小番在这里
这里涉及了一些反爬手段与方法,老铁们赶紧拿起小板凳开始听了哦

爬取思路:

打开一个番剧,找到播放页面,开始F12 检查元素发现直接跳回首页了,这就没法用浏览器自带的抓包了。可以使用抓包工具fiddle进行抓包。先不急着抓包,先看看播放页的源代码
view-source:www.zzzfun.com/vod_play_id_2029_sid_1_nid_1.html

可以得到每一话的链接,那么还少了视频链接,网页源代码里面没有,只能抓包了。

可以发现debug调试时跳转的代码,在右下角窗口中继续找有用的信息,找到了m3u8链接

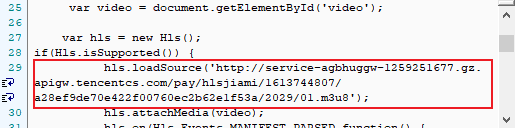
经过测试,这个链接时效性很短,使用requests库保存为.m3u8后缀,用txt文件类型打开后发现很多链接,如图,这就是我们需要下载的了,有老铁怀疑这里面的链接会不会变啊,抓包分析不断比对同一集m3u8里的这个链接,发现这个链接是不变的哦,只有那个m3u8会变的hahah~~

将它们提取出来,下载下来又该怎么合成呢,其实使用requests库以ab形式追加将二进制内容写入一个文件,就行了,这是其他的读写文件参数一篇搞懂python文件读写操作(r/r+/rb/w/w+/wb/a/a+/ab)
这样我们的基本思路就完成了,剩下只需要将这个链接请求获得m3u8地址,之后下载即可,而这个链接是有规律的(与刚开始打开的一部番剧主页面有关哦),大家可以自行抓包尝试一下哦~~
遇到的坑:
但是这个完整视频下载下来后,我用的爱奇艺播放器竟然打不开,就很纳闷用了potplayer,还是挺香的,可以正常播放,大家要是不能播放可以换换播放器哦
小结
- 使用{:0>2d}在数字前面补0满足两位数,如{:0>2d}.format(3),补0后结果为03
- 由于番名是由图片嵌上去的,就使用了百度AI的文字识别接口,很简单,先登录百度智能云,左侧选择文字识别,创建应用

将API Key 和Secret Key 写入代码即可,代码里依旧保存我的AK和SK,大家有兴趣的话可以替换成自己的就可以运行啦,(详细的文档说明),如果由于某种原因失败,会默认创建‘番剧’的文件夹,要下载的番剧视频就在那里面哦 - 番名的那个图片Url需要用requests带headers下载,用request.urlretrieve会下载失败
注意
如果出现·
list index out of range报错,请检查网站页面是否变成了

点一下继续访问即可
单线程版:
import re,requests
import requests,json,time
from tqdm import tqdm
import urllib3,os
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
headers = {
'Host':'p1.pstatp.com',
'Connection':'keep-alive',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36',
'Origin':'http://www.zzzfun.com'
}
def get_urls_to_download(url):
r = requests.get(url)
# print(r.text)
urls = [ 'http://www.zzzfun.com/'+ i for i in re.findall('vod_play_.*?html',r.text)[1:]]
urls = urls[:(len(urls)//2)]
global num
num = len(urls)
id = re.search('_id_(.*?).',url).group(1)
get_m3u8 = ['http://www.zzzfun.com/static/danmu/bed-bofang.php?{}/{:0>2d}.m3u8'.format(id,i+1) for i in range(num)]
write_slices(get_m3u8)
for i in range(num):
line_uls = []
name = '第{:0>2d}话.m3u8'.format(i+1)
with open(name,'r')as f:
lines = f.readlines()
for line in lines:
if 'http' in line:
line_ul = line.replace('
','')
line_uls.append(line_ul)
download_m3u8(i,line_uls)
os.remove(name)
def write_slices(urls):
for i in range(num):
r = requests.get(urls[i])
r.close()
ul = re.search('http://service.*?m3u8',r.text).group(0)
r = requests.get(ul,verify=False)
r.close()
with open('第{:0>2d}话.m3u8'.format(i+1),'wb')as f:
f.write(r.content)
f.close()
def download_m3u8(i,line_uls):
name = '第{:0>2d}话'.format(i+1)
size=0
for ur in tqdm(line_uls,desc=name,ncols=80):
headers.update({'Host':ur.split('/')[2]})
r = requests.get(ur,headers=headers,verify=False)
size = size + int(r.headers.get('content-length',0))
with open('./{}/'.format(fanju_name)+name+'.mp4','ab')as f:
f.write(r.content)
print(name+"下载完成 {} MB".format('%.2f'%(size/1024/1024)))
return name
def get_fanname(url):
import base64
from lxml import etree
from urllib import request
'''
通用文字识别
'''
headers1 = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control':'no-cache',
'Host':'www.zzzfun.com',
'Pragma':'no-cache',
'Proxy-Connection':'keep-alive',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
try:
r = requests.get(url,verify=False)
# print(r.text)
html = etree.HTML(r.text)
fan_name_url = html.xpath('//div[@class="content-head"]/h1/img/@src')[0]
r = requests.get(fan_name_url,headers=headers1)
with open('test01.png','wb')as f:
f.write(r.content)
API_KEY = 'YjFCLAs18FFeEX92gtEonpGb'
SECRET_KEY = 'vdYTKGuK12p4gVdF5dc8C2kp3PyY8T6k'
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(API_KEY,SECRET_KEY)
response = requests.get(host ,verify=False)
if response:
js = json.loads(response.text)
access_token = js['access_token']
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
# 二进制方式打开图片文件
f = open(r'test01.png', 'rb')
img = base64.b64encode(f.read())
f.close()
os.remove('test01.png')
params = {"image":img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, verify=False,data=params, headers=headers)
if response:
js = json.loads(response.text)
name = js['words_result'][0]['words']
name = re.sub('[:/"",*‘’]','',name)
return name
except Exception as e:
print(e)
name = '番剧'
return name
if __name__ == '__main__':
global fanju_name
start = time.time()
url = input("请输入番剧链接:")
fanju_name = get_fanname(url)
print("您正在下载的番剧为:"+fanju_name)
print("*"*30+"下载开始"+"*"*30)
if not os.path.exists(fanju_name):
os.mkdir(fanju_name)
get_urls_to_download(url)
end = time.time()
print("*"*30+"下载结束"+"*"*30)
print("耗时{}分钟".format(str('%.2f'%((end-start)/60))))
多线程版:
import re,requests
import requests,json
import urllib3,os,time
from concurrent.futures import ThreadPoolExecutor
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
headers = {
'Host':'p1.pstatp.com',
'Connection':'keep-alive',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36',
'Origin':'http://www.zzzfun.com'
}
def get_urls_to_download(url):
r = requests.get(url)
# print(r.text)
urls = [ 'http://www.zzzfun.com/'+ i for i in re.findall('vod_play_.*?html',r.text)[1:]]
urls = urls[:(len(urls)//2)]
global num
num = len(urls)
id = re.search('_id_(.*?).',url).group(1)
get_m3u8 = ['http://www.zzzfun.com/static/danmu/bed-bofang.php?{}/{:0>2d}.m3u8'.format(id,i+1) for i in range(num)]
write_slices(get_m3u8)
pool = ThreadPoolExecutor(num)
for i in range(num):
line_uls = []
name = '第{:0>2d}话.m3u8'.format(i+1)
with open(name,'r')as f:
lines = f.readlines()
for line in lines:
if 'http' in line:
line_ul = line.replace('
','')
line_uls.append(line_ul)
pool.submit(download_m3u8,i,line_uls)
os.remove(name)
pool.shutdown(wait=True)
def write_slices(urls):
for i in range(num):
r = requests.get(urls[i])
r.close()
ul = re.search('http://service.*?m3u8',r.text).group(0)
r = requests.get(ul,verify=False)
r.close()
with open('第{:0>2d}话.m3u8'.format(i+1),'wb')as f:
f.write(r.content)
f.close()
def download_m3u8(i,line_uls):
name = '第{:0>2d}话'.format(i+1)
size = 0
print(name+"正在下载中")
for ur in line_uls:
headers.update({'Host':ur.split('/')[2]})
r = requests.get(ur,headers=headers,verify=False)
size = size + int(r.headers.get('content-length',0))
with open('./{}/'.format(fanju_name)+name+'.mp4','ab')as f:
f.write(r.content)
print(name+"下载完成 {} MB".format(str('%.2f'%(size/1024/1024) )))
return name
def get_fanname(url):
import base64
from lxml import etree
from urllib import request
headers1 = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control':'no-cache',
'Host':'www.zzzfun.com',
'Pragma':'no-cache',
'Proxy-Connection':'keep-alive',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
'''
通用文字识别
'''
try:
r = requests.get(url)
# print(r.text)
html = etree.HTML(r.text)
fan_name_url = html.xpath('//div[@class="content-head"]/h1/img/@src')[0]
r = requests.get(fan_name_url,headers=headers1)
with open('test01.png','wb')as f:
f.write(r.content)
API_KEY = 'YjFCLAs18FFeEX92gtEonpGb'
SECRET_KEY = 'vdYTKGuK12p4gVdF5dc8C2kp3PyY8T6k'
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(API_KEY,SECRET_KEY)
response = requests.get(host,verify=False)
if response:
js = json.loads(response.text)
access_token = js['access_token']
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
# 二进制方式打开图片文件
f = open(r'test01.png', 'rb')
img = base64.b64encode(f.read())
f.close()
os.remove('test01.png')
params = {"image":img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params,verify=False, headers=headers)
if response:
js = json.loads(response.text)
name = js['words_result'][0]['words']
name = re.sub('[:/"",*‘’]','',name)
return name
except Exception as e:
print(e)
name = '番剧'
return name
if __name__ == '__main__':
global fanju_name
start = time.time()
url = input("请输入番剧链接:")
fanju_name = get_fanname(url)
print("您正在下载的番剧为:"+fanju_name)
print("*"*30+"下载开始"+"*"*30)
if not os.path.exists(fanju_name):
os.mkdir(fanju_name)
get_urls_to_download(url)
end =time.time()
print("*"*30+"下载结束"+"*"*30)
print("耗时{}分钟".format(str('%.2f'%((end-start)/60))))
参考:https://blog.csdn.net/qq_44700693/article/details/109924262