一、主从读写分离的概念
1、什么是主从读写分离?
一般而言,应用APP对数据库都是“读多写少”,意味着数据库的读取压力比较大。为了解决这个问题,有一个方案就是说采用数据库集群,其中一台是主库,专门负责写入数据,我们称之为“写库”;其它都是从库,负责读取查询数据,我们称之为“读库”;
2、主从读写分离,对数据库的要求,有以下几点:
- 读库和写库的数据一致;
- 写数据必须写到写库;
- 读数据必须到读库
二、实现方案
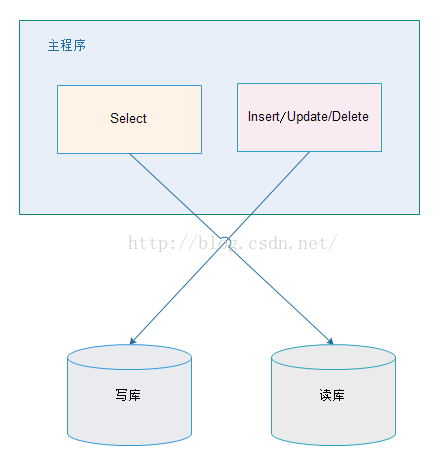
1、在应用层增加逻辑,实现主从读写分离
在编写业务逻辑时,根据查询、修改的业务类型,主动地设置去访问不同的数据源。
(1)优点:
- 多数据源切换方便,由程序自动完成;
- 不需要引入中间件;
- 理论上支持任何数据库;
(2)缺点:
- 由程序员完成,运维参与不到;
- 不能做到动态增加数据源;
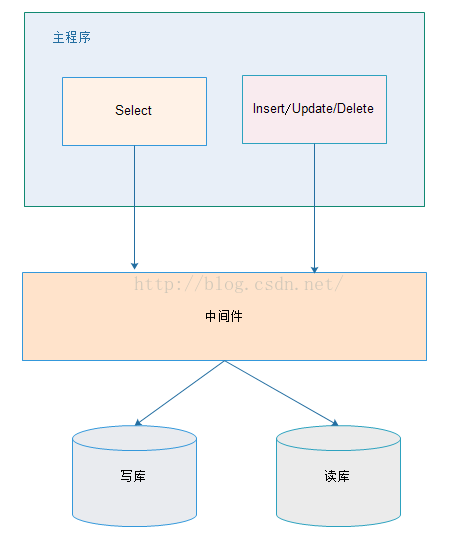
2、使用第三方中间件,由中间件来控制读写分离
使用第三方中间件控制的方式,对应用程序而言,相当于访问一个数据源。
(1)优点:
- 源程序不需要做任何改动就可以实现读写分离;
- 动态添加数据源不需要重启程序;
(2)缺点:
- 程序依赖于中间件,会导致切换数据库变得困难;
- 由中间件做了中转代理,性能有所下降;
注:以上内容转载自网络
原文标题:使用java Spring实现读写分离( MySQL实现主从复制)
原文地址:https://blog.csdn.net/liu976180578/article/details/77684583
三、项目实战
推荐阅读:主从读写实现:方法名前缀方式、数据库策略方式、一主多从方式
实现原理:
在开始编码前,统一service层方法名的命名规则,比如,查询类型的方法统一前缀为"query、search、find、get",而其他前缀的方法统一认定为是修改操作。每次接收到请求时,在执行service层的方法前,通过切面的方式获取要执行方法的名称,判读方法名称的前缀是否为"query、search、find、get",如果是,则设置数据源为从库;如果不是,则设置数据源为主库。从而实现主从读写分离。
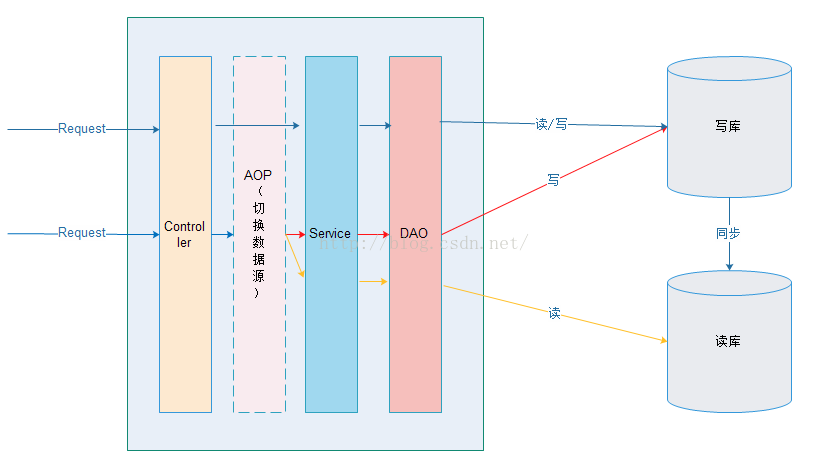
步骤一:首先,在项目中实现多数据源访问的功能。
实现方式,可参考以下资源:
【原创】SSM框架(2):多数据源支持,动态配置依赖的数据源
步骤二:定义切面DataSourceAspect,植入到service层方法之中
package com.newbie.util.dbReadWriteSeparation; import com.newbie.util.dbMultipleRouting.DynamicDataSourceHolder; import org.aspectj.lang.JoinPoint; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Before; import org.springframework.stereotype.Component; import java.util.ArrayList; import java.util.Iterator; import java.util.List; /** * 定义数据源的AOP切面,通过该Service的方法名判断是应该走读库还是写库 */ @Component @Aspect public class DataSourceAspect { /** * 定义切面植入的增强功能:在service对象的方法执行前,进行切入 * @param joinpoint : 切面对象 */ @Before("execution(* *..service.*.*(..))") public void before(JoinPoint joinpoint){ String methodName = joinpoint.getSignature().getName(); //根据方法名称的前缀,判断是否是查询方法 //如果是查询方法,则使用从库;否则,使用主库 if(isSlaveMethod(methodName)){ //标记为从库 DynamicDataSourceHolder.setDataSourceKey("slave1"); }else { //标记为主库 DynamicDataSourceHolder.setDataSourceKey("master"); } } /** * 根据方法名称的前缀,判断是否是查询方法 * @param methodName : 方法名称 * @return true :是查询方法<br/> * false : 不是查询方法 */ public boolean isSlaveMethod(String methodName){ if(methodName == null){ return false; } //遍历方式,判断方法的前缀 List<String> methodPrefix = new ArrayList<String>(); methodPrefix.add("query"); methodPrefix.add("search"); methodPrefix.add("find"); methodPrefix.add("get"); Iterator<String> iterator = methodPrefix.iterator(); while (iterator.hasNext()){ String prefixName = iterator.next(); if(methodName.startsWith(prefixName)){ return true; } } return false; } }
步骤三、编写service层的业务逻辑
package com.newbie.service.impl; import com.newbie.dao.UserMapper; import com.newbie.domain.User; import com.newbie.service.IReadWriteSeparationService; import com.newbie.util.dbMultipleRouting.DynamicDataSourceHolder; import org.springframework.stereotype.Service; import javax.annotation.Resource; import java.util.Iterator; import java.util.List; /** * 主从读写分离的实现 */ @Service public class ReadWriteSeparationService implements IReadWriteSeparationService { @Resource private UserMapper userMapper; /** * 向主库增加一个用户 */ public String insertOneUser() { String message = "插入完成"; message += "<p>当前线程数据源:key = "+ DynamicDataSourceHolder.getDataSourceKey()+"</p>"; User user = new User(); String id = String.valueOf(System.currentTimeMillis()); user.setId(id); user.setUsername("我是新插入的用户"); userMapper.insertSelective(user); return message; } /** * 使用非query方法,会被认为是修改类操作,查询主库数据 * @return */ public String notQueryAllUser() { String message = "<p>查询成功<p>"; message += "<p>当前线程数据源:key = "+ DynamicDataSourceHolder.getDataSourceKey()+"</p>"; //查询数据库中的所有用户信息 List<User> users = userMapper.selectByExample(null); Iterator<User> iterator = users.iterator(); while (iterator.hasNext()){ User user = iterator.next(); message += "<p>用户ID : "+user.getId()+" , 用户名 : "+user.getUsername()+" , 数据来源:"+user.getRemark()+"</p>"; } System.out.println("================== Service.notQueryAllUser() : 当前线程数据源 = "+DynamicDataSourceHolder.getDataSourceKey()); System.out.println("================== Service.notQueryAllUser() : 返回信息 = "+message); return message; } /** * 使用query方法,查询从库数据 * @return */ public String queryAllUser() { String message = "<p>查询成功<p>"; message += "<p>当前线程数据源:key = "+ DynamicDataSourceHolder.getDataSourceKey()+"</p>"; //查询数据库中的所有用户信息 List<User> users = userMapper.selectByExample(null); Iterator<User> iterator = users.iterator(); while (iterator.hasNext()){ User user = iterator.next(); message += "<p>用户ID : "+user.getId()+" , 用户名 : "+user.getUsername()+" , 数据来源:"+user.getRemark()+"</p>"; } System.out.println("================== Service.notQueryAllUser() : 当前线程数据源 = "+DynamicDataSourceHolder.getDataSourceKey()); System.out.println("================== Service.queryAllUser() : 返回信息 = "+message); return message; } }
步骤五、编写控制层Controller 和 测试视图
package com.newbie.controller; import com.newbie.service.IReadWriteSeparationService; import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.RequestMapping; import javax.annotation.Resource; /** * 测试:主从读写分离的实现 */ @Controller public class ReadWriteSeparationController { @Resource IReadWriteSeparationService readWriteSeparationService; /** * 向主库增加一个用户 */ @RequestMapping("/insertOneUser") public String insertOneUser(Model model) { String message = readWriteSeparationService.insertOneUser(); model.addAttribute("message", message); return "showInfo"; } /** * 使用非query方法,查询主库数据 */ @RequestMapping("/notQueryAllUser") public String notQueryAllUser(Model model) { String message = readWriteSeparationService.notQueryAllUser(); model.addAttribute("message", message); return "showInfo"; } /** * 使用query方法,查询从库数据 */ @RequestMapping("/queryAllUser") public String queryAllUser(Model model) { String message = readWriteSeparationService.queryAllUser(); model.addAttribute("message", message); return "showInfo"; } }
<%@ page contentType="text/html;charset=UTF-8" language="java" %> <html> <head> <title></title> </head> <body> <h2>练习三:实现主从读写分离</h2> <a href="insertOneUser">插入主库:向主库增加一个用户</a><br/><br/> <a href="queryAllUser">查询从库:使用query方法,查询从库数据</a><br/><br/> <a href="notQueryAllUser">查询主库(非正常操作):使用非query方法,查询主库数据</a><br/><br/> </body> </html>
步骤六、执行程序,观察结果


