测试用表A_用户表(test_table_A): 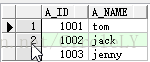
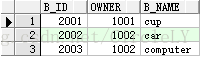
测试用表B_存储物品表(test_table_B):
1.exists操作
select *
from test_table_A A
where exists(
select 1
from test_table_B
where owner = A.A_id);1执行结果:
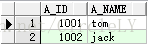
分步看其执行原理为:
1> 从表A中第一条数据1001 tom开始,进入exsits函数,获取表B中第一条数据2001 1002 cup,判断(B.owner = A.A_id)是否为true,此处为false,因此获取表B中第二条数据2002 1001 car,判断(B.owner = A.id)是否为true,此处为true,则显示表A中第一条数据,不继续与表B中第三条数据做判断。
2> 从表A中第二条数据1002 jack开始,进入exsits函数,获取表B中第一条数据2001 1002 cup,判断(B.owner = A.A_id)是否为true,此处为ture,则显示A中第二条数据,不继续与表B中后续数据做判断。
3> 从表A中第三条数据1003 jenny开始,进入exsits函数,获取表B中第一条数据2001 1002 cup,判断(B.owner = A.A_id)为false,获取表中第二条数据2002 1001 car,判断(B.owner = A.id)为false,获取表B中第三条数据2003 1002 computer,判断(B.owner = A.id)为false,至此已与表B中所有数据判断完毕,均为false,因此最终结果不显示该语句。
2.not exists
select *
from test_table_A A
where not exists(
select 1
from test_table_B
where owner = A.A_id);执行结果:
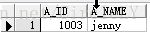
not exists操作即为反过来,当遇到true则不显示,全为false则显示。
3.exists与in的效率问题
使用EXISTS,会首先检查主查询,然后运行子查询,当子查询找到第一个匹配项时即开始下一次操作。
使用IN,会先执行子查询,并将获得的结果列表存放在一个加了索引的临时表中,再执行主查询与临时表运算。
结论:
1> select * from T1 where exists(select 1 from T2 where T1.a=T2.a) ;
2> select * from T1 where T1.a in (select T2.a from T2) ;
当T1数据量小而T2数据量非常大时(T1 << T2),即子查询更耗费时间时,exists的查询效率更高。
当T1数据量非常大而T2数据量小时(T1 >> T2),即主查询更耗费时间时,in 的查询效率高。