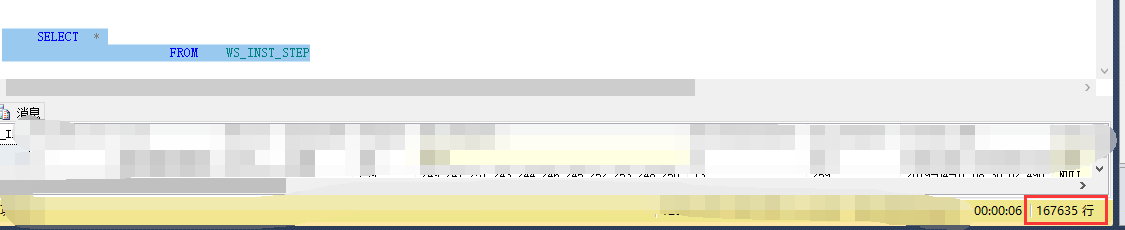
数据量:
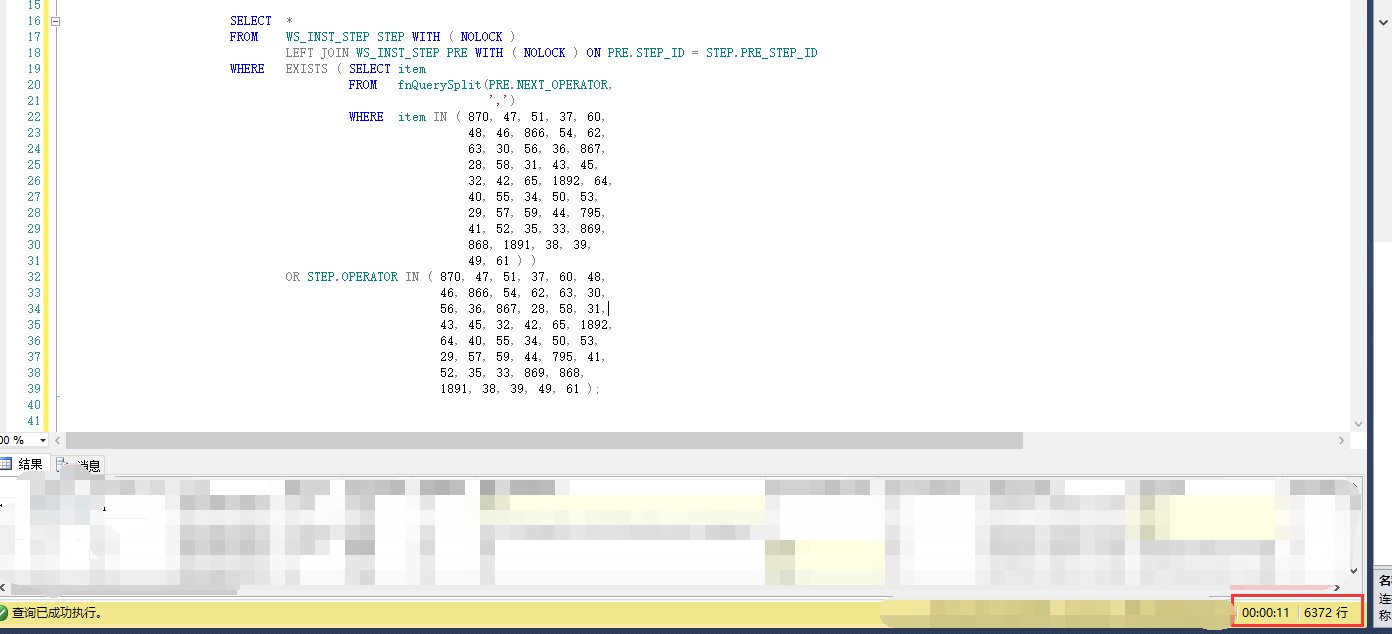
首先我们看看待优化的SQL:
简单的分析下来发现:
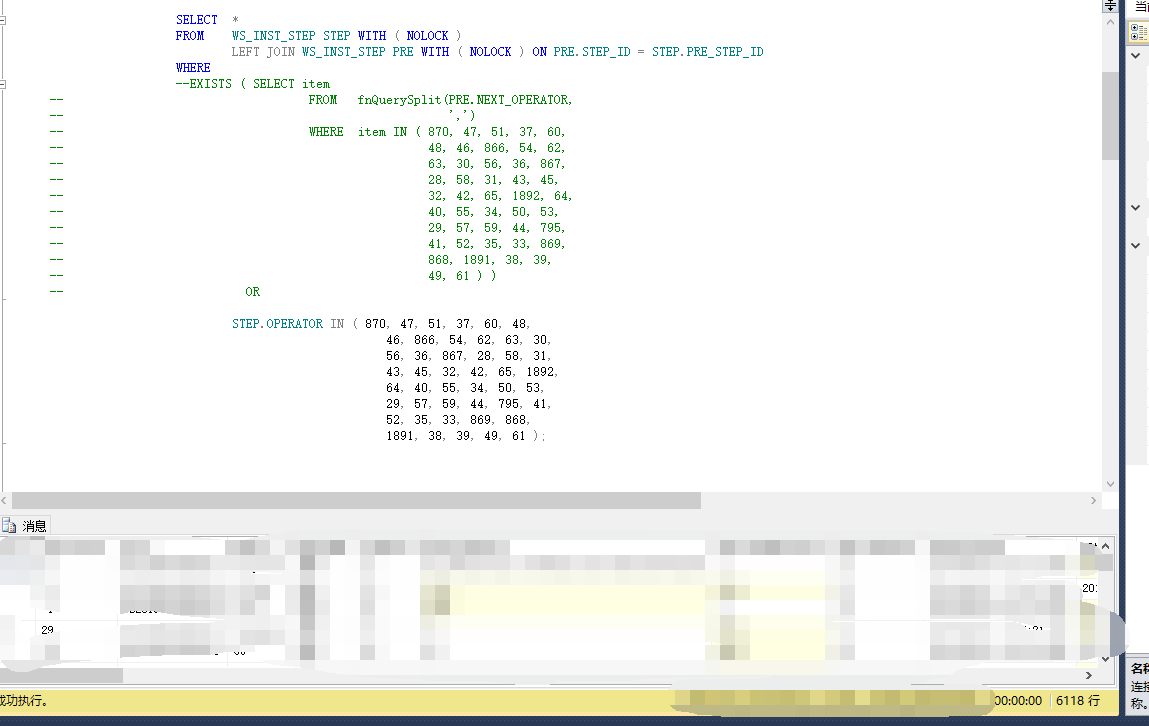
EXISTS 这部分执行比较慢,我们来看一下,

这种写法比较便于理解,但是执行起来却很慢。既然这里慢,我们就要优化这部分。
首先我是想把拼接的字段进行单条拆多条,开始的想法:
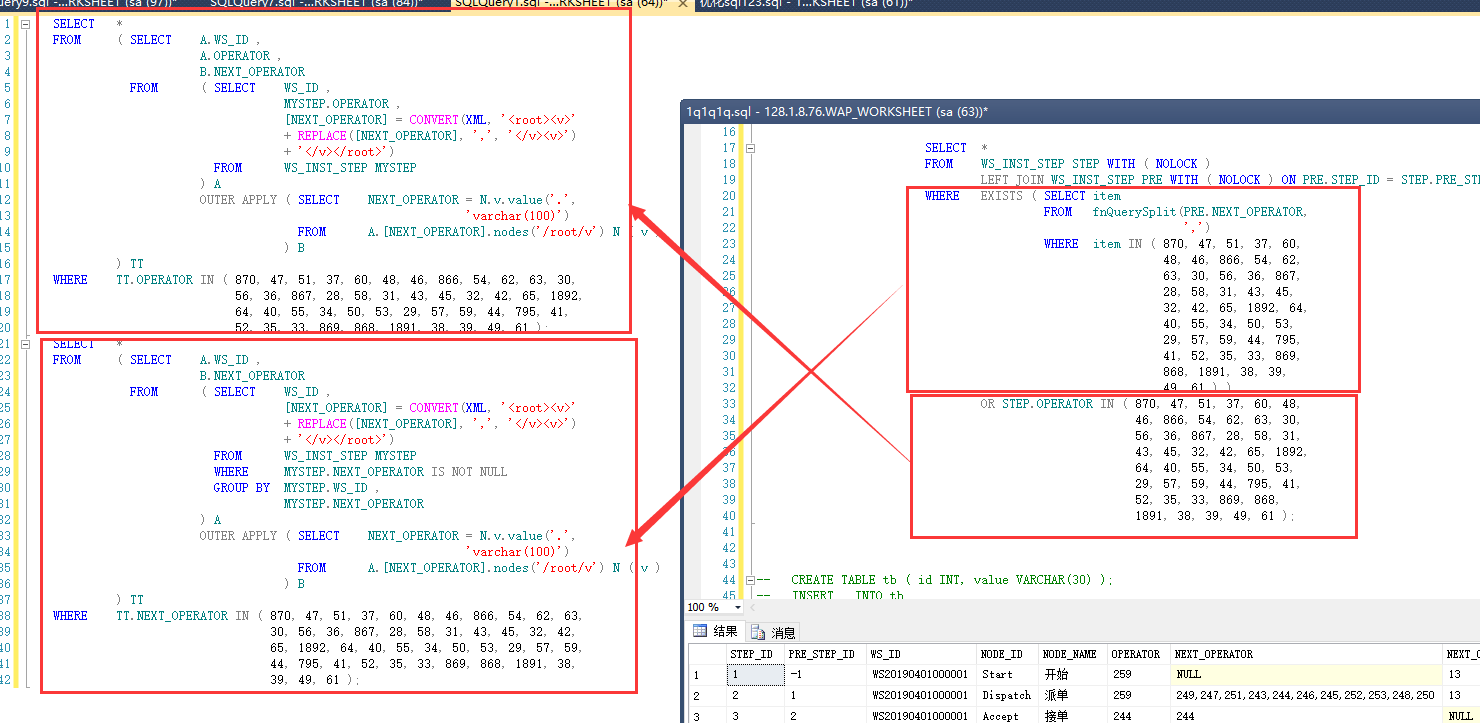
拆分后的第一个sql:

这个部分其实从开始就不是慢的原因,所以看第二个部分:
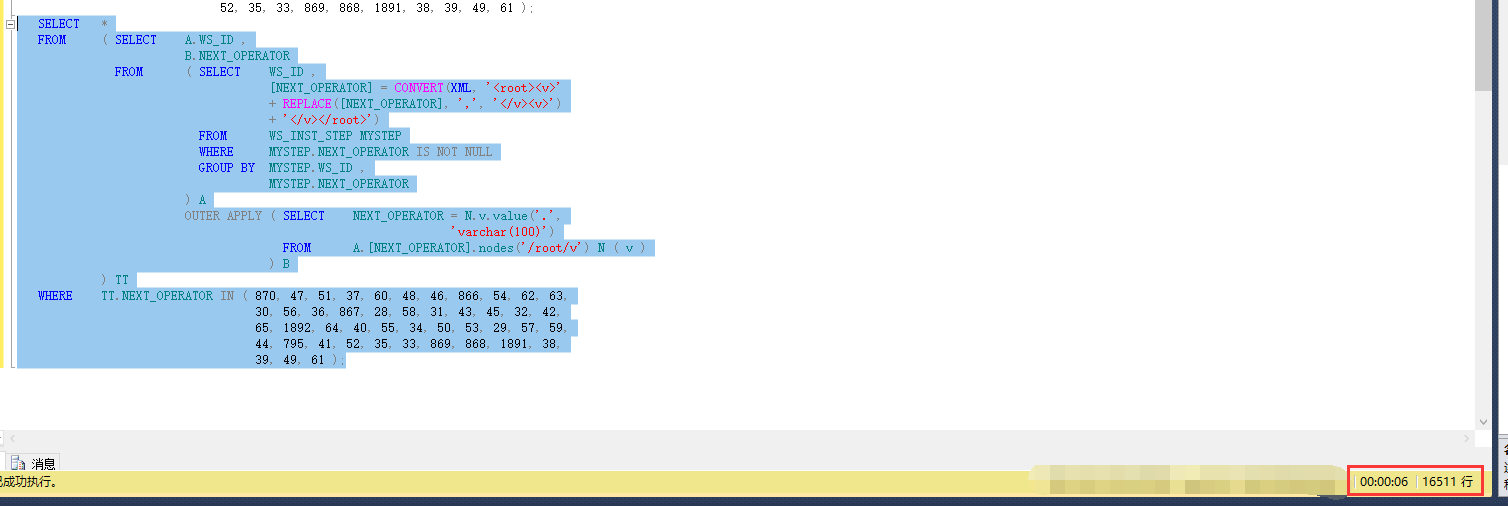
看一下效果,其实效果并不好。
后面请教了一下同事,一些什么缓存表啊啥的,都简单的测试过,其实并不适合。
后来同事指导下用了关联表如下:
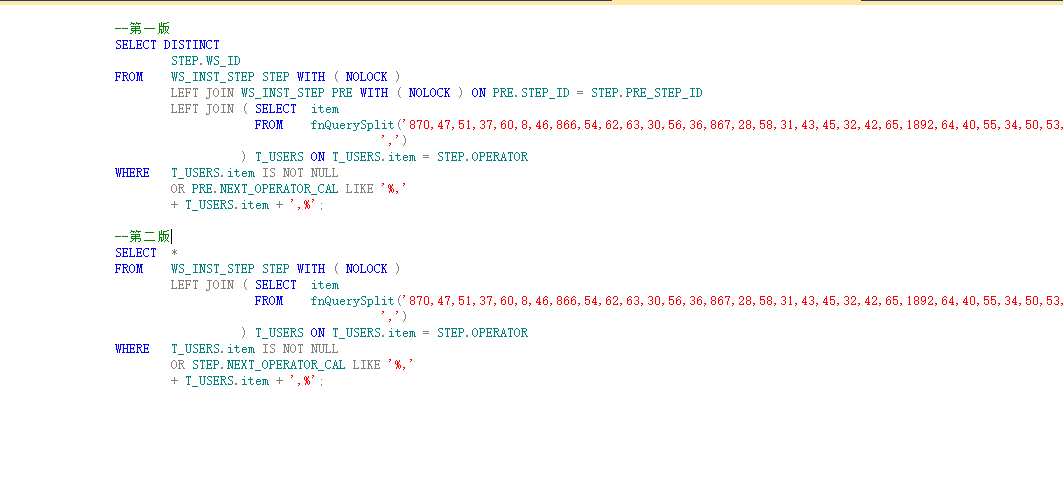
第一版是以前用了关联(WS_INST_STEP),后面根据需求,我把关联表部分去掉了。单独执行的化两个速度看不出来,我们放到整体sql中测试一下:


效果其实都还可以,宏观上相差1s。