我们以泰坦尼克号的获救信息为列
第一步:读取数据
import pandas as pd import numpy as np titanic = pd.read_csv('titanic_train.csv') #输出统计值 print(titanic.describe())
第二步:数据准备
1.对于数字型缺失,我们使用均值来填充缺失值,对于字母型缺失, 我们使用出现概率最大的字母来填充缺失值
2.为了便于计算我们需要把字母类型,转换为数字类型
#使用均值填充缺失值 titanic['Age'] = titanic['Age'].fillna(titanic['Age'].median()) #输出其中的类别 print(titanic['Sex'].unique()) #.loc取出对应的数据,前面一个参数是索引,后面是对应的属性,将字符串转换为数字类型 titanic.loc[titanic['Sex']=='male', "Sex"] = 0 titanic.loc[titanic['Sex']=='female', "Sex"] = 1 print(titanic['Embarked'].unique()) #存在缺失值, 字母的话,用出现次数最多的S补齐 titanic['Embarked'] = titanic['Embarked'].fillna('S') #将字母属性转换为数字属性 titanic.loc[titanic['Embarked']=='S', 'Embarked'] = 0 titanic.loc[titanic['Embarked']=='C', 'Embarked'] = 1 titanic.loc[titanic['Embarked']=='Q', 'Embarked'] = 2
第三步:算法尝试,我们使用了线性回归
#使用线性回归模型预测结果 from sklearn.linear_model import LinearRegression, LogisticRegression #导入交叉验证的库 from sklearn.cross_validation import KFold #测试样本的属性值 predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'] predictions = [] alg = LinearRegression() kf = KFold(titanic.shape[0], n_folds=3, random_state=1) #进行交叉验证分割,n_folds 表示分割的次数 # 做交叉验证 for train, test in kf: #建立测试样本参数 train_predictors = (titanic[predictors].iloc[train, :]) #建立测试样本的结果 train_target = titanic['Survived'].iloc[train] #建立模型 alg.fit(train_predictors, train_target) #使用分割的验证集进行样本预测, test_predictions = alg.predict(titanic[predictors].iloc[test, :]) #添加预测结果 predictions.append(test_predictions) predictions = np.concatenate(predictions, axis=0) #在一列上组合结果 #对predictions 进行分类 predictions[predictions > 0.5] = 1 predictions[predictions < 0.5] = 0 print(np.sum(predictions == titanic["Survived"])/len(titanic)) # 统计布尔值,计算结果
>>>0.78
第四步: 使用logistic做尝试,最后的结果与线性回归结果差不多
from sklearn import cross_validation from sklearn.linear_model import LogisticRegression #建立logstic模型 alg = LogisticRegression(random_state=1) #直接的交叉验证,scores为准确度 scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=3) #对score进行加和平均 print(scores.mean())
>>>> 0.78
第五步: 使用随机森林进行尝试,调整参数后,精度发生了一定的提升,关于随机森林的参数调节可以使用GridSearchCV
# 使用随机森林 from sklearn import cross_validation from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor #得到样本的参数名 predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"] # 建立树模型 alg = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2, min_samples_leaf=1) #交叉验证, 采用cross_validation.cross_val_score 直接获得交叉验证的准确度 kf = cross_validation.KFold(titanic.shape[0], n_folds=3, random_state=1) #交叉验证拆分 scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=kf) #对准确度求平均 print(scores.mean())
>>>>0.78 #这里我们调节了RandomForestClassifier的参数,重新验证 alg = RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=4, min_samples_leaf=2) predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"] kf = cross_validation.KFold(titanic.shape[0], n_folds=3, random_state=1) #进行了分割 print(kf) score = cross_validation.cross_val_score(alg, titanic[predictors], titanic['Survived'], cv=kf) print(score.mean())
>>>> 0.8154
第6步:我们探讨一下样本属性的重要性,以及对样本属性进行挖掘
1. 变量挖掘
#我们通过观察重新组合一个属性. titanic['FamilySize'] = titanic['SibSp'] + titanic['Parch'] #对于titanic['Name']使用lambda x:len(x)函数构成Namelength属性 titanic['Namelength'] = titanic['Name'].apply(lambda x:len(x)) # 引入正则表达式 import re #从名字中提取一个新的属性 def get_title(name): # Use a regular expression to search for a title. Titles always consist of capital and lowercase letters, and end with a period. title_search = re.search(' ([A-Za-z]+).', name) # If the title exists, extract and return it. if title_search: return title_search.group(1) return "" # 对名字选项使用get_title函数 titles = titanic["Name"].apply(get_title) print(pd.value_counts(titles)) #将字母类型转换为数字类型 title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Dr": 5, "Rev": 6, "Major": 7, "Col": 7, "Mlle": 8, "Mme": 8, "Don": 9, "Lady": 10, "Countess": 10, "Jonkheer": 10, "Sir": 9, "Capt": 7, "Ms": 2} #组合了一个关于名字的属性 for k, v in title_mapping.items(): titles[titles==k] = v #创建一个新的变量 titanic["Title"] = titles
2.评估样本属性的重要性
样本属性的重要性的评估,是通过给单个样本属性添加干扰值,分析前后的分类效果,如果分类效果不变就说明该样本属性不重要,否者就说明该样本是重要的
import numpy as np from sklearn.feature_selection import SelectKBest, f_classif import matplotlib.pyplot as plt predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked", 'Title', 'Namelength', 'FamilySize'] selector = SelectKBest(f_classif, k=5) #f_classif只适用与分类,k=5表示主要功能数量为5个 selector.fit(titanic[predictors], titanic['Survived']) score = -np.log(selector.pvalues_) #打印得分 plt.bar(range(len(score)), score) #做柱形图,第一个参数是横坐标,第二个参数是得分高度 plt.xticks(range(len(predictors)), predictors, rotation='vertical') #rotation 表示摆放位置是竖直的 plt.show()
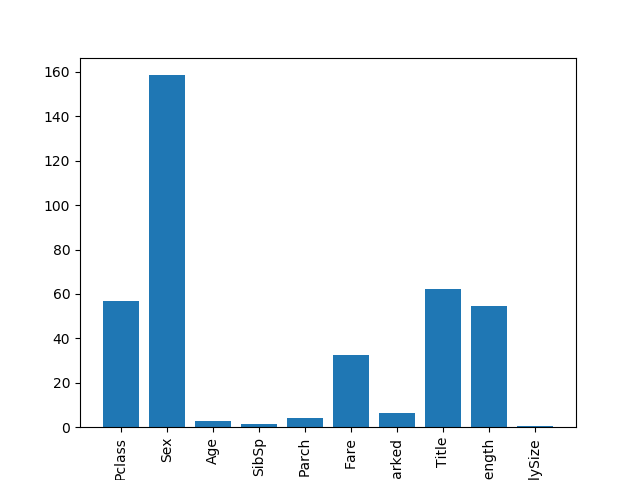
从图中我们可以看出pclass, sex, fare, title, Namelength五个属性的重要性较高,我们使用这四个属性进行再次的分析,我们发现只是提高了一点点的效果,呵呵了
#重新选择参数 predictors = ['Pclass', 'Sex', 'Fare', 'Title', 'Namelength'] alg = RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=4, min_samples_leaf=2) kf = cross_validation.KFold(titanic.shape[0], n_folds=3, random_state=1) #进行了分割 score = cross_validation.cross_val_score(alg, titanic[predictors], titanic['Survived'], cv=kf) print(score.mean())
>>>0.8159
第7步,只能放大招了,我们这里使用集成算法,我们使用梯度提升树 和 LogisticRegression,提高了一些精度,说明还是有效果的
from sklearn.ensemble import GradientBoostingClassifier import numpy as np # 算法集合:梯度提升树分类器 和 LogisticRegression algorithms = [ [GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3), ["Pclass", "Sex", "Age", "Fare", "Embarked", 'Title', 'FamilySize']], [LogisticRegression(random_state=1), ["Pclass", "Sex", "Age", "Fare", "Embarked", 'Title', 'FamilySize']] ] #交叉验证 kf = KFold(titanic.shape[0], n_folds=3, random_state=1) #进行分割 predictions = [] for train, test in kf: #训练集和测试集的分离 train_target = titanic['Survived'].iloc[train] #从原始样本分离train的Survived full_test_preditions = [] for alg, predictors in algorithms: alg.fit(titanic[predictors].iloc[train, :], train_target) #模型训练 # alg.predict_proba转换为概率,astype变为float类型 test_predictions = alg.predict_proba(titanic[predictors].iloc[test,:].astype(float))[:, 1] full_test_preditions.append(test_predictions) # test_predictions = (full_test_preditions[0] + full_test_preditions[1])/2 #增加梯度提升树分类器的权重 test_predictions = (full_test_preditions[0] * 3 + full_test_preditions[1]) / 4 # 把概率值转换为数值 test_predictions[test_predictions <=.5] = 0 test_predictions[test_predictions > .5] = 1 predictions.append(test_predictions) predictions = np.concatenate(predictions, axis=0) #将(3,291)二维转换为一维数据,(873,1)axis=0维度 print(np.sum(predictions == titanic["Survived"])/len(titanic)) # np.sum统计布尔值,计算结果
>>>82.5