Grep案例
1. 创建在hadoop-2.7.2文件下面创建一个input文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir input
2. 将Hadoop的xml配置文件复制到input
[atguigu@hadoop101 hadoop-2.7.2]$ cp etc/hadoop/*.xml input

3. 执行share目录下的MapReduce程序(执行)
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'(要正常的运行,必须要保证output删除,没有才能运行)

4. 查看输出结果
[atguigu@hadoop101 hadoop-2.7.2]$ cat output/*

WordCount案例
1. 创建在hadoop-2.7.2文件下面创建一个wcinput文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir wcinput
2. 在wcinput文件下创建一个wc.input文件
[atguigu@hadoop101 hadoop-2.7.2]$ cd wcinput
[atguigu@hadoop101 wcinput]$ touch wc.input
3. 编辑wc.input文件
[atguigu@hadoop101 wcinput]$ vi wc.input
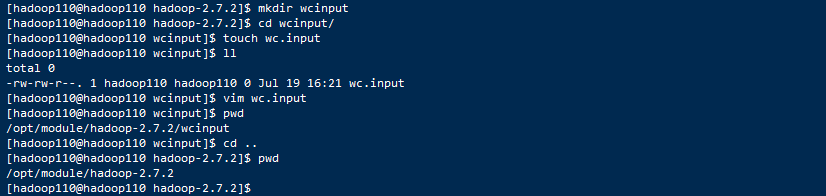
保存退出::wq
4. 回到Hadoop目录/opt/module/hadoop-2.7.2
5. 执行程序
[atguigu@hadoop101 hadoop-2.7.2]$ hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput

6. 查看结果
[atguigu@hadoop101 hadoop-2.7.2]$ cat wcoutput/part-r-00000
