一、常识
(一) 文件
linux中将每个进程上下文之外需要保存的信息保存在文件中。linux采用简单模式保存信息,即信息以单一字节序列从头保存到尾。 序列的字节长度就是文件的长度。
文件中保存了什么?文本信息,图片信息,二进制信息等。
(二) 字节
8个位为一组,称为字节。即一个字节包含8个比特(bit)。每个bit值域{0,1},8位一共可以有2^8个状态,即256。
(三) 数据编码
信息必须转换为字节的形式保存 ,也就是转成成0-255之间的一组数值。将信息转换成这种格式称为数据编码。
比如:图片由像素组成,而一个像素由(红,绿,蓝)三种颜色组成,而这三种颜色的每种颜色用一个字节组成,这样就把图片信息转换成0~255之间的数了。
(四) 文本编码
计算机中保存的最常见的数据形式是文本,文本有很多的编码技术。
ASCII:
它是最古老的,但也是最常用的文本编码。ASCII码由可打印字符,特殊字符,空白符,控制字符等组成。比如:65表示A,13表示回车,4表示文件结束等。
注意 :ASCII码只定义了0~127这128个字符。
ISO 8859及其它字符集:
对于256中后128个字符,不同字符集定义了不同的字符,比如:ISO 8859-1 是西欧语言。 ISO 8859-6 拉丁文等。
他们保留0-127,自己定义了128-255的编码方案。
UNICODE:
前面的编码方案有缺陷,不能容纳更多的编码。Unicode标准采用了4字节代表一个字符,也就是能表示2^32个字符,可以容纳40多亿个字符。
好处是可以保存更多的字符,坏处是造成空间的浪费。
UTF-8:
UTF-8采用变长编码,为了兼容性,传统的128个字符采用1个字节编码,后2000个最常用的采用2个字节编码,次之6300个字符采用3个字节编码,比较罕见的字符采用4-6个字节编码。但utf-8并不能兼容所有字符编码。
linux中默认的编码方案就是utf-8
(五) 国际化
国际化 internationalization,通常缩写为i18n。国际化的应用程序要考虑到语言的问题,在linux中大多数应用程序要求有LANG环境变量,以决定使用何种语言。
[linux@localhost ~]$ echo $LANG
zh_CN.UTF-8
[linux@localhost ~]$ cat /etc/shadow
cat: /etc/shadow: 权限不够
[linux@localhost ~]$ LANG=en_US.UTF-8
[linux@localhost ~]$ cat /etc/shadow
cat: /etc/shadow: Permission denied
[linux@localhost ~]$
我们查看LANG环境变量的值是zh_CN表示中文,cat一下密码文件提示权限不够,之后我们把语言切换到英文,再执行cat命令,以英文的方式显示。
这就说明,选择不同的语言,那么分类顺序,数字格式,文本编码等都会不同。
二、LANG环境变量
此变量用于定义用户的语言,默认的编码方案,格式如下:
LL_CC.enc
LL表示语言代码,如:zh表示汉语,en表示英语,de表示德语等。
CC表示国家代码,如:CN表示中国,US表示美国,FR表示法国等。
enc表示字符编码,如:UTF-8,ISO 8859-1等。
可以用:locale查看当前语言配置情况。
[linux@localhost ~]$ locale
LANG=zh_CN.UTF-8
LC_CTYPE="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
......
三、wc命令
wc命令用于统计字符,文字和行的数量。
wc [-c] [-l] [-w] filename
- -c 估算字符数
- -l 估算行数
- -w 估算字数
字符由各种符号组成,比如字母,数字,换行符之类。
字就是字符左右都有空白(空白:空格,制表符,换行符),计算机按这个计算,和语义没有关系。
例:统计字符数,行数,字数:
[linux@localhost ~]$ wc -c /etc/os-release
393 /etc/os-release
[linux@localhost ~]$ wc -l /etc/os-release
16 /etc/os-release
[linux@localhost ~]$ wc -w /etc/os-release
20 /etc/os-release
注意细节:
[linux@localhost ~]$ echo "a a" > a.txt
[linux@localhost ~]$ wc -c a.txt
4 a.txt
我们发现:两个字母a,但结果显示是4个字符,这里包括2个字母a,包括一个空格,包括一个换行符,所以总字符数是4个。 您可以试一下: echo -n "a a" > a.txt看看几个字符。
另外对于linux, Macintosh,windows他们对于换行的表示是不一样的。 linux用一个换行符表示,windows用回车符加换行符表示,Mac用回车表示。
例:
统计系统上有多少个用户?
[linux@localhost ~]$ wc -l /etc/passwd
21 /etc/passwd
统计当前系统中有多少个进程
[linux@localhost ~]$ ps aux | wc -l
124
四、grep命令
grep命令常用的形式是:
fgrep [option] pattern [filename]
grep [option] pattern [filename]
egrep [option] pattern [filename]
grep由三个名字组成的:
- fgrep 用于快速搜索简单模式
- grep 用于正则表达式搜索
- egrep 用于扩展正则表达式搜索
grep命令常用的选项
| 选项 | 说明 |
|---|---|
| -c | 仅打印包含模式行的数量 |
| -E 表达式 | 用于多个模式, grep -e "A|eee" |
| -i | 忽略大小写 |
| -l | 打印符合模式要求的文件名 |
| -n | 显示行数 |
| -q | 如果找到匹配,则返回值为0,不显示找到的内容 |
| -r | 递归搜索 |
| -w word | 仅包含word的行 |
| -v | 反转grep |
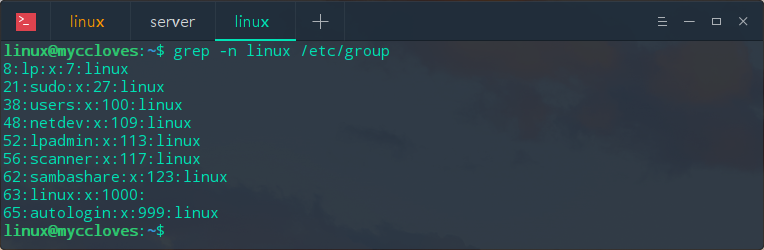
显示匹配的行
查看/etc/group中含有linux用户的行,并显示行号
一次搜索多个文件
linux@myccloves:~$ grep linux /etc/passwd /etc/group
/etc/passwd : linux : x : 1000 : 1000 :: /home/linux : /bin/bash
/etc/group : lp : x : 7 : linux
/etc/group : sudo : x : 27 : linux
如果不想看具体信息,只看具有匹配的文件名,加 -l 参数就可以了。
递归搜索
比如:想看/etc上所有的文件,如果发现eth0字样就打印出来,用-r表示递归搜索:
linux@myccloves:~$ grep -r eth0 /etc/ 2>/dev/null
/etc/dnsmasq.conf:# interface (eg eth0) here.
/etc/network/if-up.d/upstart: # Ignoring unknown interface eth0=eth0.
/etc/samba/smb.conf:; interfaces = 127.0.0.0/8 eth0
/etc/dhcp/dhclient.conf:# interface "eth0";
/etc/dhcp/dhclient.conf:# interface "eth0";
......
反转grep
比如:我们搜索/etc/passwd中,不包含linux的所有用户,用参数-v表示反转。
linux@myccloves:~$ grep -v linux /etc/passwd | head -2
root : x : 0 : 0 : root : /root : /bin/bash
daemon : x : 1 : 1 : daemon : /usr/sbin : /usr/sbin/nologin
其它选项参考上表。
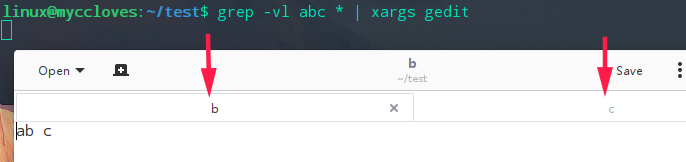
五、联合使用grep与xargs
假设有1,a,b,c四个文件,其中每个文件中都录入abc三个字母,但是其中有些文件录入的不是abc,我现在想要找出不是abc的,并且用gedit自动打开,之后手动修改。
linux@myccloves:~/test$ grep -v abc *
b:ab c
c:a bc
首先我们用-v选项查看一下不是abc的,结果:b文件,c文件不是abc,他们多了空格。 之后我想用gedit打开这几个文件,于是:
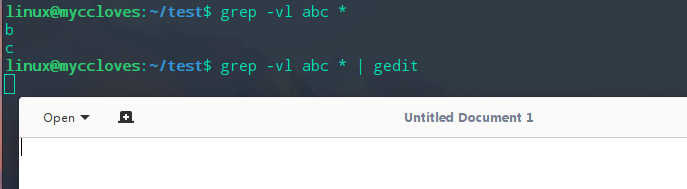
先用-l得到文件,之后重定向到gedit,但gedit并没有打开这几个文件,而是新创建一个文件。 gedit想要打开文件,必须把文件转换为gedit的参数,比如:gedit file1 file2等。
在linux中xargs就可以读取标准输入,并且把读取的数据附加到命令参数中。如: