但是也不能这么肯定。
7. 数据的表达方式其实不是二维的(时维度、价维度),应该是三维的。我们知道比如ATR之类的数据表达方式是用波动状态来表达数据。
* 小结:
数据常用的表达方式有时齐、价齐两种。
数据还有像波动状态等。
数据表达有三个维度:时维度、价维度、其他维(即不是价维也不是时维的其他表达方式)。
**************************************************20190826**************************************************
1. K线之类的缺点:
为什么说K线之类的缺点,是因为诸如K线,美国线,Heshi线等属于时齐的一类线,他们从本质上来说都是有开高低收等表示方式。
缺点1:时齐
现实的交易过程是交易的价格而不是交易的时间。用“时间刀”去切理论上是不对的,属于主观和人为的方式。其实我们平时是观察的价格的变动而不是时间的变动。因此时间维度的这种做法是不太合理的。
用物理的角度来说,爱因斯坦说:时间和空间在质量过大的时候会造成时间和空间的弯曲,其实在金融市场上这种现象是特别明显的。
也就是说每根K线的“质量”不一样所造成的时间和空间会产生错觉。因为K线的“质量”会造成周围空间和时间的弯曲程度不一样。但是这种弯曲程度是人们感觉不出来的。如果一根质量过大的K线和一根质量过小的K线他们内核的质能肯定也是会不一样的。因为我们希望我们观察的目标具有一致性,如果观察的数据本身具有强烈的非线性状态是很难找出他们的规律的。
缺点2:经验性
K线的发明是为了用一种图表化的数据表达方式。产生某一种组合会表示一种涨跌状态,这是缺乏科学根据的,也是具有主观性的。
缺点3:合成规则
K线的有些软件规则不一致,比如MC用优先时间的方式标识,TB用当前时间表示;再比如在博易大师里面,K线的合成依据也是和其他软件不一致的。因此这就造成了在其他软件当中看是一种状态,在其他软件中看又是一种状态,看似细微的差别会导致进场点、出场点的差异,可能造成亏损。
缺点4:非线性
正如缺点1里面所说的,K线的表述方式是非线性的。我们很多的算法和模型都是建立在线性数据的基础上的。如果数据是非线性会产生较多的“噪音”给予错误的输入。正如数据挖掘中强调的“垃圾进、垃圾出”,如果让模型发挥最大的作用,数据的数据的方式是必须强调的。给模型输入线性和更加准确的数据输入是必须强调的。
2. 关于数据源:
K线可能在其他软件里面有略微的差别,但是每套软件在tick级别的上都是统一的。因为所有的软件的数据接口基本上都是来自于端口的数据供给,数据也是源自交易所提供的,因此这个层面都是一致的。所以tick级别是唯一统一的数据源,当然任何K线和其他图标也都是基于这个数据源按照相关规则合成的。
时齐的问题我们上面说到了。其实从本质上来说tick数据也是一种时齐的数据,因为根据交易所数据提供的规则:期货的tick数据是500ms进行一次切片处理,股票市场是250ms进行一次切片。从这个角度上来说tick数据之下再微小的颗粒是分笔数据,这个数据是最小的分子。但是我们除非做高频交易,用tick数据的这点差别可以做“忽略”处理。
3. 砖形图(Renko)的成交问题:
以MC为例,砖形图这种价齐的方式看起来是很合理的,因为每一个“结点”的数据都是等距的,是具有“局部线性”的特点。但是每次下单的的时候下一根的砖的价格和实际价格会产生偏移,这给实际成交造成很小的略微偏差,但是总体而言会产出巨大的偏差。
另外,如果采取上一个的MC的close价格进行交易也会有问题,因为最后一个close价格也不一定是实际的价格(有些价格是不存在)
* 小结:
局部线性
成交
Tick数据源
是不是可以把成交价位分开,促进直接成交?
**************************************************20190904**************************************************
1. 经济数据的类型各式各样。尽管我们可以在许多不同的数据集不做任何修改的情况下使用某些计量方法,但仍有必要对某些数据集的特殊性质进行阐释并加以利用。下面就是会遇到的几种重要的数据结构。
2. 横截面数据集(cross-sectional data set)
就是在给定时点对个人、家庭、企业、城市、州、国家或一系列其他单位采集样本所构成的数据集。有时候,所有单位的数据并非完全对应某一时段。例如,几个家庭可能在一年中的不同星期被调查。在一个纯粹的横截面分析中,我们应该忽略数据搜集中细小的时间差别。如果一系列家庭都是同一年的不同星期被调查,我们仍视为横截面数据集。
横截面数据集的特征,我们通常可以假定,他们是从样本背后的总体中通过随机抽样(random sampling)而得到的。
问题:
横截面数据的随机抽样的真假
横截面数据的随机抽样的大小
3. 时间序列数据集(time series data set)
就是由对一个或几个变量不同时间的观测值锁构成。
特点:
与横截面数据的排序不同,时间序列对观察值按照时间先后排序,也传递了潜在的重要信息。
数据频率(data frequency)也是时间序列数据的特征。
问题:时间序列有一个关键特征,使得对它的分析比对横截面数据分析更为困难。这个特这就是:很少假设经济数据观测独立与时间。多数经济及其他时间序列都与其近期历史相关,通常是高度相关。虽然多数计量程序技能用于横截面数据,又能用于时间序列数据,但在认为标准的计量方法能适用之前,在设定时间序列数据的计量模型上,还有更多工作要做。此外,为了解释和利用经济时间序列的相互依赖性,并解决某些经济变量常表现出清晰的事件趋势等问题,标准的计量方法还需要改进和润色。
3. 混合横截面数据集(pooled cross section)
有些数据机油截面数据的特点,又有时间序列的特征。
混合横截面数据的分析与对标准横截面数据的分析十分相似,不同之处在于,前者通常要对变量在不同时间的长期差异作出解释。事实上,除了能扩大样本容量之外,混合横截面分析通常是为了让我们看出一个基本关系如何随时间而变化。
4. 面板/从列数据集(panel data)
由数据集中每个横截面单位的是一个时间序列组成。
面板数据要求同一单位时间不同时间的重复观测,所以要得到面板数据比得到混合横截面数据更加困难。统一观测单位观测一段时间,应该比哼见面数据甚至混合横截面数据更有优越性。
5. 以图表的形式展示这四种数据
横截面数据:
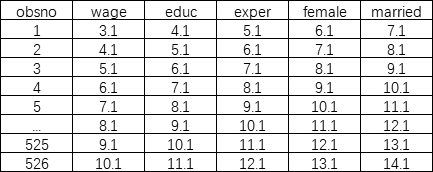
第一种横截面数据:有关工资和其他个人特征的横截面数据集
第二种横截面数据:有关经济增长率和国家特征方面的数据集
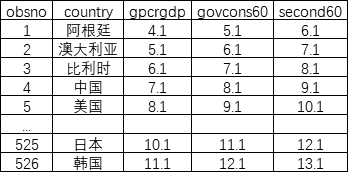
我们发现横截面数据就是多元变量之间的关系,是变量和变量之间的关系。没有时间的概念。也可以理解为变量和变量之间的比较。
时间序列数据
举例:波多黎各的最低工资、实业及其相关数据
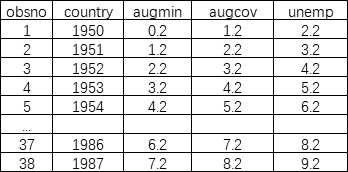
我们发现时间序列数据是一元变量自己的关系,是一元变量内的关系。有时间的概念,按照实际排序。也可以理解为变量和自己之间的比较。
混合横截面数据
举例:两年的住房价格

从这个例子中我们发现混合横截面数据和横截面数据很像,但是里面加入了时间排序。也可理解为时间序列数据和横截面数据的组合体。
面板数据
举例:城市犯罪统计量的一个两年面板数据集

面板数据有区别与前面三种数据。这个数据集可以看做几个年份的两个横截面数据混合起来,由在两个年份出现的城市所组成。可以理解为数据先经过了数据统计和加工后形成的数据。前面三种是比较原始的数据。
优点一:面板数据可能要对同一个观测单位要多次进行观测和统计,但正如我们看到的,使用不止一次的观测,使我们在单纯横截面数据下很难做出的推断得以进行。
优点二:它通常使我们能够研究决策行为或结果中的之后的重要性。由于预期许多经济政策在一段时间之后才产生影响,所以面板数据所反映的信息更有意义。
6. 金融市场对于4中数据的区分
根据上面的数据定义。
第一种:像图表中插入N个品种,横轴是时间纵轴是价格。
从上面竖着切一刀(刀的大小随意,根据随机性理论定的),取出每一段来观察,这就是横截面数据。
第二种:观察一个单一品种,横轴是时间纵轴是价格。
这样就是一个时间序列数据,因此存在时间顺序也就是数据频率,而且还具有趋势性。
第三种:图表中插入N个品种,横轴是时间纵轴是价格。
不取每一段观察,按照第二种的观察方式,这就是混合横截面数据。
第四种:调出砖形图,OX图,横轴是时间(但是此处的时间不是等距的,我们可以看做单位序列排序)纵轴是价格。
这种加工好的数据就是面板数据。
7. 通过概念来看面板数据具有更好的数据性质。
**************************************************20190000**************************************************