1、巡检
YARN 为 Hadoop 集群的上层应用,包括 MapReduce、Spark 等计算服务在内,提供了统一的资源管理和调度服务。
每日早晚巡检YARN 服务,主要检查资源池内主机的健康状态,保障 YARN 服务可用性。
1.1、YARN CM 运行状态
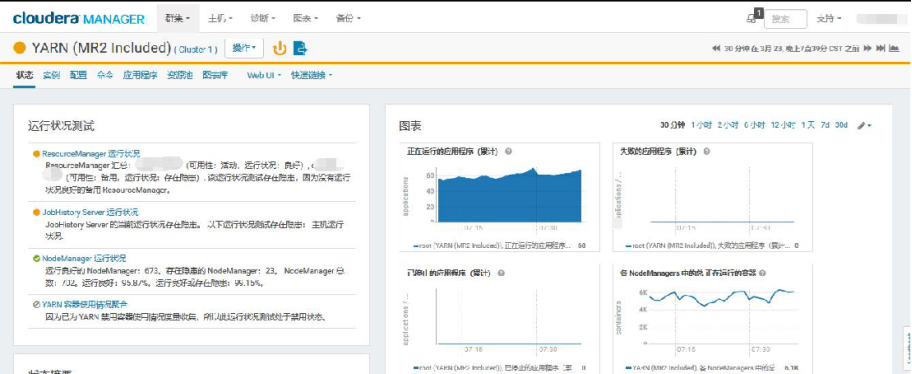
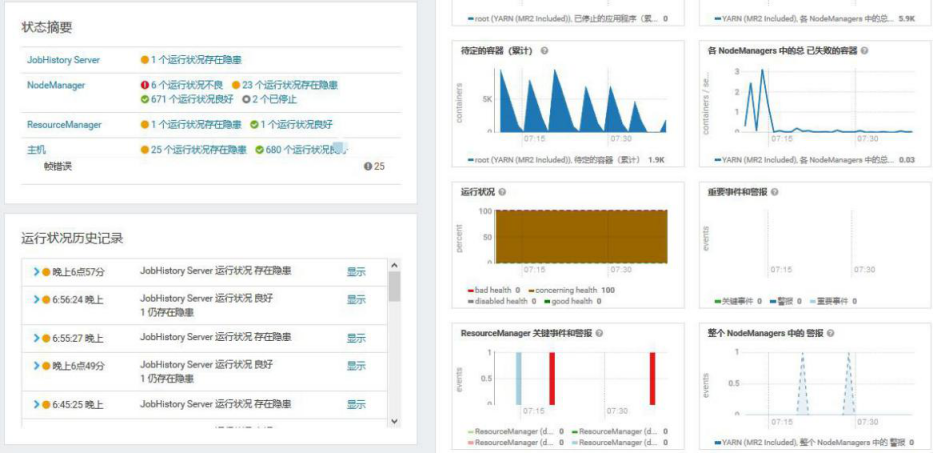
Yarn 集群,目前 Cloudera Manager 显示 6 个不良,16 个存在隐患
打开显示为不良的 NodeManager,这个节点有坏盘正在报修阶段
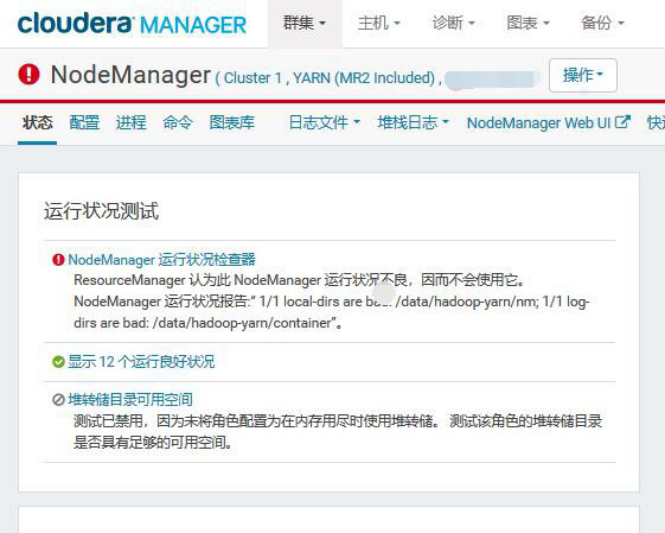
查看存在隐患的 NodeManager

查看正在运行的 Container 与总核数的差距
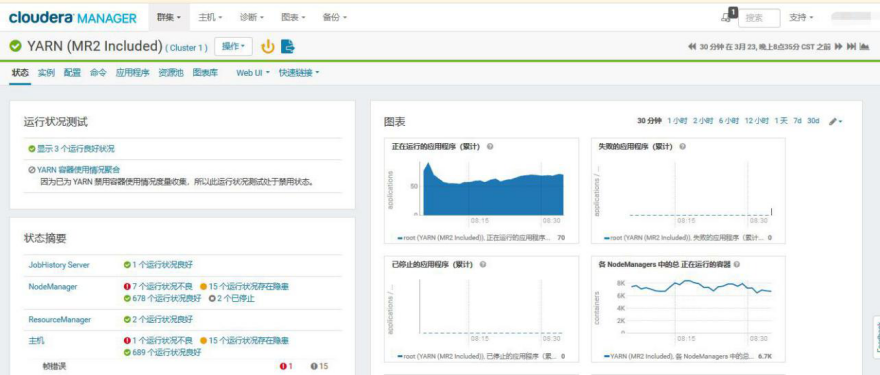
查看是否有大量失败的 Container,目前很少
查看 resourcemanager 高可用状态,良好
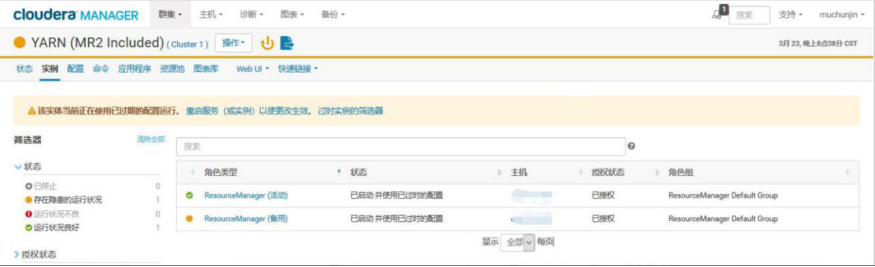
查看 resourcemanager 监控指标,内存充足,待定的 Container 持续负载不高
JVM 堆栈,没有异常
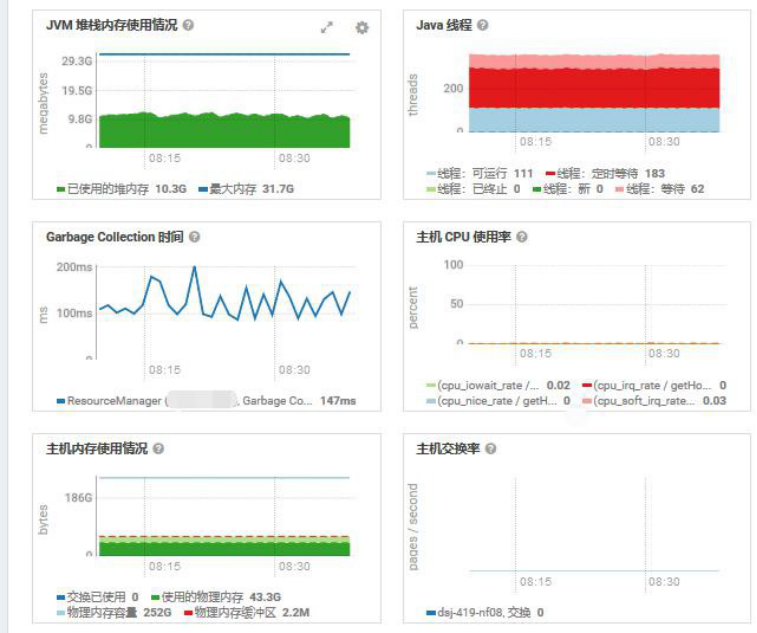
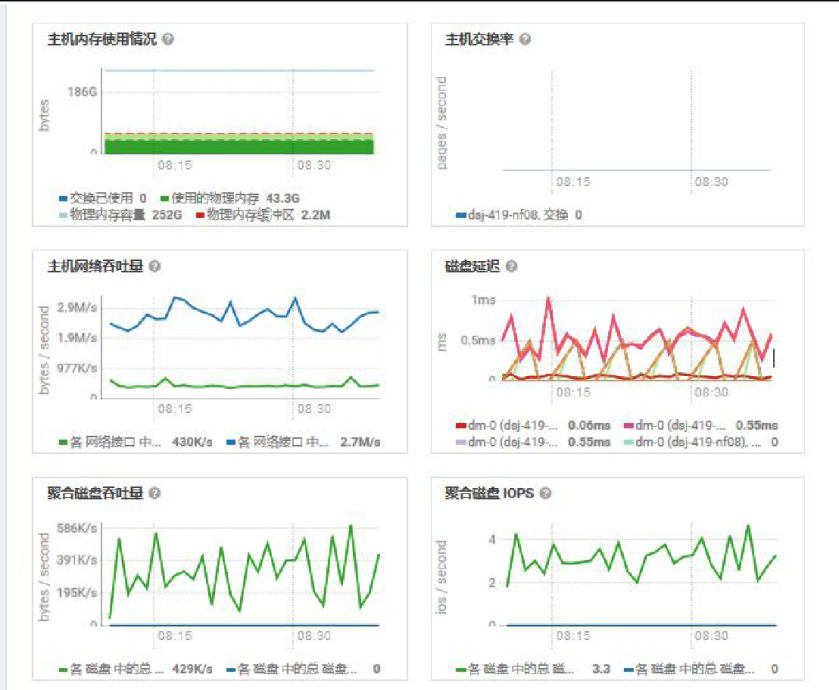
查看内存、磁盘情况,内存充足,磁盘延迟低
1.2、YARN WEB UI 运行状态
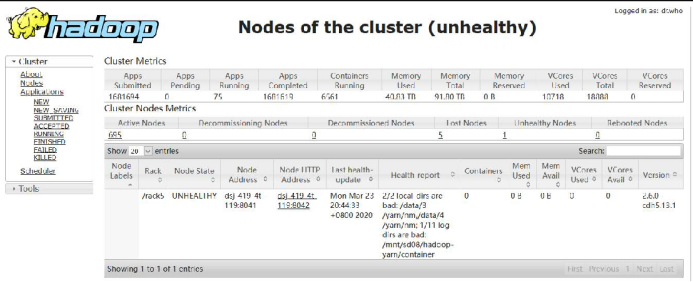
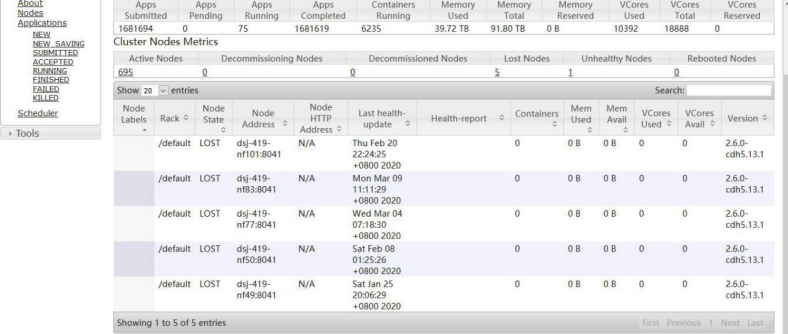
查看集群整体情况,发现 5 个 LOST 节点,1 个不健康节点

1 个不健康节点是有坏盘情况,已经进去报修阶段
5 个 Lost Nodes 是因为几个主机总是出问题以及 IAAS 测正在查看
查看资源队列资源使用情况,因为我是晚上 8 点截的图,是低峰期,所以使用资源不多
1.3、YARN/MR 关键性能指标
各个 NodeManager 的 GC 时间
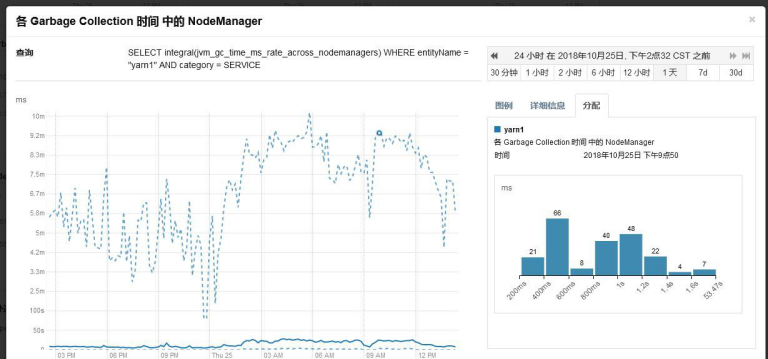
gc 时间基本在几 ms,gc 正常。
NodeManager 驻留内存
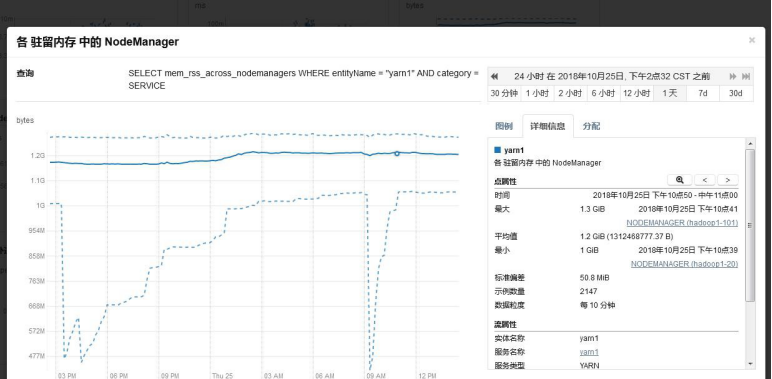
NodeManager 驻留内存为 1G 左右,因此建议提升 NodeManager 内存。
集群每秒完成的任务数
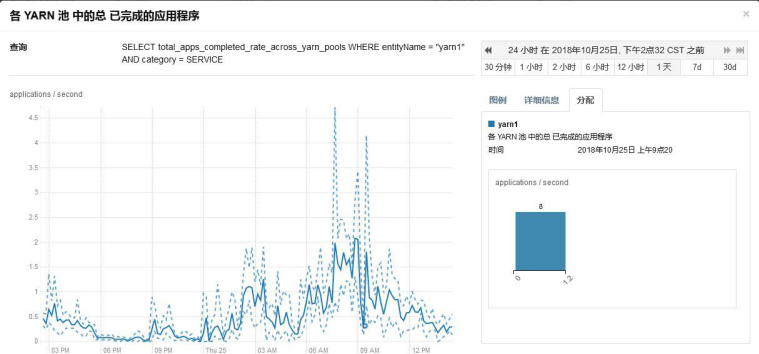
每秒完成 1.5 个任务。
1.3.1、存在问题
集群资源使用率较低
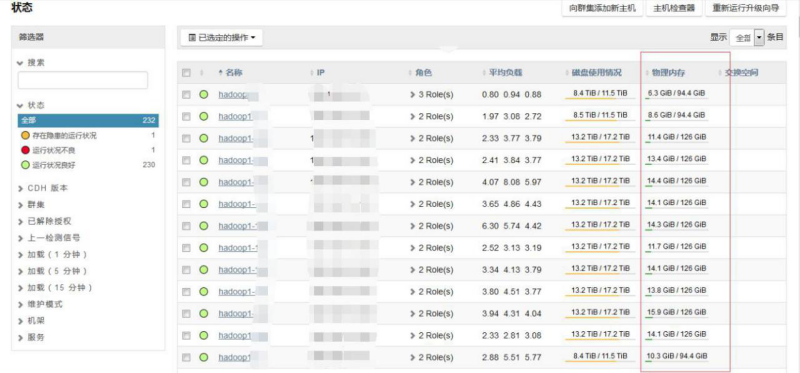
集群节点内存使用,节点普遍内存使用都只有 10G 左右。
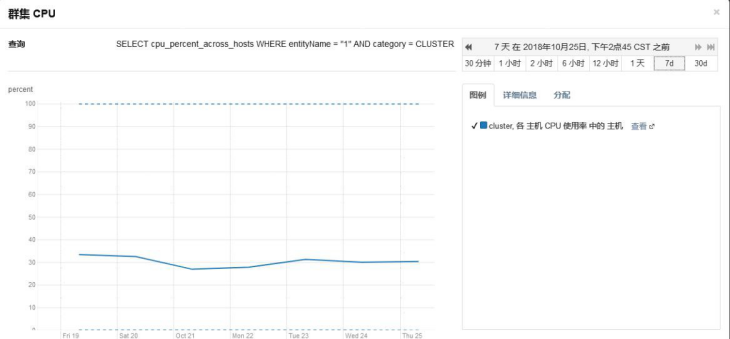
集群节点 CPU 平均使用率在 40%左右,不算很高。
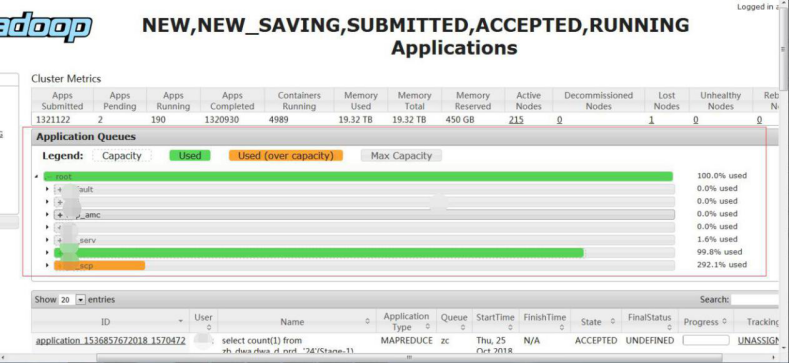
但是从 Yarn 的页面可以看到,Yarn 的集群使用率已经高达 100%
1.3.2、原因分析
Yarn 显示资源使用率达到 100%,而集群节点内存,CPU 等资源却使用不是很高。
Yarn 在配置时,通过设定每个 NodeManager 可以分配的 Container 内存, 以及 CPU,来设定每个节点的资源。目前每个 NodeManager 配置了 120G,CPU 配置了 32VCore。
目前集群可能存在的问题是,每个 Container 分配的资源过高,实际任务并不需要这么多资源,从而出现了资源被分配完,但是使用率低的情况。
1.3.3、建议方案
降低 Container 的内存分配,增加 Nodemanager 能够分配的 Vcore 数。配置如下:
1.Container 虚拟 CPU 内核yarn.nodemanager.resource.cpu-vcores: 48
2.Map 任务内存 mapreduce.map.memory: 1.5G
3.Reduce 任务内存 mapreduce.reduce.memory.mb 1.5G
4.Map 任务最大堆栈 mapreduce.map.java.opts.max.heap 1.2G
5.Reduce 任务最大堆栈 mapreduce.reduce.java.opts.max.heap 1.2G 不过注意,对于某些对于内存需求较高的任务,需要单独设定,保证不出现outofmemory 的情况。
2、参数调优
2.1、节点内存资源
yarn.nodemanager.resource.memory-mb
NodeManager 一般和 datanode 部署在一起,这些角色本身也要消耗内存, 并且操作系统也需要部分内存,建议 Container 内存可以适当降低,这些总的内存相加不能超过节点物理内存,我们给操作系统留 5G 以内的内存
2.2、节点虚拟 CPU 内核
yarn.nodemanager.resource.cpu-vcores
NodeManager 可以使用的核数,我们产线环境的核数配置的跟机器的核数是一致的
2.3、Container 最小分配内存
yarn.scheduler.minimum-allocation-mb
Container 最小内存定义了 Yarn 可以分配给 Container 最小资源,不管任务本身处理的数据量大小,都会至少分配这么多的内存,我们产线环境设置的是2G,从目前的监控上看内存资源是够用的,CPU 资源紧张
2.4、Container 最大分配内存
yarn.scheduler.maximum-allocation-mb
Container 最大可申请的内存,目前我们产线环境配置的是 32G,因为我们产线环境有 Spark 作业,Spark 同一个执行器可以跑多个任务,平分内存
2.5、资源规整化因子
yarn.scheduler.increment-allocation-mb 假如规整化因子 b=512M,上述讲的参数
yarn.scheduler.minimum-allocation-mb 为 1024, yarn.scheduler.maximum-allocation-mb 为 8096,然后我打算给单个 map 任务申请内存资源(mapreduce.map.memory.mb):
申请的资源为 a=1000M 时,实际 Container 最小内存大小为 1024M(小于yarn.scheduler.minimum-allocation-mb 的话自动设置为yarn.scheduler.minimum-allocation-mb);
申请的资源为 a=1500M 时,实际得到的 Container 内存大小为 1536M,计算公式为:ceiling(a/b)*b,即 ceiling(a/b)=ceiling(1500/512)=3,
3*512=1536。此处假如 b=1024,则 Container 实际内存大小为 2048M 也就是说 Container 实际内存大小最小为
yarn.scheduler.minimum-allocation-mb 值,然后增加时的最小增加量为规整化因子 b,最大不超过 yarn.scheduler.maximum-allocation-mb
当使用 capacity scheduler 或者 fifo scheduler 时,规整化因子指的就是参数yarn.scheduler.minimum-allocation-mb,不能单独配置,即yarn.scheduler.increment-allocation-mb 无作用;
当使用 fair scheduler 时,规整化因子指的是参数yarn.scheduler.increment-allocation-mb
我们产线环境设置的是 512M
2.6、Container 最小虚拟 CPU 内核数量
yarn.scheduler.minimum-allocation-vcores 产线环境配置的为 1
2.7、最大Container 虚拟 CPU 内核数量
yarn.scheduler.maximum-allocation-vcores 我们的产线环境配置的是 12
2.8、MapReduce ApplicationMaster 的内存
yarn.app.mapreduce.am.resource.mb
我们产线环境设置的是 2G,2G 基本够用了,如果有特殊情况,可以酌情改大
2.9、ApplicationMaster Java 最大堆栈
通常是 yarn.app.mapreduce.am.resource.mb 的 80%,1.6G
2.10、Map 任务内存
mapreduce.map.memory.mb
Map 任务申请的内存大小,产线环境设置的是 2G,一般有作业覆盖
2.11、Reduce 任务内存
mapreduce.reduce.memory.mb
Reduce 任务申请的内容大小,产线环境设置的是 2G,一般有作业覆盖
2.12、Map 和Reduce 堆栈内存
mapreduce.map.java.opts、mapreduce.reduce.java.opts
以 map 任务为例,Container 其实就是在执行一个脚本文件,而脚本文件中, 会执行一个 Java 的子进程,这个子进程就是真正的 Map Task,mapreduce.map.java.opts 其实就是启动 JVM 虚拟机时,传递给虚拟机的启动参数,表示这个 Java 程序可以使用的最大堆内存数,一旦超过这个大小,JVM 就会抛出 Out of Memory 异常,并终止进程。而mapreduce.map.memory.mb 设置的是 Container 的内存上限,这个参数由 NodeManager 读取并进行控制,当 Container 的内存大小超过了这个参数值,NodeManager 会负责 kill 掉 Container。在后面分析yarn.nodemanager.vmem-pmem-ratio 这个参数的时候,会讲解NodeManager 监控 Container 内存(包括虚拟内存和物理内存)及 kill 掉Container 的过程。就是说,mapreduce.map.java.opts 一定要小于mapreduce.map.memory.mbmapreduce.reduce.java.opts 同 mapreduce.map.java.opts 一样的道理。默认是 mapreduce.map.memory.mb 和 mapreduce.reduce.memory.mb 的 80%
2.13、ResourceManager 的 Java 堆栈大小
产线环境配置的是 32G,-Xmx32768m 产线环境使用了 16G
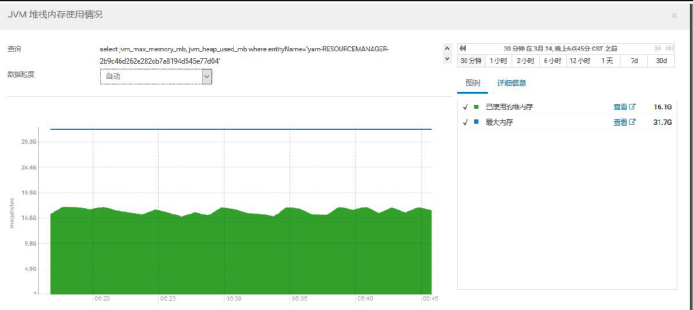
2.14、NodeManager 的 Java 堆栈大小
产线环境配置的是 1G,-Xmx1024m
对于节点数较大,并且处理任务较多的集群,NodeManager 的内存可以相应设置的充裕一些,比如 2G-4G

2.15、Reduce 任务前要完成的 Map 任务数量
mapreduce.job.reduce.slowstart.completedmaps
该参数决定了 Map 阶段完成多少比例之后,开始进行 Reduce 阶段,如果集群空闲资源较多,该参数可以设置的比较小,如果资源紧张,建议可以设置的更大,由 0.8 改为 0.95
2.16、Hive 参数汇总
1.组合参数优化:减少 map 数
是否支持可切分的CombineInputFormat 合并输入小文件此参数必须加否则不生效
set hive.hadoop.supports.splittable.combineinputformat=true;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFor mat;
一个节点上 split 的至少的大小
set mapred.max.split.size=1073741824;
一个交换机下 split 至少的大小
set mapred.min.split.size.per.node=1073741824;
2.组合参数优化:调整 reduce 输出大小,降低 reduce 数,降低小文件输出
强制指定 reduce 的任务数量,可以设置这个参数,如果不确定忽略此参数, 用下面的两个参数
mapred.reduce.tasks=${num}
reduce 最大个数
set hive.exec.reduceRegionServer.max=300;
每个 reduce 任务处理的数据量,一般设置为 2G, 2G = 2147483648 Bytes
set hive.exec.reduceRegionServer.bytes.per.reducer=2147483648;
hive.exec.reduceRegionServer.bytes.per.reducer 67108864 默认值是64M
3.优化小文件问题
在 Map-only 的任务结束时启用合并小文件set hive.merge.mapfiles=true;
在 Map-Reduce 的任务结束时启用合并小文件set hive.merge.mapredfiles=true;
当输出文件的平均大小小于该值时,启动一个独立的 map-reduce 任务进行文件 merge
set hive.merge.smallfiles.avgsize=1073741824;
合并后文件的大小为 1GB 左右
set hive.merge.size.per.task=1073741824;
4.container 内存大小
map 内存
set mapreduce.map.memory.mb=2048; 集群最小值是 2048M,与
mapreduce.map.memory.mb/mapred.max.split.size 比例是 2:1
reduce
set mapreduce.reduce.memory.mb=4096;与hive.exec.reduceRegionServer.bytes.per.reducer 参数比例 1:1~1:2
set mapred.child.java.opts=-Xmx3481m;确认集群与 mapreduce.map.memory.mb 的关系
5.作业通用参数
job 名
set mapreduce.job.name=P_DWA_D_IA_test;
队列名
set mapreduce.job.queuename=ia;
3、运维
3.1、运维命令
3.1.1、application
yarn application [options]
-list
#列出 RM 中的应用程序。支持使用-appTypes 来根据应用程序类型过滤应用程序,并支持使用-appStates 来根据应用程序状态过滤应用程序。
-kill <ApplicationId>
#终止应用程序。
-status <ApplicationId>
#打印应用程序的状态。
-appStates <States>
#与-list 一起使用,可根据输入的逗号分隔的应用程序状态列表来过滤应用程序。有效的应用程序状态可以是以下之一: ALL,NEW,NEW_SAVING,SUBMITTED,ACCEPTED,RUNNING, FINISHED,FAILED,KILLED
-appTypes <Types>
#与-list 一起使用,可以根据输入的逗号分隔的应用程序类型列表来过滤应用程序。
3.1.2、applicationattempt
yarn applicationattempt [options]
-help #帮助
-list <ApplicationId> #获取到应用程序尝试的列表,其返回值ApplicationAttempt-Id 等于 <Application Attempt Id>
-status <Application Attempt Id> #打印应用程序尝试的状态。
3.1.3、classpath
yarn classpath
#打印需要得到 Hadoop 的 jar 和所需要的 lib 包路径
3.1.4、container
yarn container [options]
#打印 container(s)的报告
-help #帮助
-list <Application Attempt Id> #应用程序尝试的ContaineRegionServer 列表
-status <ContainerId> #打印 Container 的状态
3.1.5、logs
yarn logs -applicationId <application ID> [options] #转存container 的日志。
复制代码
-applicationId <application ID> #指定应用程序 ID,应用程序的 ID 可以在 yarn.resourcemanager.webapp.address 配置的路径查看(即:ID)
-appOwner <AppOwner> #应用的所有者(如果没有指定就是当前用户)应用程序的 ID 可以在 yarn.resourcemanager.webapp.address 配置的路径查看(即:User)
-containerId <ContainerId> #Container Id
-help #帮助
-nodeAddress <NodeAddress> # 节点地址的格式:nodename:port(端口是配置文件中:yarn.nodemanager.webapp.address 参数指定)
3.1.6、node
yarn node [options]
#打印节点报告
-all #所有的节点,不管是什么状态的。
-list #列出所有 RUNNING 状态的节点。支持-states 选项过滤指定的状态,节点的状态包含:NEW,RUNNING,UNHEALTHY,DECOMMISSIONED,LOST,REBOOTED。支持--all 显示所有的节点。
-states <States> #和-list 配合使用,用逗号分隔节点状态,只显示这些状态的节点信息。
-status <NodeId> #打印指定节点的状态。
3.1.7、queue
yarn queue [options]
#打印队列信息
-status #<QueueName> 打印队列的状态
3.1.8、rmadmin
yarn rmadmin [-refreshQueues]
[-refreshNodes]
[-refreshUserToGroupsMapping]
[-refreshSuperUserGroupsConfiguration] [-refreshAdminAcls]
[-refreshServiceAcl]
[-getGroups [username]]
<serviceId>]
<serviceId2>]
[-transitionToActive [--forceactive] [--forcemanual]
[-transitionToStandby [--forcemanual] <serviceId>] [-failover [--forcefence] [--forceactive] <serviceId1>
[-getServiceState <serviceId>] [-checkHealth <serviceId>]
[-help [cmd]]
-refreshQueues #重载队列的 ACL,状态和调度器特定的属性,ResourceManager 将重载 mapred-queues 配置文件
-refreshNodes #动态刷新 dfs.hosts 和 dfs.hosts.exclude 配置,无需重启 ResourceManager。
#dfs.hosts:列出了允许连入 NameNode 的 datanode 清单(IP 或者机器名)
#dfs.hosts.exclude:列出了禁止连入 NameNode 的datanode 清单(IP 或者机器名)
#重新读取 hosts 和 exclude 文件,更新允许连到Namenode 的或那些需要退出或入编的 datanode 的集合。
-refreshUserToGroupsMappings #刷新用户到组的映射。
-refreshSuperUserGroupsConfiguration #刷新用户组的配置
-refreshAdminAcls #刷新 ResourceManager 的ACL 管理
-refreshServiceAcl #ResourceManager 重载服务级别的授权文件。
-getGroups [username] #获取指定用户所属的组。
-transitionToActive [–forceactive] [–forcemanual] <serviceId> #尝试将目标服务转为 Active 状态。如果使用了–forceactive 选项,不需要核对非Active 节点。如果采用了自动故障转移,这个命令不能使用。虽然你可以重写
–forcemanual 选项,你需要谨慎。
-transitionToStandby [–forcemanual] <serviceId> # 将服务转为 Standby 状态. 如果采用了自动故障转移,这个命令不能使用。虽然你可以重写–forcemanual 选项,你需要谨慎。
-failover [–forceactive] <serviceId1> <serviceId2> # 启 动 从 serviceId1 到 serviceId2 的故障转移。如果使用了-forceactive 选项,即使服务没有准备, 也会尝试故障转移到目标服务。如果采用了自动故障转移,这个命令不能使用。
-getServiceState <serviceId> #返回服务的状态。(注:ResourceManager 不是 HA 的时候,是不能运行该命令的)
-checkHealth <serviceId> #请求服务器执行健康检查,如果检查失败,RMAdmin 将用一个非零标示退出。(注:ResourceManager 不是 HA 的时候,是不能运行该命令的)
-help [cmd] #显示指定命令的帮助,如果没有指定,则显示命令的帮助。
3.2、启动、停止
3.2.1、命令行启动
1.全部启动 YARN 集群
./bin/start-yarn.sh
2.全部停止 YARN 集群
./bin/stop-yarn.sh
3单独启停 resourcemanager 集群
./bin/yarn-deamon.sh start resourcemanager
./bin/yarn-deamon.sh stop resourcemanager
4单独启停 nodemanager 集群
./bin/yarn-deamon.sh start nodemanager
./bin/yarn-deamon.sh stop nodemanager
3.2.2、CM启动、停止
1.整体启动、停止、重启、滚动重启
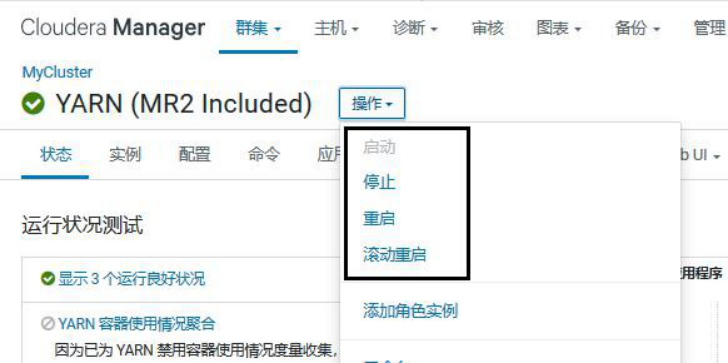
2.部分启动、停止、重启、滚动重启
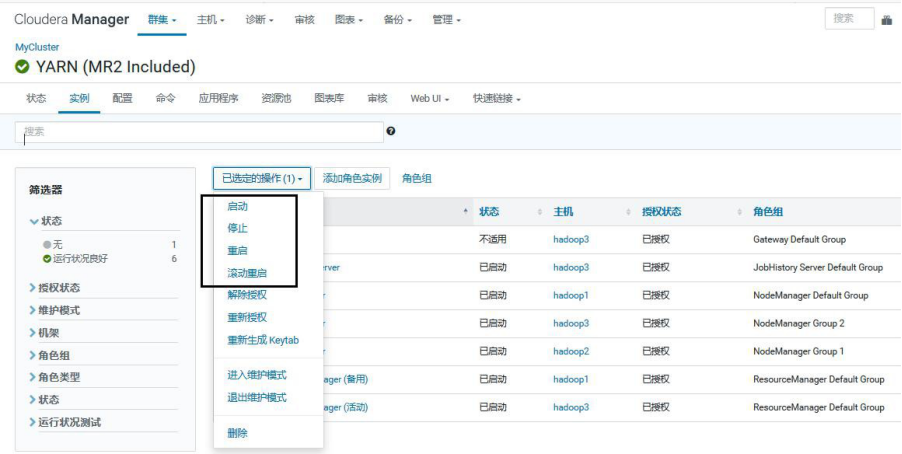
3.3、扩缩容
同HDFS扩缩容
3.4、资源队列-容量调度
3.4.1、概述
Hadoop 的可插拔调度器,允许多租户安全地共享一个大集群,以便在分配容量的约束下及时为应用程序分配资源,被设计来以共享、多租户的形式运行hadoop 应用程序,在友好规则下,能够更大限度地提高集群的吞 吐量和利用率。
Capacity Schedule 调度器以队列为单位划分资源。简单通俗点来说,就是一个个队列有独立的资源, 队列的结构和资源是可以进行配置的。
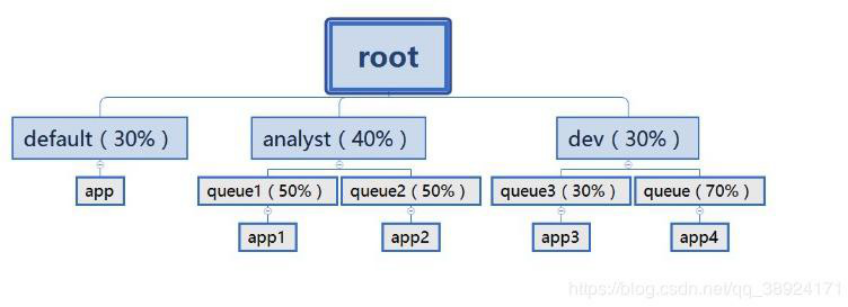
default 队列占 30%资源,analyst 和 dev 分别占 40%和 30%资源;类似的,analyst 和 dev 各有两个子队列,子队列在父队列的基础上再分配资源。队列以分层方式组织资源,设计了多层级别的资源限制条件以更好的让多用户共享一个 Hadoop 集群,比如队列资源限制、用户资源限制、用户应用程序数目限制。队列里的应用以 FIFO 方式调度,每个队列可设定一定比例的资源最低保证和使用上限,同时每个用户也可以设定一定的资源使用上限以防止资源 滥用。而当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
3.4.2、特性
1.分层队列
支持层级队列来确保资源在子队列间共享。
2.容量保证
所有提交到队列的的应用程序都将能保证获取到资源,管理员可以配置soft 和硬件资源分配到每个队列的限制。
3.安全性
每个队列有严格的 ACLs 权限控制,允许哪些用户提交到某个队列,哪些用户不能看看或者修改其他人的应用等。
4.弹性
弹性特性允许闲置资源能被任何队列分配到。
5.多租户
一系列全面的限制,防止单个应用程序、单用户和队列独占队列或集群的所有资源,以确保集群不会不堪重负。
6.可操作性
运行时配置:运行时可以配置队列的定义、属性修改等操作,比如容量、acl 修改
作业保障:管理员停止队列时,保障正在运行的应用程序运行完成,保障其他新的应用程序不能提交到 队列或者子队列。
3.4.3、调度器设置
要配置 ResourceManager 以使用 CapacityScheduler,请在 conf/yarn-site.xml 中 设 置 以 下 属 性 : yarn.resourcemanager.scheduler.class:org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.C apacityScheduler
CM 中设置:
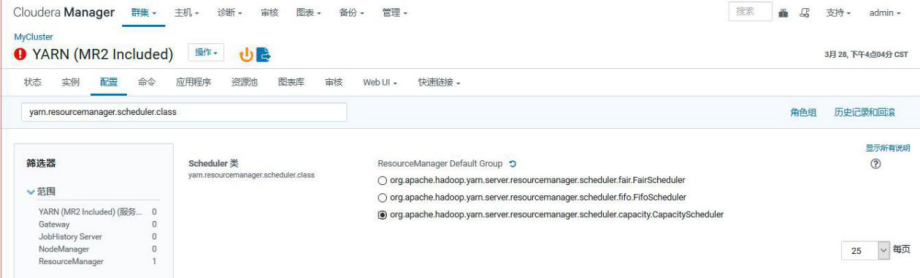
3.4.4、队列参数
1.资源分配相关参数:
capacity:队列的最小资源容量(百分比)。注意,所有队列的容量之和应小于 100
maximum-capacity:队列的资源使用上限
minimum-user-limit-percent:每个用户最低资源保障(百分比)
user-limit-factor:每个用户最多可使用的资源量(百分比)
2.限制应用程序数目的相关参数:
maximum-applications:集群或者队列中处于等待和运行状态的应用程序数目上限,这是一个强限制项,一旦集群中应用程序数目超过该上限, 后续提交的应用程序将被拒绝。默认值为 10000。Hadoop 允许从集群和队列两个方面该值,其中,集群的总体数目上限可通过参数yarn.scheduler.capacity.maximum-applications 设置,默认为 10000, 而单个队列可通过参数yarn.scheduler.capacity.<queue-path>.maximum-applications 设置适合自己的值
maximum-am-resource-percent:集群中用于运行应用程序ApplicationMaster 的资源比例上限,该参数通常用于限制处于活动状态的应用程序数目。所有队列的 ApplicationMaster 资源比例上限可通过参数 yarn.scheduler.capacity.maximum-am-resource-percent 设置,而单个队列可通过参数yarn.scheduler.capacity.<queue-path>.maximum-am-resource-percent 设置适合自己的值
3.队列访问权限控制
state:队列状态,可以为 STOPPED 或者 RUNNING。如果一个队列处于 STOPPED 状态,用户不可以将应用程序提交到该队列或者它的子队列中。类似的,如果 root 队列处于 STOPPED 状态,则用户不可以向集群提交应用程序,但正在运行的应用程序可以正常运行结束,以便队列可以优雅地退出
acl_submit_application:限定哪些用户/用户组可向给定队列中提交应用程序。该属性具有继承性,即如果一个用户可以向某个队列提交应用程序,则它可以向它所有子队列中提交应用程序
acl_administer_queue:为队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等。同样,该属性具有继承性,如果一个用户可以向某个队列中提交应用程序,则它可以向它的所有子队列中提交应用程序当管理员需动态修改队列资源配置时,可修改配置文件conf/capacity-scheduler.xml,然后运行“yarn rmadmin -refreshQueues” 当前 Capacity Scheduler 不允许管理员动态减少队列数目,且更新的配置参数值应是合法值,否则会导致配置文件加载失败
3.4.5、队列配置
CapacityScheduler 有一个预定义队列叫 root,系统中所有的队列是 root 队列的一个子队列。
更多的队列可以通过配置 yarn.scheduler.capacity.root.queues 该属性来配置,多个子队列 使用","来分割。
CapacityScheduler 有一个概念叫 queue path,是用来配置队列层级的,这个 queue path 是队列的 层级,使用 root 开始,然后用"."来进行连接。比如root.a。
队列的子队列可使用 yarn.scheduler.capacity.<queue-path>.queues 来配置。除非另有申明,否则子元素不能直接从父元素继承属性。
产线案例
<?xml veRegionServerion="1.0" encoding="utf-8"?>
<configuration>
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,ia,ia_dzh,ia_serv</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>0</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>t1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>t1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia.user-limit-factor</name>
<value>2</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia.maximum-capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia.state</name>
<value>RUNNING</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia.acl_submit_applications</name>
<value>if_ia_pro,if_ia_serv</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia.acl_administer_queue</name>
<value>ia</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia_dzh.capacity</name>
<value>30</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia_dzh.user-limit-factor</name>
<value>5</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia_dzh.maximum-capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia_dzh.state</name>
<value>RUNNING</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia_dzh.acl_submit_applications</name>
<value>if_ia_pro</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia_dzh.acl_administer_queue</name>
<value>if_ia_pro</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia_serv.capacity</name>
<value>20</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia_serv.user-limit-factor</name>
<value>4</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia_serv.maximum-capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia_serv.state</name>
<value>RUNNING</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia_serv.acl_submit_applications</name>
<value>lf_ia_serv</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.ia_serv.acl_administer_queue</name>
<value>ia_serv</value>
</property>
</configuration>
3.5、资源队列-公平调度设置
3.5.1、概述
公平调度是一种为应用程序分配资源的方法,它可以随时间使得所有应用程序平均获得相等的资源份额。 下一代的 Hadoop 能够调度多种资源类型。默认情况下,公平调度程序仅基于内存来确定调度公平性决策。它可以使用Ghodsi 等人开发的DRF(作业调度算法)的概念来配置,同时调度内存和 CPU。当有一个应用程序在运行时,该应用程序将使用整个集群。当提交其他应用程序时,将会有资源被释放来分配给新应用程序,以便最终每个应用程序获得的资源大致相同。与组成应用程序队列的默认 Hadoop 调度器不同,这可以让短应用程序在合理的时间内完成,同时不会使长期存在的应用程序挨饿。它也是一种在多个用户之间共享群集的合理方式。最后,公平共享还可以与应用优先级一起使用 - 优先级用权重来确定每个应用应获得的总资源的比例。
调度程序将应用程序进一步组织为“队列”,并在这些队列之间公平地共享资源。默认情况下,所有用户共享一个名为“default”的队列。如果应用程序专门在容器资源请求中列出队列,则将请求提交给该队列。还可以通过配置中基于请求的用户名来分配队列。在每个队列中,调度策略被用来在正在运行的应用程序之间共享资源。默认是根据内存来公平分享资源,但也可以配置具有 DRF(作业调度算法)的 FIFO 和多资源策略。队列可以按照阶级来划分资源,并根据权重配置来按特定比例去共享群集。
除了提供公平共享资源外,Fair Scheduler 还允许为队列分配可保证的最小资源,这对于确保某些用户,用户组或生产应用始终获得足够的资源是很有用的。当队列包含应用程序时,它最少能获得一个最小资源,但是当队列不需要完全保证共享时,超出部分将在其他正在运行的应用程序之间分配。这使得调度器可以保证队列容量,同时在队列里不包含应用程序时,可以有效地利用资源。
Fair Scheduler 允许所有应用程序默认运行,但也可以通过配置文件限制每个用户和每个队列运行的应用程序数量。这在当用户必须一次提交数百个应用程序时是非常有用的,或者说,如果同时运行太多应用程序会导致创建过多的中间数据或过多的上下文切换时,可以提高性能。限制应用程序不会导致任何后续提交的应用程序失败,只会在调度程序的队列中等待,直到某些用户的早期的应用程序完成为止。
3.5.2、具有可插拔策略的分层队列
Fair Scheduler 支持层次队列(hierarchical queues),所有队列都从 root队列开始,root 队列的孩子队列公平地共享可用的资源。孩子队列再把可用资源公平地分配给他们的孩子队列。apps 可能只会在叶子队列被调度。此外, 用户可以为每个队列设置不同的共享资源的策略,内置的队列策略包括 FifoPolicy, FaiRegionServerharePolicy (default), and DominantResourceFairnessPolicy。
3.5.3、队列配置
自定义 Fair Scheduler 通常涉及更改两个文件。首先,可以通过在现有配置目录的 yarn-site.xml 文件中添加配置属性来设置调度程序范围的选项。其次,在大多数情况下,用户需要创建一个分配文件,列出存在哪些队列以及它们各自的权重和容量。分配文件每 10 秒重新加载一次,允许动态更改。
可以放在 yarn-site.xml 中的属性属性描述
yarn.scheduler.fair.allocation.file分配文件的路径。除了某些策略默认值之外,分配文件是描述队列及其属性的 XML 清单。此文件必须采用下一节中描述的 XML 格式。如果给出了相对路径,则在类路径(通常包括 Hadoop conf 目录)上搜索文件。默认为 fair-scheduler.xml。
yarn.scheduler.fair.user-as-default-queue 在未指定队列名称的情况下,是否将与分配关联的用户名用作缺省队列名称。如果将其设置为“false”或未设置,则所有作业都有一个共享的默认队列,名为“default”。默认为 true, 产线环境一版会置位 false
yarn.scheduler.fair.preemption 是否使用抢占。默认为 true。分配文件必须是 XML 格式。格式包含五种类型的元素:
Queue elements:代表队列。队列元素可以采用可选属性“类型”,当设置为“父”时,它将使其成为父队列。当我们想要创建父队列而不配置任何叶队列时,这非常有用。每个队列元素可能包含以下属性:
minResources: 队 列 有 权 获 得 的 最 小 资 源
maxResources: 分 配 队 列 的 最 大 资 源
maxRunningApps: 限 制 队 列 中 的 应 用 程 序 数 量 一 次 运 行
maxAMShare:限制可用于运行应用程序主服务器的队列公平共享的分数。
weight:与其他队列不成比例地共享群集。权重默认为 1,权重为 2 的队列应该获 得 的 资 源 大 约 是 具 有 默 认 权 重 的 队 列 的 两 倍 。
schedulingPolicy:设置任意队列的调度策略。
aclSubmitApps:可以将应用程序提交到队列的用户和/或组的列表。
aclAdministerApps:可以管理队列的用户和/或组的列表。
3.5.4、队列设置
1.设置 yarn.resourcemanager.scheduler.class 值为org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FaiRegi onServercheduler




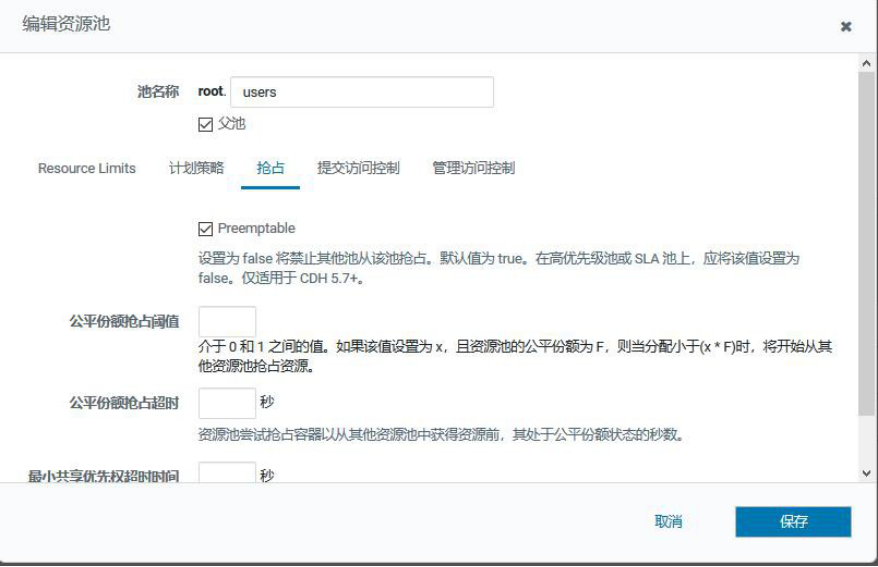
3.5.5、Web UI 监控
可以通过 ResourceManager 的 Web 界面在 http://*ResourceManagerURL*/cluster/scheduler 中检查当前的应用程序,队列和公平份额(资源)。
可以在 Web 界面上的每个队列中看到以下字段: Used Resources - 分配给队列中容器的资源总和。
Num Active Applications - 队列中至少收到一个容器的应用程序数。Num Pending Applications - 队列中尚未收到任何容器的应用程序数。Min Resources - 保证队列的最低资源配置。
Max Resources - 允许进入队列的最大资源配置。
Instantaneous Fair Share - 队列的瞬时公平份额资源。这些资源仅考虑活动队列(具有正在运行的应用程序的队列),并用于调度决策。当其他队列不使
用队列时,可以为队列分配超出其共享的资源。资源消耗等于或低于其瞬时公平份额的队列将永远不会抢占其容器。
Steady Fair Share - 队列稳定的公平份额资源。这些资源考虑所有队列,无论它们是否处于活动状态(已运行应用程序)。这样,计算就不会很频繁,而且仅在配置或容量发生变化时才会更改。它们旨在提供用户可以预期的资源可见性,从而显示在 Web UI 中。
3.6、资源队列原则
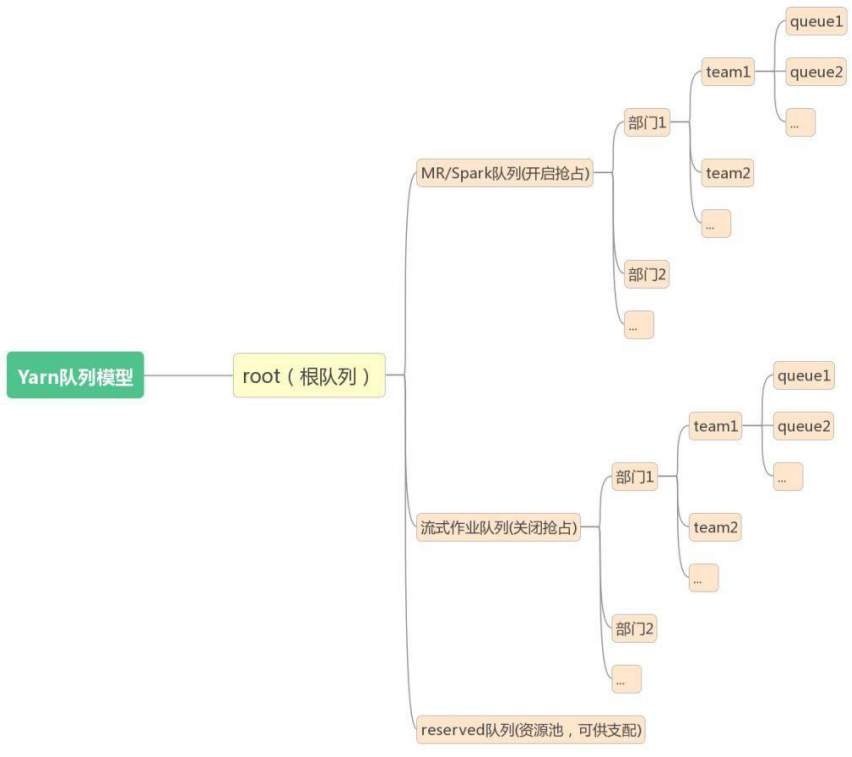
3.7、资源队列调整案例
【案例】
xx集群上的队列分为生产型和非生产型。在xx日凌晨0 点--早上 9 点,非生产型队列占用资源较多,导致集群压力过大,影响了当日早上 9 点的 xx 下发。生产侧提出了队列资源的优化方案,如下:
Queue Absolute Capacity Configured Max Capacity
ds 2 3
ec 5 7
db_ser 3 2
hc 80 1.23
default 2 7
zy_scp 5 4
Am1c 3 4
【备份当前队列的配置文件】
在 CM 首页点击 yarn
在 yarn 的【配置】页面,搜索“容量调度”,调出右侧的【值】
将【值】中的数据全部复制出来备份到本地。建议粘贴到写字板上,粘贴到 txt 里排版会出现混乱。
【修改当前队列的配置信息】
以 qc 队列为例:
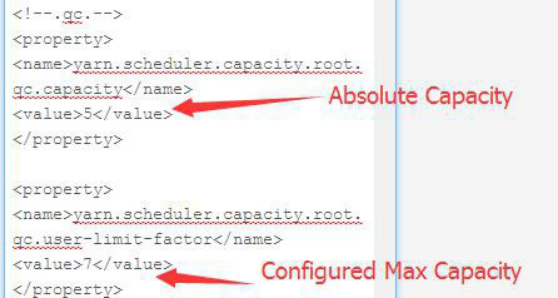
【保存更改】
【刷新动态资源池】
在 CM 首页,点击集群右边的倒三角,再点击【刷新动态资源池】
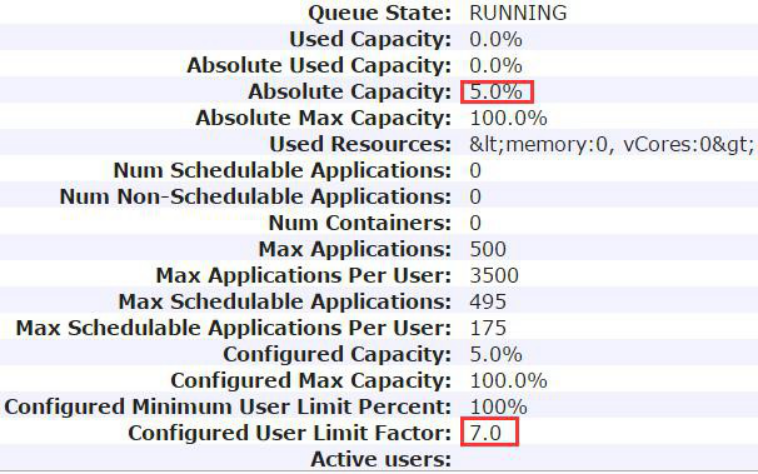
【核实已经修改成功】
在 Applications 页面的 Scheduler,调出 qc 队列的信息
3.8、无CM 修改队列资源
【需求】
固网集群 xx 队列 lf_zl 资源 38%*1.8 拆分
原队列 lf_zl 改为 25%*2 租户使用
其余资源新增队列 lf_ja 13%*1.8 预计后续部署租户使用
【修 改 capacity-scheduler.xml 】
cd/opt/beh/core/hadoop/etc/hadoop/ #进入配置文件所在目录cpcapacity-scheduler.xmlcapacity-scheduler.xml_20170616 #备份配置文件
vi capacity-scheduler.xml #修改配置文件
修改 yarn.scheduler.capacity.root.queues 的值,在 value 里添加 lf_ja

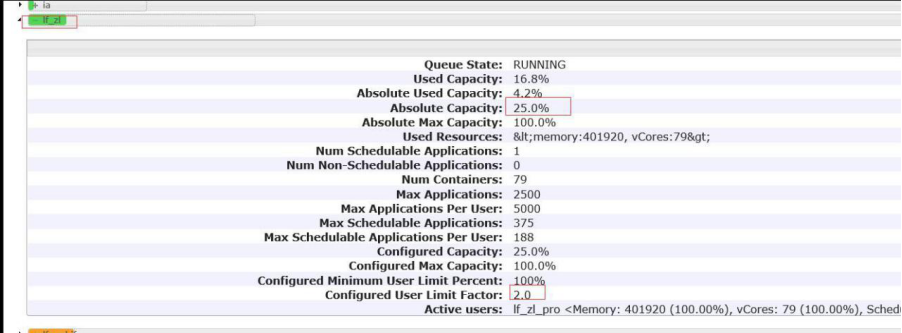
修改原 lf_zl 的值:
把 yarn.scheduler.capacity.root.lf_zl.capacity 的值从 38 改为 25

把 yarn.scheduler.capacity.root.lf_zl.user-limit-facto 的值从 1.8 改为 2

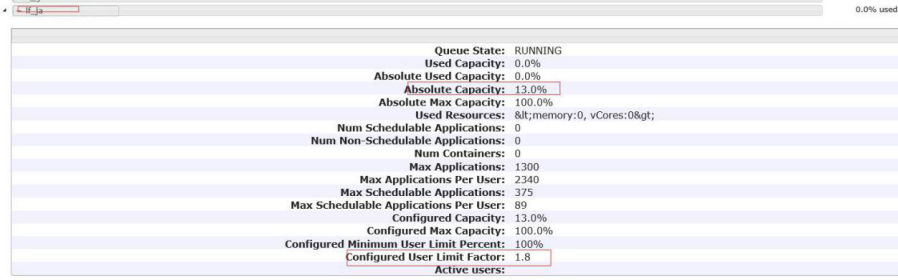
在配置文件中新增队列配置文件,如下:
<property>
<name>yarn.scheduler.capacity.root.lf_ja.capacity</name>
<value>13</value>
<description>default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.lf_ja.user-limit-factor</na me>
<value>1.8</value>
<description>
default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.lf_ja.maximum-capacity</ name>
<value>100</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.lf_ja.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.lf_ja.acl_submit_applicatio ns</name>
<value>lf_ja_pro</value>
<description>
The ACL of who can submit jobs to the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.lf_ja.acl_administer_queue
</name>
<value>lf_ja_pro</value>
<description>
The ACL of who can administer jobs on the default
queue.
</description>
</property>
【把更改后的配置文件拷贝到 stanby 节点】
cp /opt/beh/core/hadoop/etc/hadoop/capacity-scheduler.xml /opt/beh/core/hadoop/etc/hadoop/capacity-scheduler.xml_20170616#登录 stanby 节点备份原配置文件
scp /opt/beh/core/hadoop/etc/hadoop/capacity-scheduler.xml hadoop@10.162.3.71:/opt/beh/core/hadoop/etc/hadoop/capacity-scheduler.xml #把修改后的配置文件拷贝到备节点主机上
【登录主节点动态刷新资源池】
yarn rmadmin -refreshQueues#刷新动态资源池
【登录 yarn 界面检查更改结果是否正确】
如图:
3.9、修改用户yarn 资源分配
hadoop修 改 用 户yarn队 列 分 配 倍 数
1.以管理员用户登录所要更改的 CM,进入后点击 yarn,如图:
2.在 yarn 界面点击配置按钮,并在弹出的查找框中输入“容量调度”,查找如图:
3.把出现的值粘贴到文本留作备份(建议粘贴到写字板上,粘贴到 txt 里排版会出现混乱)切记一定要备份!!!
4.修改所需修改的值(一般限制用户队列,建议修改分配的倍数即 Configured User Limit Factor 这个值。修改 Absolute Capacity 需要对整体集群进行计算,所以用户加一起的达到百分百,建议不做修改)
5.列:如修改 didi 用户的 Configured User Limit Factor 值。
(1)登录 yarn,点击 Scheduler,点击 didi 用户的倒三角图标:
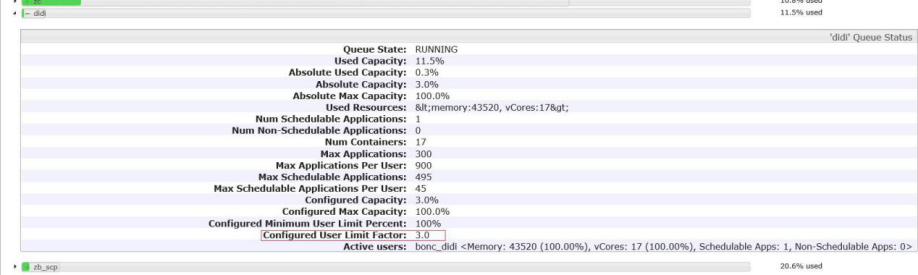
我们可以看出 didi 用户的 Configured User Limit Factor 值为 3, 即他可以使用超出他分配百分比的三倍。
(2)修改拷贝中的文本,查找 didi 配置文件那列:

(3)找到所需修改的值 Configured User Limit Factor。将倍数修改成需要调整后的值。

(3)把配置文件拷贝回 CM-yarn-配置-容量调度的那个文本框里,点击保存。
(4)回到 CM 主页,点击集群右边的倒三角,点击刷新动态资源池。
(5)配置完毕,到 yarn 上查看修改是否成功。
4、排障
4.1、资源问题
【现象】
目前 CC 集群出现大量任务积压,运行缓慢的情况,怀疑是集群的资源分配出现了问题。
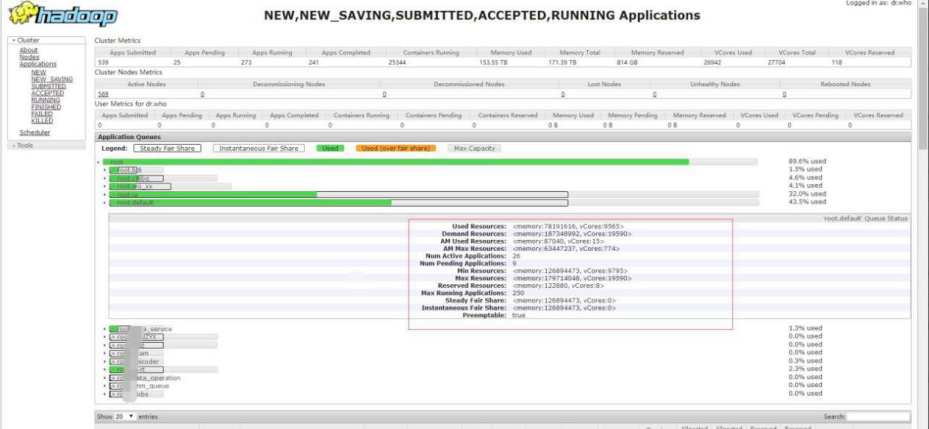
CC 集群总共有 569 个 NodeManager,总共 VCore 数是 27704 ,内存171T,资源比较丰富。理论上,应该足够任务的执行。
经过现场的分析,发现如下现象。
集群总体的资源使用高,少量剩余
如下图所示,集群总体的资源使用已经非常高,但是仍有少量剩余。其中 CPU Vcore,总共 27704 个,使用了 26842 个。内存总共 171T,使用了153T。即集群 CPU 使用了 95%以上,但是仍然有少量的剩余。
队列最小资源没有得到满足
从上图可以看出,目前配置的队列最小资源都设置的比较大,即使集群资源使用非常高,仍然没有满足最小资源的需求。队列最小资源,是集群有资源的情况下,必须要满足的资源。并且集群中,绝大部分队列都没有达到最小资源。
出现大量 Map Pening
如下图所示,集群中出现大量的任务都有如下的现象。Reduce 已经启动, 在等待 Map 阶段完成,然后向前执行,但是 Map 阶段还有部分任务没有完成, 这部分任务也拿不到资源执行,running 的 map 为 0。从而出现了死锁的情况。即 Reduce 启动了占用了资源,但是在等待 Map,而 Map 拿不到资源无法执行。
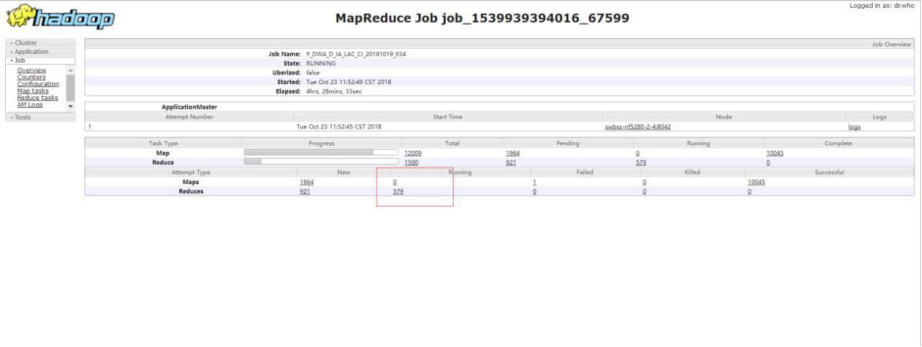
【分析】
根据上面的现象,可以分析得出,导致任务出现积压的情况,直接原因是因为,出现了资源分配的死锁。即 Reduce 阶段占用了资源,但是需要等待Map 阶段执行完成,而 Map 阶段在等待资源,但是资源已经被 Reduce 都占用了,无法申请到资源,因此无法执行。大量的任务都出现了这种情况,集群中绝大部分的资源都被 Reduce 的 Container 占用了,而 Map 阶段分到的资源很少。
Mapreduce 任务在执行任务时,分为 Map,Reduce 两个阶段,这两个阶段都需要申请 yarn 的 Container,进行运行。并且 Yarn 并不区分 Map,
Reduce 的 Container 类型,只要是申请资源,会一视同仁。Reduce 阶段, 需要获取 Map 阶段的输出,从而继续往下执行。Yarn 通过参数
mapreduce.job.reduce.slowstart.completedmaps,设定比例,例如设置为0.8(目前集群设置为 0.8),则 Map 阶段完成 80%后,Reduce 阶段就会开始申请 Container,占用资源。提前启动 Reduce 的好处是,可以尽早的申请到资源,然后 Reduce 首先从已经完成的 Map 任务中拷贝数据,Map 同时执行。从而,加快整体任务的执行。
然而,这个设定,在极端情况下,会出现问题:
1.集群中存在大量任务同时运行
2.其中不少的任务都需要启动大量的 Map 任务和 reduce 任务
3.集群总体的资源使用率已经非常高,没有很多的剩余资源
在上述的情况下,就有可能出现资源死锁的情况。由于大量的任务同时运行,并且其中不少的任务都有大量的 Map 任务和 Reduce 任务,当 Map 任务完成到一定比例之和,就开始启动 Reduce 任务,Reduce 任务启动之后, 占用了资源,但是 Map 还没有结束。集群总体的资源使用率已经非常高,没有很多的剩余资源,Map 阶段分配不到足够的资源,只能非常缓慢的运行,或者甚至分不到资源,直接不运行了。
整个任务就停滞了,但是也不超时。
另外一个加剧该现象的原因是,因为目前集群队列的资源设定中,每个资源池的最小资源占比设置的比较大,总和已经超过了集群资源的总和 。
设定队列的最小资源,是为了保证队列能够至少能够拿到最小资源,不至于被饿死。并且集群有一定的剩余资源,可以供资源池之间竞争,作为补充。但是目前的设定,导致即使集群所有的资源也无法满足每个队列的最小资源。这样的情况,就导致了,集群的所有资源基本会被使用完,并且关键的是,所有的队列都认为是自己的最小资源。即使某个队列出现了资源饥饿的情况,也无法从集群或者其他队列抢占部分资源来补充。
【解决方案】
设置 mapreduce.job.reduce.slowstart.completedmaps 为 1
设置为 1 之后,Reduce 需要等待 Map 阶段都完成之后,才会申请资源并启动,这样的话,就不会出现 Reduce 占用资源而 Map 分配不到的情况了。
如下图所示,通过 CM,设置mapreduce.job.reduce.slowstart.completedmaps 为 1。同时,原来设定默认 reduce 个数为 600, 这个值偏大,修改为 40。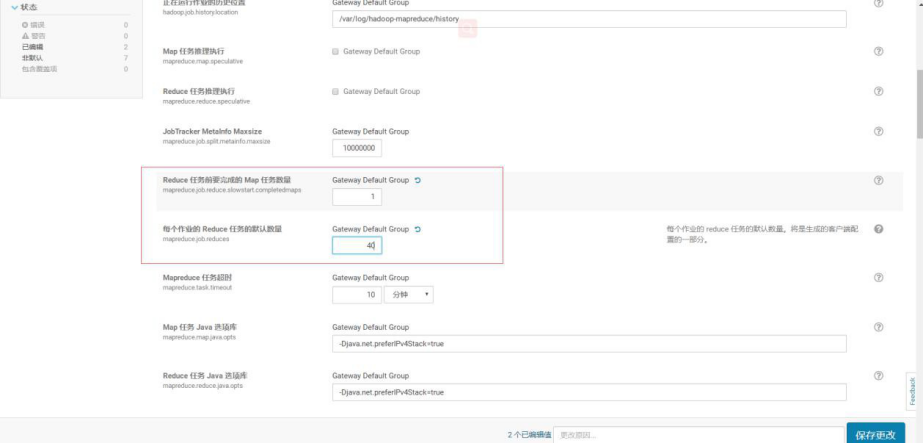
重新调整资源池的设定
重新调整各资源池,最小资源,最大资源,以及并发任务数。
建议调整所有资源池的最小资源为集群资源的 60%。最大资源为集群资源的 100%。
【整体修改】
NodeManager 内存调整
如下图所示,目前集群 NodeManager 内存为 2G,对于一个比较繁忙, 并且规模很大的集群,NodeManager 内存建议可以设置的稍微大一点,下图修改成 4G。

【控制Map 数】
可以通过设置 mapreduce.input.fileinputformat.split.minsize 参数来控制任务的 Map 数,该参数控制每个 map 的最小处理数据量。
在 hive 中可以通过 set mapreduce.input.fileinputformat.split.minsize=67108864 来设置
4.2、慢作业
在 AA 集群中存在部分任务,执行较慢的情况。这些任务都是比较长的 hiveSQL,处理的数据量并不是很大,在几个 G 左右,但是运行时间很长,需要 40 分钟到一个小时。
经过分析,这些任务的 map 阶段其实运行的很快,几十秒就能结束,慢主要是发生在 Reduce 阶段,Reduce 需要花费几十分钟才能运行完成。查看Reduce 阶段日志发现,Reduce 写出了大量的日志,约有 1G,并且这些日志都像是从表中获取的数据进行的打印。正常 Hive 是不会输出这些日志的,只有应用端进行了设置才会进行打印。
出现这种情况,最有可能的是使用 Java 代码编写了 Hive 的 UDF 程序,在UDF 中进行了打印,并且在 hive SQL 中使用了 UDF,从而打印了这些日志。经与生产侧 xxx 沟通,确认使用了 UDF,应用正在确认相关代码,并进行下一步解决。
4.3、gc overhead limit exceeded 导致map 失败
【现象】
xx日,4m1-01 集群上的多个 job 执行失败。
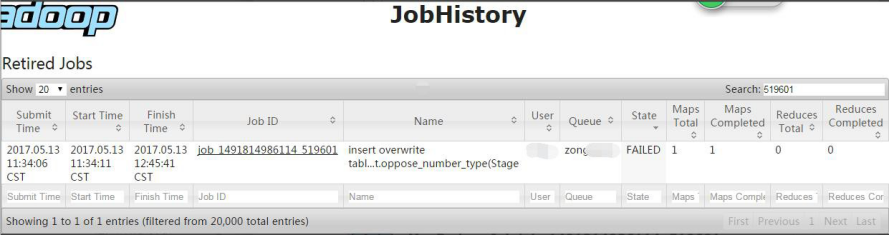
【定位失败的 map task】
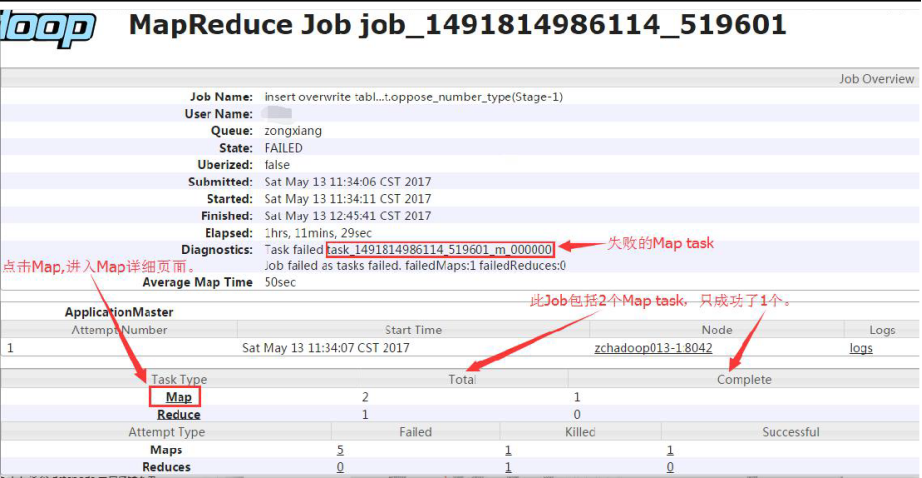
【查看失败的 map tasks 的日志】
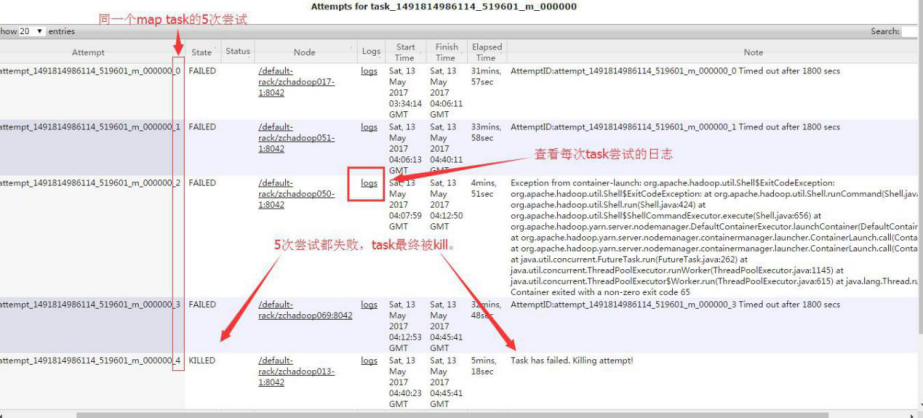
发现第 3 次 task attempt 有一条 FATAL 型的报错: java.lang.OutOfMemoryError: GC overhead limit exceeded
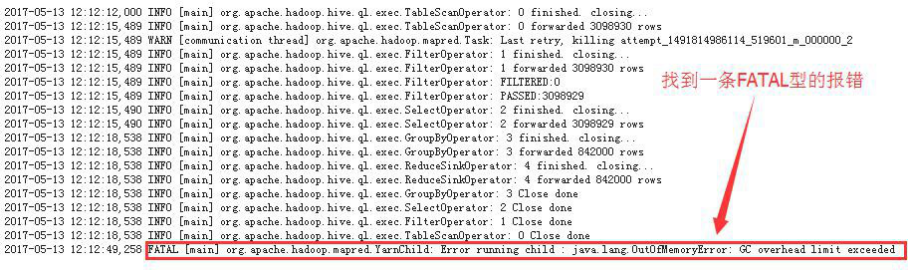
【确认末端原因】
JVM 的堆栈过小,导致 job 执行失败。
【解决办法】
可以调整JVM的堆栈大小,但是目前没有标准可供参考去调整JVM。而且这种报错的频率不高,所以只能建议业务方再多次执行 job,或改在资源较空闲的时间段执行 job。事实证明,这种办法是可行的。
最佳方案:适当调大 mapreduce.map.memory.mb 这个参数的值
4.4、hive 执行任务中报内存不足的错误
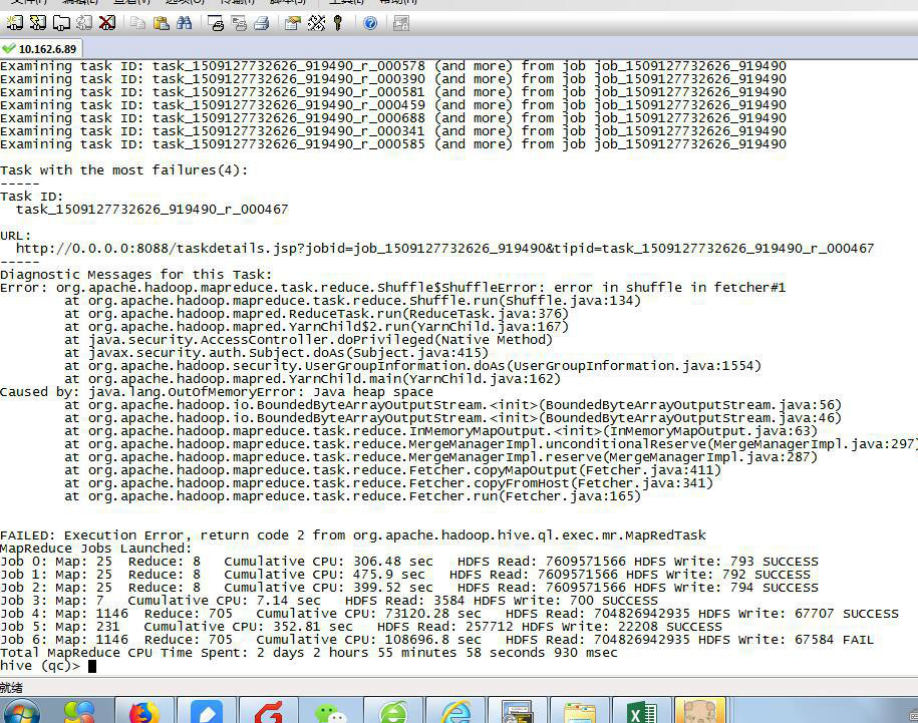
执行 hive 前加上参数
set mapresuce.reduce.shuffle.input.buffer.percent=0.1;
set mapred.child.java.opts=-Xmx3096m; // jvm 启动的子线程可以使用的最大内存
set mapreduce.reduce.shuffle.parallelcopies=10;// reuduce shuffle 阶段并行传输数据的数量
export HADOOP_CLIENT_OPTS="-Xmx8192m $HADOOP_CLIENT_OPTS
4.5、Job 报错失败
用户反映 JOB 执行失败报错,如下:

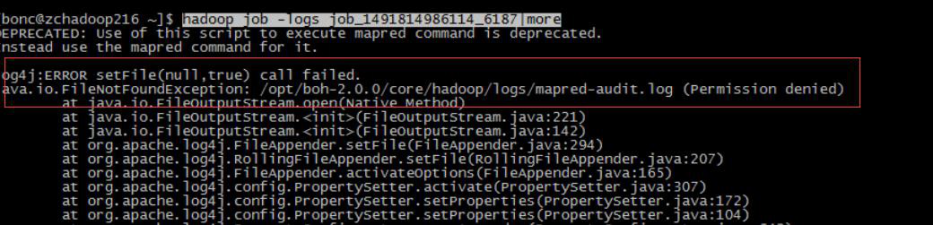
怀疑为没有此目录权限
查找该目录下权限正常,但并无 mapred-audit.log 文件,其他接口机有此文件。

添加此文件:

4.6、NameNode RPC 负载过高
【现象】
基于小文件问题与 XXX 和 XXX 了解多租户初筛程序问题,发现初筛程序 URLFilter_Hour_Tenants 在执行之前会获取文件信息,获取文件信息需要 2 至 5 小时才能完成。
【问题排查】
1、目前处理 HHH 日志的程序有如下: YX:凌晨 1 点分省处理昨天一天的数据
2、HHH 日志初筛,按小时处理省份数据,rpc 请求为 31 万,缺点:每小时每个省份的作业处理却要扫描当天此省份全量文件信息,造成大量无用的 rpc 请求
3、Spark streaming 实时采集原始日志,目前是增量获取文件信息,对 rpc 的压力影响较小
HHH 日志初筛现象:
Job 输入目录有 31 万的文件,这个任务读取整个文件夹其中的 1.4 万的文件。如下截图是初筛 job 的 rpc 请求,请求次数为 310172,从日志上看每秒钟并发十几次到几十次,耗时 3 个半小时,并发度太低的原因是因为 rpc 请求队列堆积了很多请求
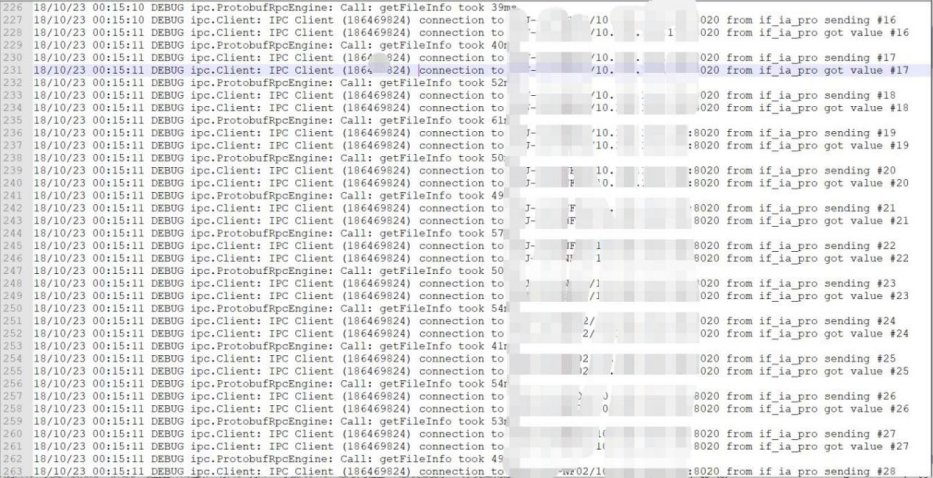
昨天晚上 23 点到今天凌晨 2 点的时候,rpc 队列累积请求长度较高
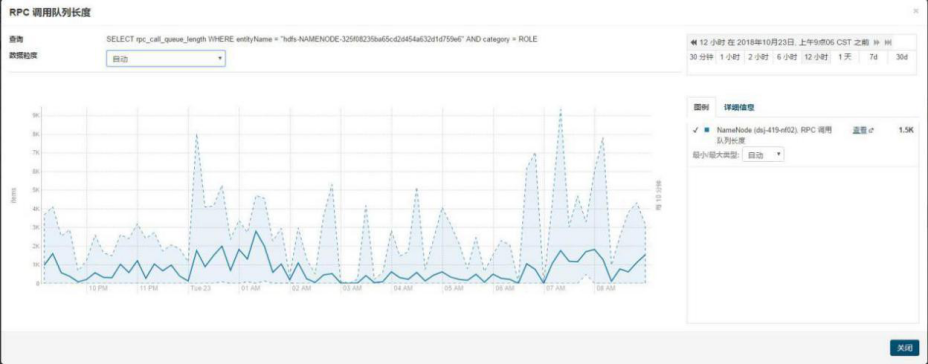
昨天晚上 23 点到今天凌晨 2 点的时候,rpc 平均请求时长偏高

【解决方案】
1、HHH 多租户初筛程序由原来的 MR 批处理改为 spark streaming 实时采集处理,降低 rpc 负载,XXX 协助 XXX、XXX、XXX 改造程序
2、spark streaming 数据直接输出到租户对应目录,省去 mv 环节
3、预计两周上线,上线前需做代码、流程评审
4.7、SRC 层分钟表hive 入库延迟排查
【现象】
XXLL 分钟表 load 存在异常,平台支撑组牵头排查 XXLLSRC 层分钟表 hive 入库延迟问题。
【问题排查】
Hive 错误日志
异常出现次数:大概 595 次
异常信息:
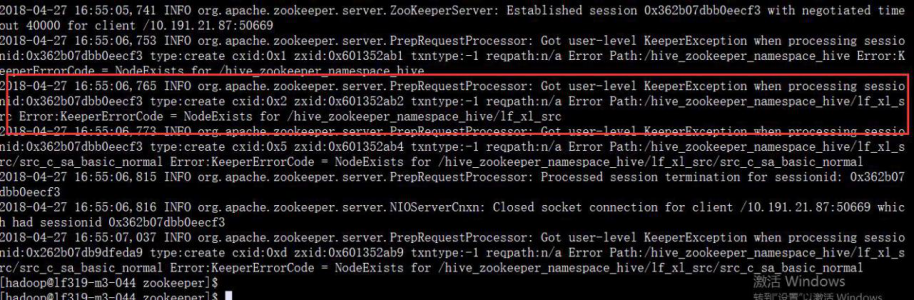
2019-04-27 01:38:41,484 ERROR ZooKeeperHiveLockManager (SessionState.java:printError(920)) - Unable to acquire IMPLICIT, EXCLUSIVE lock lf_xl_src@src_c_sa_basic_normal after 100 attempts. 2019-04-27 01:38:41,506 ERROR ql.Driver
(SessionState.java:printError(920)) - FAILED: Error in acquiring locks: Locks on the underlying objects cannot be acquired. retry after some time
org.apache.hadoop.hive.ql.lockmgr.LockException: Locks on the underlying objects cannot be acquired. retry after some time
at org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager.acquireLocks( DummyTxnManager.java:164)
at org.apache.hadoop.hive.ql.Driver.acquireLocksAndOpenTxn(Driver.java: 988)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1224) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1053)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1043) at
org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:20 9)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:161) at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:372) at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:307) at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:704) at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:677)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:617)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorI mpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethod AccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Hive 锁
查看锁:

锁拥有者:
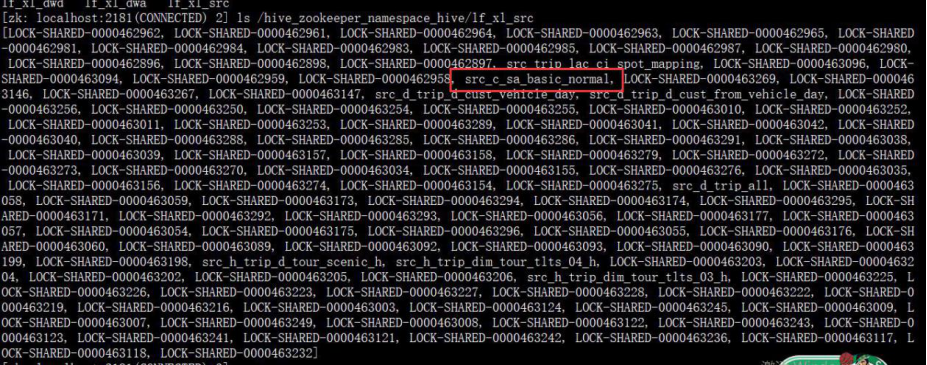
> show locks src_c_sa_basic_normal extended;
OK
lf_xl_src@src_c_sa_basic_normal SHARED LOCK_QUERYID:lf_xl_bp_20190427164141_acb414ff-d237-414b-a778-5 ef916724c04
LOCK_TIME:1524818467680 LOCK_MODE:IMPLICIT
LOCK_QUERYSTRING:insert overwrite table lf_xl_dwd.dwd_d_sa_basic_n ormal_hour partition(month_id='201904',day_id='27',hour_id='15', prov_id='075',sa_type)
select msisdn , imsi ,
start_time , end_time , imei ,
mcc ,
mnc , current_lac, current_ci , roamtype , eventtype , rantype , province ,
fiRegionServert_lac , fiRegionServert_ci , latitude ,
longitude , area ,
hrov_id , harea_id, rmsisdn, rimsi, srvstat ,
cdRegionServertat ,
direction ,
srvorig ,
srvtype , poweroff_ind , csfb_res ,
enodebid , ci ,
destnet_type , sourcenet_type, uenc ,
msnc ,
res_time ,
msg_id , cause_code, district_id, hcountry, is_filled, recv_time, sa_type
from lf_xl_src.src_c_sa_basic_normal
where date_id='20190427' and hour_id='15' and prov_id='075' and no
t(imsi='' and msisdn='') and not(imsi regexp '\D' or msisdn regexp '\ D')
hive目前主要有两种锁,SHARED(共享锁 S)和 Exclusive(排他锁 X)。共享锁 S 和 排他锁 X 它们之间的兼容性矩阵关系如下:

Zookeeper 日志
Hive 获取 lock 失败:
日志条数:

Znode 结构:

进程堆栈:

进程堆栈信息:
"main" prio=10 tid=0x00007fdf7c012800 nid=0x772f waiting on condi tion [0x00007fdf85b23000]
java.lang.Thread.State: TIMED_WAITING (sleeping) at java.lang.Thread.sleep(Native Method)
at org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveL ockManager.lock(ZooKeeperHiveLockManager.java:268)
at org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveL ockManager.lock(ZooKeeperHiveLockManager.java:182)
at org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager.acquir eLocks(DummyTxnManager.java:161)
at org.apache.hadoop.hive.ql.Driver.acquireLocksAndOpenTxn(Dri ver.java:988)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1224) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1053)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1043)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver. java:209)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:161)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:372)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:307)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:704)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:677) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:617)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Delegating MethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
【目前解决方案】
取消 load 操作,改为 cp 操作,检测 hdfs 文件修复 hive 分区。
【其他问题】
强制杀死 kafka 消费者:
每秒中周期提交 offset
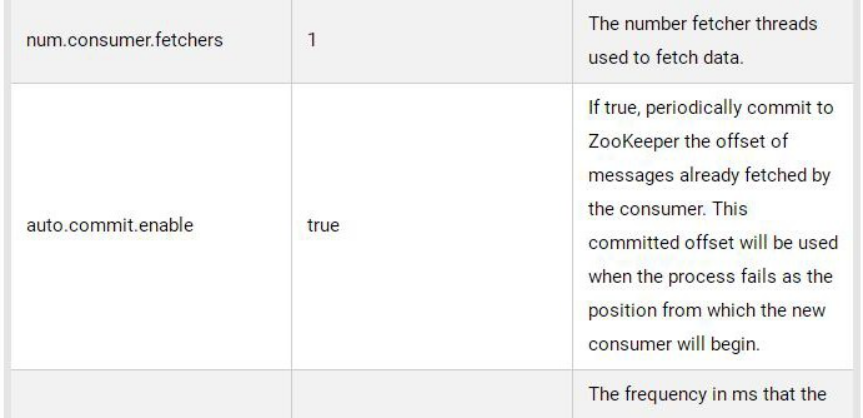
4.8、大数据作业JVM 内存崩溃 1
【现象】
今天 XXX 反馈在接口机 XXX 上做 hdfs dfs -mv(同时执行 150 个 mv)操作的时候出现了大量的类似 hs_err_pid10147.log(10147 代表 java 进程号)这样的文件,这个文件是 java 的致命错误日志,进程会直接崩溃。
【问题排查】
查看日志
hs_err_pid10147.log 中关键日志如下,或者是内存不足或者是 java 不能创建新的线程(即在系统层面限制了进程或线程创建的数据量)
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Cannot create GC thread. Out of system resources. # Possible reasons:
# The system is out of physical RAM or swap space # In 32 bit mode, the process size limit was hit
# Possible solutions:
# Reduce memory load on the system
# Increase physical memory or swap space # Check if swap backing store is full
# Use 64 bit Java on a 64 bit OS
# Decrease Java heap size (-Xmx/-Xms)
# Decrease number of Java threads
# Decrease Java thread stack sizes (-Xss)
# Set larger code cache with -XX:ReservedCodeCacheSize= # This output file may be truncated or incomplete.
#
# Out of Memory Error (gcTaskThread.cpp:48), pid=14974, tid=0x00007fcbeaf75700
#
# JRE veRegionServerion: (8.0_161-b12) (build )
# Java VM: Java HotSpot(TM) 64-Bit Server VM (25.161-b12 mixed mode linux-amd64 compressed oops)
# Failed to write core dump. Core dumps have been disabled. To enable core dumping, try "ulimit -c unlimited" before starting Java again
#
确实是 hdfs mv 的 java 进程崩溃
VM Arguments:
jvm_args: -Dproc_dfs -Xmx1000m
-Dhadoop.log.dir=/opt/cloudera/parcels/CDH-5.13.1-1.cdh5.13.1.p0.2/ lib/hadoop/logs -Dhadoop.log.file=hadoop.log
-Dhadoop.home.dir=/opt/cloudera/parcels/CDH-5.13.1-1.cdh5.13.1.p0.2/lib/hadoop -Dhadoop.id.str= -Dhadoop.root.logger=INFO,console
-Djava.library.path=/opt/cloudera/parcels/CDH-5.13.1-1.cdh5.13.1.p0.2/lib/hadoop/lib/native -Dhadoop.policy.file=hadoop-policy.xml
-Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true
-Dhadoop.security.logger=INFO,NullAppender java_command: org.apache.hadoop.fs.FsShell
-mv hdfs://10.244.12.214:8020/serv/smartsteps/raw/events/locationev ent/2019/05/15/011/000150_0.gz hdfs://10.244.12.214:8020/serv/smartsteps/raw/events/locationevent/2019/05/15/011/./CD051201010101ASMARTSTEPS1805151000170000151.011.gz
当时的内存还很大:
------------ S Y S T E M ---------------
OS:CentOS Linux release 7.2.1511 (Core)
uname:Linux 3.10.0-327.el7.x86_64 #1 SMP Thu Nov 19 22:10:57 UTC
2015 x86_64
libc:glibc 2.17 NPTL 2.17
rlimit: STACK 8192k, CORE 0k, NPROC 4096, NOFILE 65535, AS
infinity
load average:46.84 11.88 4.02
/proc/meminfo:
MemTotal: 131464872 kB
MemFree: 107818664 kB
MemAvailable: 125719212 kB
BuffeRegionServer: 2220 kB
Cached: 17496468 kB
SwapCached: 0 kB
Active: 10411796 kB
查看某个 java 进程堆栈信息,因为内存足够故推断是第二种可能(黄色)
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Cannot create GC thread. Out of system resources. # Possible reasons:
# The system is out of physical RAM or swap space # In 32 bit mode, the process size limit was hit
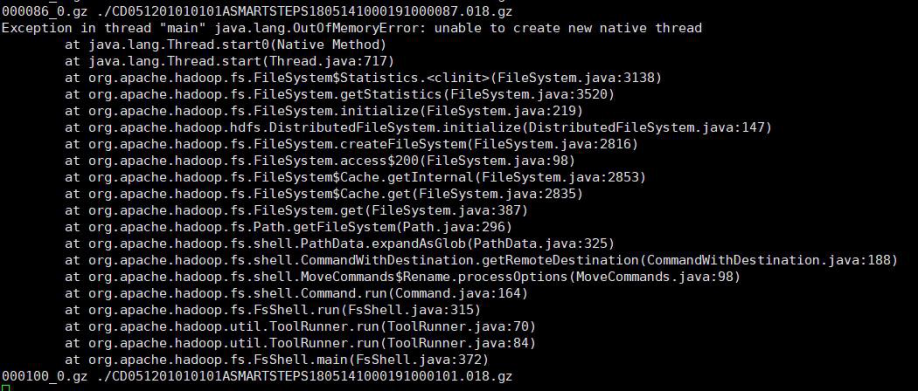
【解决方案】
用户可以启动的最大进程或线程数之前配置的是 1024,修改为 65535,在重新执行 150 个 mv 操作时正常
4.9、大数据作业JVM 内存崩溃 2
【现象】
今天 XXX 反馈在接口机 XXX 上做 hdfs dfs -mv(同时执行 150 个 mv)操作的时候出现了大量的类似 hs_err_pid3780.log(3780 代表 java 进程号)这样的文件,这个文件是 java 的致命错误日志,进程会直接崩溃。
【排查问题】
查看日志
jvm 某个错误日志在 14:02 生成,需要使用 352321536 byte = 344064k 的内存
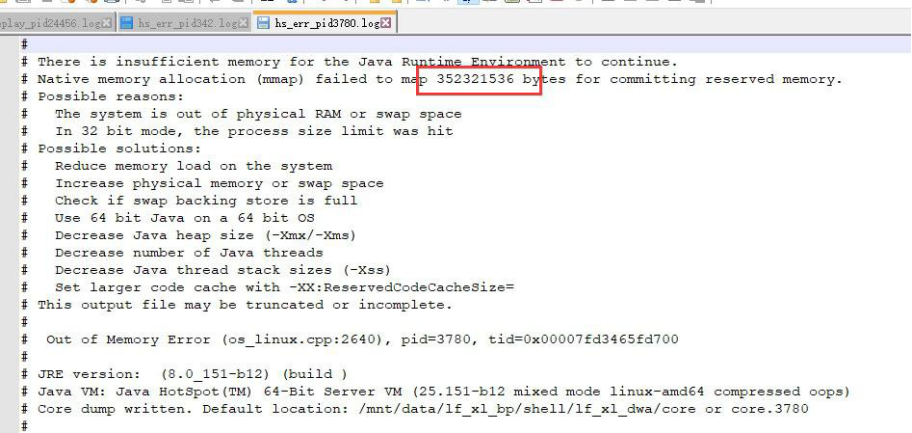
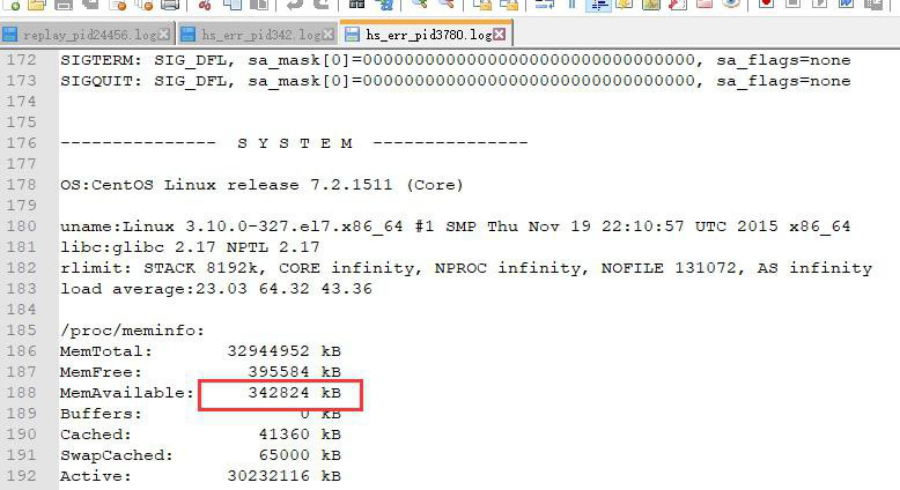
但是那时系统只剩下 342824k 内存,小于 344064k 的内存,故 jvm 崩溃,总结为:内存不足
【解决方案】
服务器扩内存或降低任务并发
4.10、集群作业数据倾斜任务排查
【现象】

作业监控发现作业存在数据倾斜
【问题排查】
在 YARN 监控页面查看作业信息查看 yarn 监控页面,此 job 共有 1009 个 reduce, 绝大部分 reduce 都是空跑没有处理数据
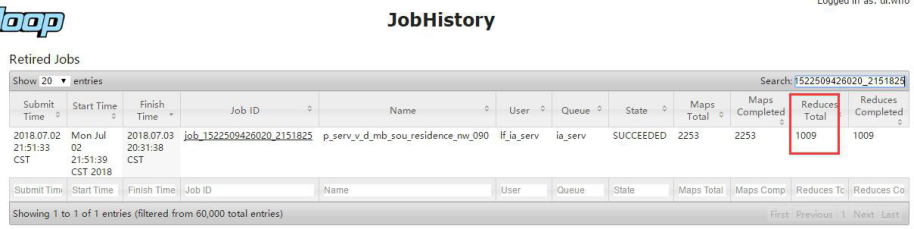
下面看一个执行时间很长的 reduce, 大概 18 个多小时

此 reduce 处理的数据量为:86.99 亿条
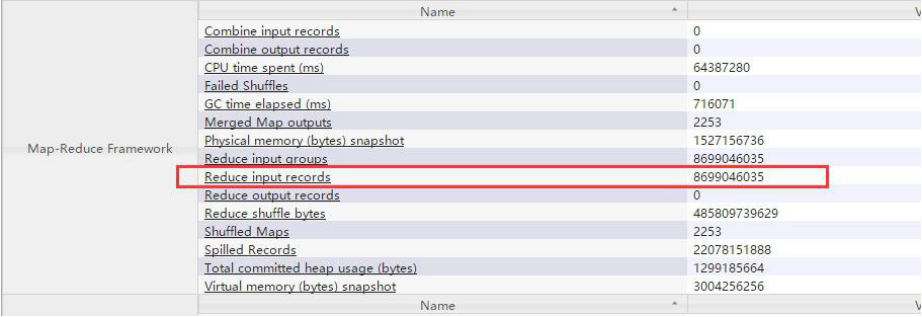
下面看一个执行时间短的 reduce, 大部分都在 3 分钟以内

处理的数据量为 0