一、说明
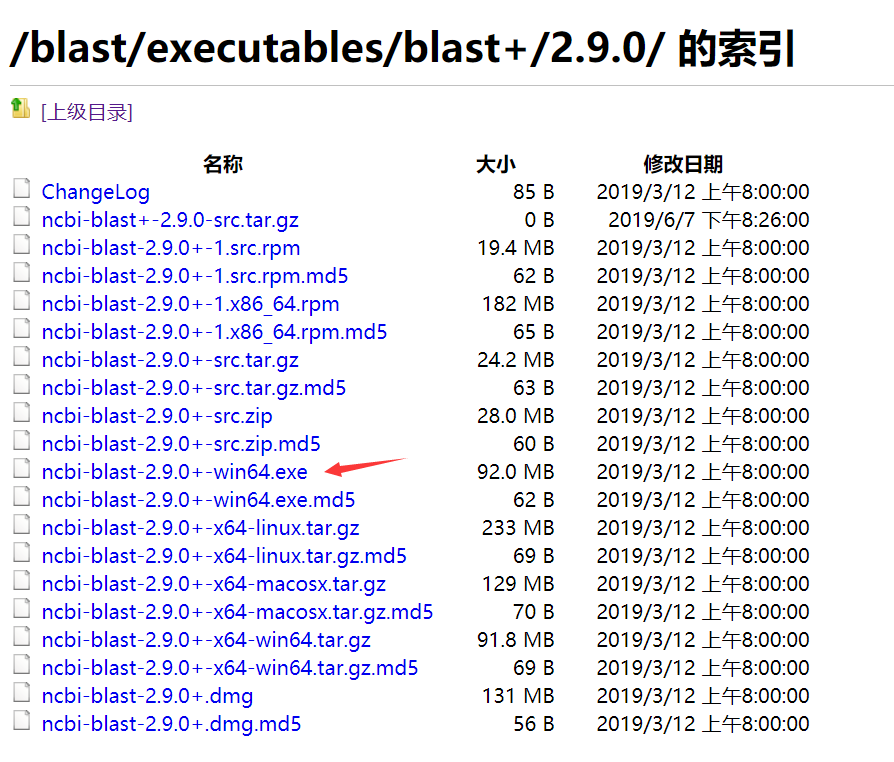
下载红箭头指向的文件
下载之后发现文件结果如下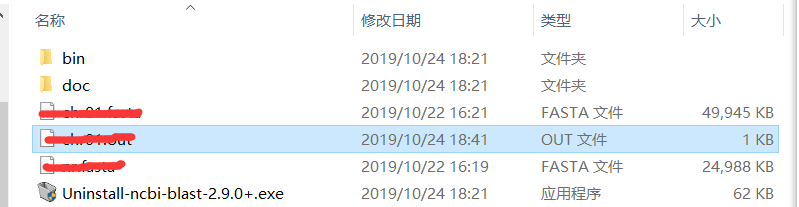
一个bin,一个doc,一个卸载程序,但是点开bin之后就懵了。bin中几乎一半都是exe文件,但是这些exe文件没有一个是打开这个程序的,都只是些命令程序。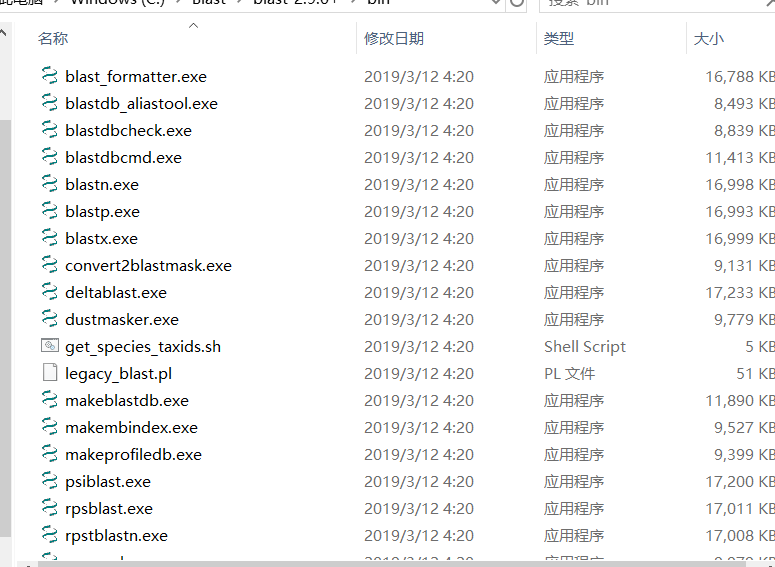
在用户环境中添加blastdb值与path值
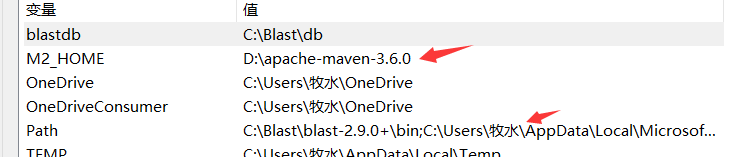

2.1在c盘下建立三个包

移动到blast有bin的包下,输入blastn -version来看是否安装成功
2.2创建db
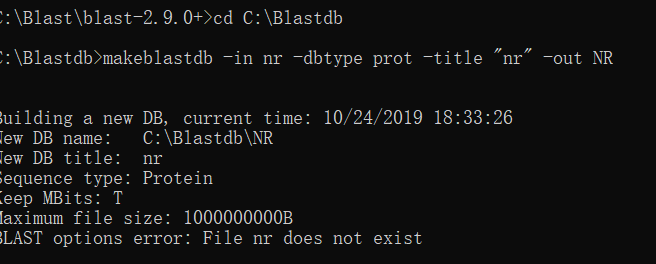
这个最后一个出问题了,它提示我File nr does not exist,然而我的nr文件是存在的。后来发现nr必须有文件后缀。(nr.fasta是要建成数据库的文件)
(建库命令:makeblastdb -in nr.fasta -dbtype prot -title "nr" -out NR)
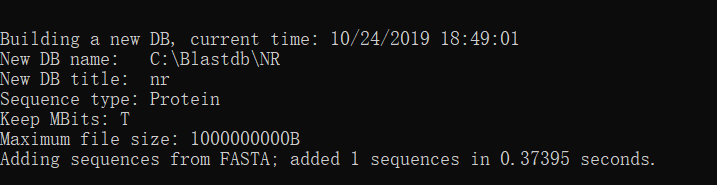
2.3建好库后测试
到这一步基本上在win下已经能够正常的调用blast来运行代码了。这些处理结果和输入参数看不明白,也不用看明白。
到这一步其实是有问题的,正常的话应该输出一个txt文件来显示结果。我又将两个比对文件放在ncbi的官网上试着比对了一下,发现这两个文件有问题,没法比对成功。
没办法只好再去找两个fasta的文件
方法:
1.https://www.ncbi.nlm.nih.gov/


将序列复制到文本中,将扩展名改为fasta类型。
如果只是测试软件能不能用,建议将得到的fasta文件建库,然后再用这个fasta文件与数据库对比。测试比较快。
三、使用blast
1.建库命令makeblastdb -in nr.fasta -dbtype prot -title "nr" -out NR
-in 建库的fasta文件
-dbtype 数据库类型 (-prot 蛋白质类型 -nucl 核苷酸类型)
-out 数据库名
2.查询
查询需要cd到要查询的fasta文件的路径下,调用查询命令blastp -query test2.fasta -db C:Blastdb est2.fasta -outfmt 6 -out "C:Blast est.blastp@iedb.txt" -evalue 0.00001 -max_target_seqs 5 -num_threads 8
-out "C:Blast est.blastp@iedb.txt" 输出类型可以添加路径名
输出txt文件的内容以-outfmt的类型为准,具体参数含义在模块四中
-outfmt 6 输出的txt文件中的各个信息为
Query_id Subject_id %_identity alignment_length mismatches gap_openings q. start q. end s. start s. end e-value bit_score
四、常用的blast命令
二、格式化数据库
基本运行指令
formatdb -i DBfile1 -p (T/F) -o (T/F)
-i:输入需要格式化序列库的绝对路径,序列库一般一般使用的是fasta文件。
-o [T/F]:判断是否分析序列名并建立序列名索引。“T”表示建立序列名索引,“F” 表示不建立序列名索引。默认值为F。
-p [T/F]:选择建库的类型,“T”表示建立的是蛋白质数据库,“F”表示建立的是核酸数据库,缺省值为T。
java代码
Process process = Runtime.getRuntime.eexec("formatdb -i DBFile -p T -o T");
process.waitFor(); //等待命令执行结束,获取执行结果
程序运行结束后,如果建立的是核酸库,-o为F时,会输出**.nhr,**.nin,**.nsp文件,-o为T时,还会多输出**.hsd,**.nsi,**.nni和**.nnd文件。类似的,当建立的是蛋白质也会输出相应的文件:[-o F]--**.phr,**.pin,**.psq;[-o T]--**.psd,**.psi,**.pni,**.pnd。
三、在数据库中查询相应序列并返回结果
1.基本运行指令:
blastp -query test2.fasta -db C:\Blast\db\test2.fasta -outfmt 6 -out "C:\Blast\testblastp@iedb.txt"
(文件名字最好加路径,否则得到的txt文件是在java项目的文件下方)
-evalue 0.00001 -max_target_seqs 5 -num_threads 8
2.blast主程序blastall
程序的输入文件是query序列(-i参数)库文件(-d)
选择(-p)和输出文件(-o)有用户绝定
-p有五种取值:百度查找
3.-e参数
筛选适当的比对结果,指定一个参数,选出比这个参数大的期望值
4. -F (T/F)参数
用来屏蔽简单重复和低复杂度序列的。
T:程序在比对过程中会屏蔽掉query中的简单重复和低复杂度序列
F:不会屏蔽
缺省值(默认值)为“T”。
5.-m参数
设定输出格式,供选择为0~11之间的整数。默认0.
6.-v,-b参数
-v 默认值500,规定输出中的每一个query的比对列表最多显示subject的个数
-b 默认250,规定输出中每个query最多显示与多少subject的比对条形图
7. -T 参数
用于决定是否输出html格式的比对结果。
9.-W参数
指定坐比对的字的长度。
四、java程序中调用blast
java调用命令行代码
唯一一个小点是需要多行调用命令行命令
在命令行中,如果调用多条命令,在两个命令之间加上&
如 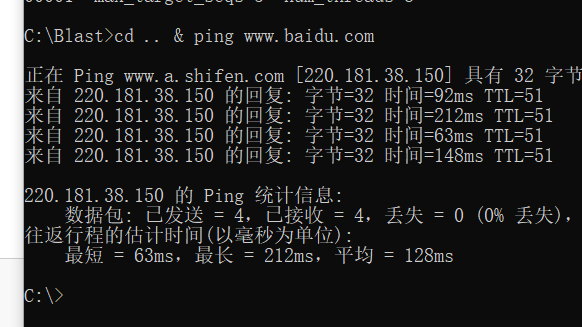
但是在java中,需要有cmd /c (执行完命令行后关闭命令框),cmd /k(执行完命令行后不关闭命令框)
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class blast {
public static void main(String[] args) {
Runtime run = Runtime.getRuntime();
try {
Process process = run.exec("cmd /k C: && cd C:\Blast && blastp -query test2.fasta -db C:\Blast\db\test2.fasta -outfmt 5 -out "C:\Blast\test.blastp@iedb.xml" -evalue 0.00001 -max_target_seqs 5 -num_threads 8 " );
InputStream input = process.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(input));
String szline;
while ((szline = reader.readLine())!= null) {
System.out.println(szline);
}
reader.close();
process.waitFor();
process.destroy();
} catch (Exception e) {
e.printStackTrace();
}
}
}
至此,blast的下载,使用,调用三个部分基本上结束了。
接下来就需要将获得的文件可视化。
之前导出的格式是由 -outfmt 5获得的,然而这个输出的是xml文件,在网上也找不到相应的将xml文件转成能看懂形式的教程文章。不过我找到了一个blastxml插件,有大佬会的话希望能教一下。
链接如下http://hackage.haskell.org/package/blastxml
既然-outfmt的输出格式有许多那可以曲线救国换其他的用。
-outfmt 6 得到的格式为txt文件,对应blast中的m8.
每一列的对应数据解释为:
Query_id Subject_id %_identity alignment_length mismatches gap_openings q. start q. end s. start s. end e-value bit_score
Query id:查询序列ID标识
Subject id:比对上的目标序列ID标识
% identity:序列比对的一致性百分比
alignment length:符合比对的比对区域的长度
mismatches:比对区域的错配数
gap openings:比对区域的gap数目
q. start:比对区域在查询序列(Query id)上的起始位点
q. end:比对区域在查询序列(Query id)上的终止位点
s. start:比对区域在目标序列(Subject id)上的起始位点
s. end:比对区域在目标序列(Subject id)上的终止位点
e-value:比对结果的期望值,将比对序列随机打乱重新组合,和数据库进行比对,如果功能越保守,则该值越低;该E值越高说明比对的高得分值是由GC区域,重复序列导致的。对于判断同源性是非常有意义的几个参数。
bit score:比对结果的bit score值
(引用链接http://www.mamicode.com/info-detail-2420033.html)
再然后用java代码调用
public static void main(String[] args) {
ArrayList<String> arrayList = toArray("C:\Blast\test.blastp@iedb.txt");
for(String str:arrayList){
System.out.println(str);
}
}
public static ArrayList<String> toArray(String name){
ArrayList<String> arrayList = new ArrayList<>();
try {
FileReader fr = new FileReader(name);
BufferedReader bf = new BufferedReader(fr);
String str;
while ((str = bf.readLine())!=null){
arrayList.add(str);
}
bf.close();
fr.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return arrayList;
}

至此,blast从windows下载,建库,指令,对比,显示就都结束了。剩下的就只剩另一个同学导入项目中了。
但是老师还有两个文件要用...../(ㄒoㄒ)/~~