索引的本质:是帮助Mysql高效获取数据的排好序的数据结构。
索引数据结构
- 二叉树
- 红黑树
- Hash表
- B-Tree

(1)、二叉树:存储数据的时候是一个链表,如果要查询0006的话要查询6次,如果是全表扫描的话也得查询6次。
弊端:二叉树的查询效率很低。
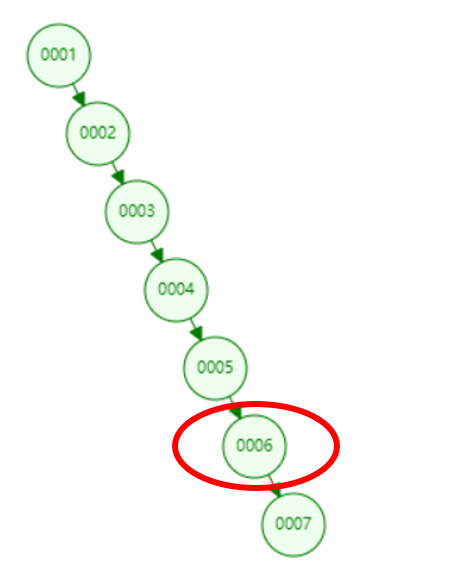
(2)、红黑树:存储数据的时候会自旋,如果要查询0006的话只需要查询3次。如果是全表扫描或二叉树查找的话需要6次,红黑树再二叉树的基础上查询效率提高了一半。
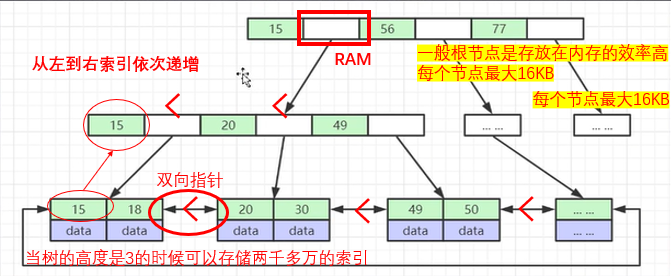
弊端:当数据量很大的时候(几百万或几千万),树的高度就会特别高,会存在多次磁盘IO操作影响其性能。解决以上的问题可以横向扩展,分配节点的时候分配的大一些,让其可以横向存储更多的索引元素。---- 此时B-Tree诞生了。

(3)、Hash: 对索引的key进行一次hash计算就可以定位出数据存储的位置,很多时候Hash索引要比B+树索引更高效。仅能满足“=”,“IN”,不支持范围查询。会存在hash冲突的问题。

为什么我们使用B+Tree比较多,使用hash比较少,是因为我们进行范围查询(select * from tabel where id > ***)的时候比较麻烦。
(4)、B-Tree:叶子节点具有相同的深度,叶子节点的指针为空;所有索引元素不重复;节点中的数据索引从左到右递增排列。
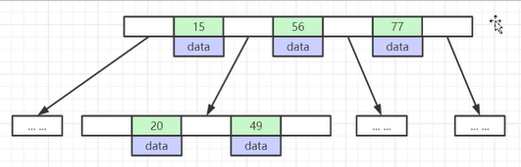
(5)、B+Tree(B-Tree变种):非叶子节点不存储data,只存储索引(冗余),可以放更多的索引;叶子节点包含所有索引字段;叶子节点用指针连接,提高区间访问的性能。
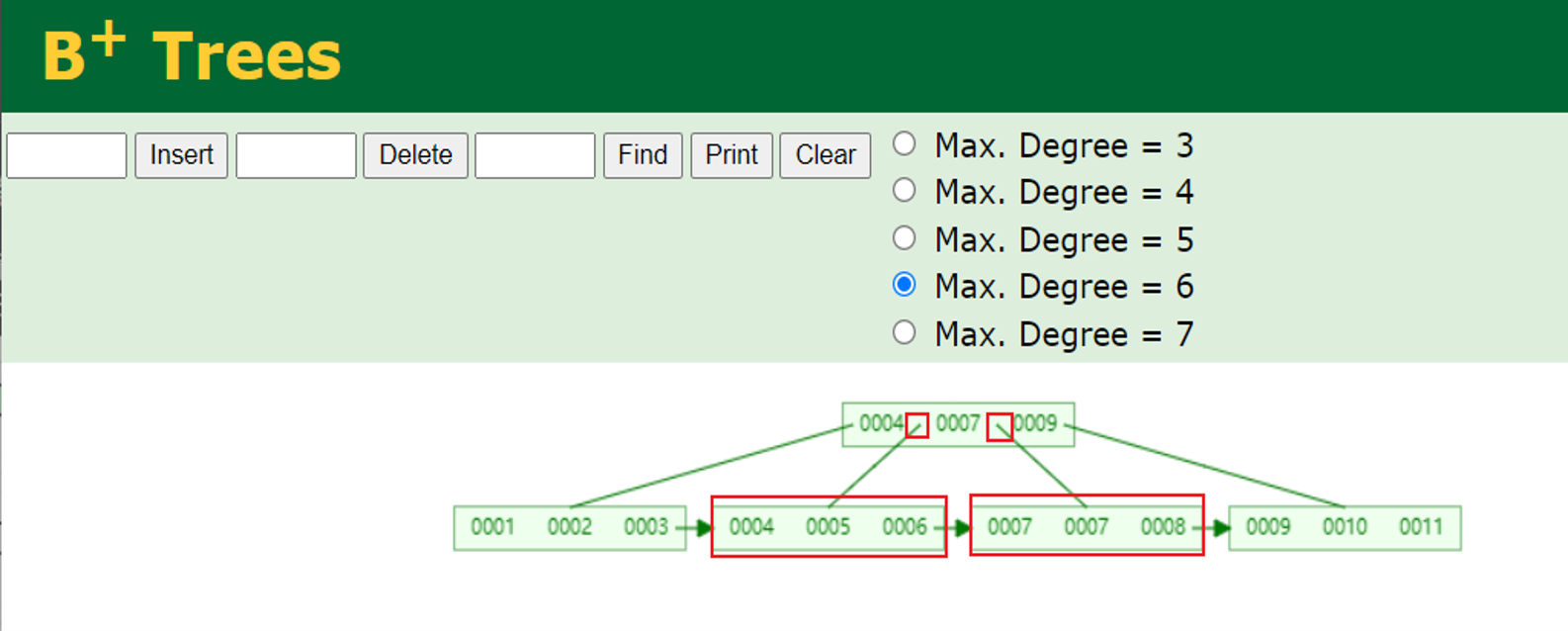
下面是关于存储引擎索引的实现:
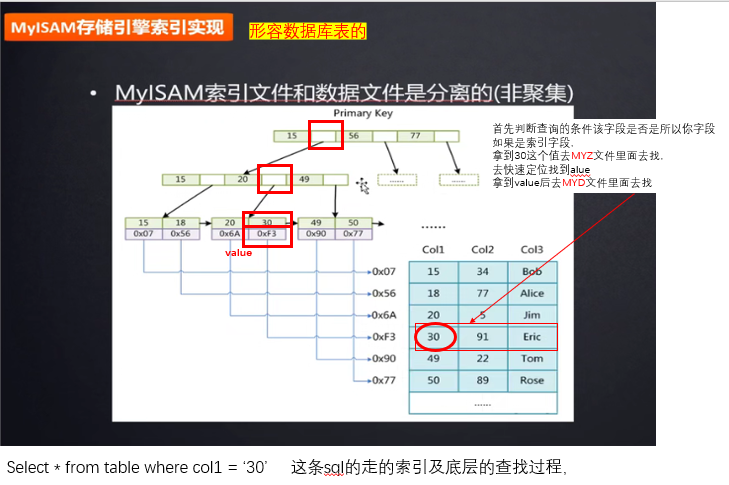

索引最左前缀原理:
- 联合索引的底层存储结构长什么样子?
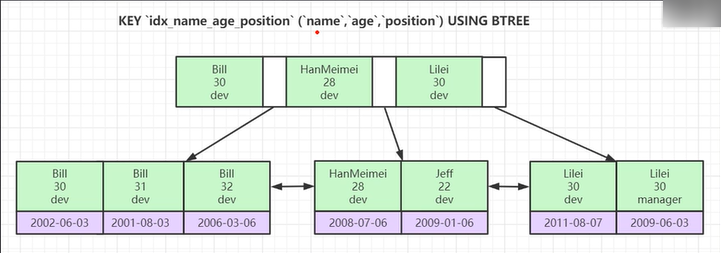
案例:最左前缀法则,(排好序),根据联合索引的字段顺序排好序。由于第2、3条sql没有name,不是排好序的。需要全表扫描。
