统计学生成绩
学生的成绩清单格式如下所示,第一行为表头,各字段意思分别为学号、性别、课程名
1、课程名 2 等,后面每一行代表一个学生的信息,各字段之间用空白符隔开
Id gender Math English Physics
301610 male 80 64 78
301611 female 65 87 58
给定任何一个如上格式的清单(不同清单里课程数量可能不一样),要求尽可能采用函数式编程,统计出各门课程的平均成绩,最低成绩,和最高成绩;另外还需按男女同学分开,分别统计各门课程的平均成绩,最低成绩,和最高成绩。
测试样例 1 如下:
Id gender Math English Physics
301610 male 80 64 78
301611 female 65 87 58
301612 female 44 71 77
301613 female 66 71 91
301614 female 70 71 100
301615 male 72 77 72
301616 female 73 81 75
301617 female 69 77 75
301618 male 73 61 65
301619 male 74 69 68
301620 male 76 62 76
301621 male 73 69 91
301622 male 55 69 61
301623 male 50 58 75
301624 female 63 83 93
301625 male 72 54 100
301626 male 76 66 73
301627 male 82 87 79
301628 female 62 80 54
301629 male 89 77 72

测试样例 2
Id gender Math English Physics Science
301610 male 72 39 74 93
301611 male 75 85 93 26
301612 female 85 79 91 57
301613 female 63 89 61 62
301614 male 72 63 58 64
301615 male 99 82 70 31
301616 female 100 81 63 72
301617 male 74 100 81 59
301618 female 68 72 63 100
301619 male 63 39 59 87
301620 female 84 88 48 48
301621 male 71 88 92 46
301622 male 82 49 66 78
301623 male 63 80 83 88
301624 female 86 80 56 69
301625 male 76 69 86 49
301626 male 91 59 93 51
301627 female 92 76 79 100
301628 male 79 89 78 57
301629 male 85 74 78 80

scala容器
容器基础语法1
1.元组:
Tuple1 - Tuple22
1.1
若干个单个的值包含在圆括号便构成元组:
eg:
val g=(1 , 1.2,'A') 三元 元组 //(Int,Double,Char)类型的元组
1.2
映射是二元的元组,元组是不同类型的值的聚集
("key",value) n=2
1.3
//利用方法_1、_2、_3访问元组的组元
val h=g._1 或 val h=g _1
//或者利用隐式的模式匹配
val (first,second,three)=(1,3.14,"Free");
val (first,second,_)=(1,3.14,"hhhhhhhhhhhh")
val (name,age,phone,address)=("tom",23,110,"南昌")
1.4
元组可以用于函数需要返回不止一个值得情况。
举例来说,StringOps的partition方法返回的是一对字符串,分别包含了满足某个条件和不满足条件的字符:"New York".partition(_.isUpper)
1.5
注意区分下边两个的不同
val x,y,z=(1,"hello",2)
val (x,y,z)=(1,"hello",2)
2.映射:
Map(Map集合中每个元素是一个二元元组)
2.1
二元元组的表示方法:
(key,value) 或 key -> value
2.2
分为可变映射和不可变映射
mutable.Map[K,V]
immutable.Map[K,V]
Map <==> immutable.Map <==> Predef.Map
注意:
scala.collection.Map 是immutable.Map和mutable.Map的超类
Scala优先采用不可变集合, scala.collection 包中的伴生对象产出不可变的集合
2.3
构建Map映射对象
Map 是一个trait 和 object
因此构建方式只有:统一对象构建原则
Map(elem1,elem2,elem2,...)
<===>
Map.apply(elem1,elem2,elem2,...)
2.4
构建一个空集合,可以使用empty方法
import scala.collection.mutable;
val mutableMap=mutable.Map.empty[K,V]
注意:
val map=muatble.Map();
val map=mutable.Map[K,V]();
//请自行测试这两个map集合的区别。(Nothing是所有类的子类,最底层类)
2.5
通过key获取value值
三种方式:
map.apply(key)
map.get(key)
map.getOrElse(key,defaultValue)
2.6
Option(类似于集合的类)
当前对象中只包含0个或1个元素。
子类:
Some(elem)
None
从Some中取值使用 get
注意:
Option类是为了避免出现NullPointerException而设计。
2.7
添加元素
- ++ ++: (+= ++=) insert insertAll append appendAll
2.8
移除元素
- -- (-= --=) remove drop dropRight
2.9
遍历集合
eg:
for(elem <- map){
val key=elem._1
val value=elem._2
}
//或:
for( (key,value) <- map ){
println(key+":"+value)
}
//只遍历key值
map.keys
map.keySet
map.keysIterator
//只遍历value值
map.values
map.valuesIterator
2.10
拉链操作
zip 将两个集合进行“等值连接”
zipAll 将两个集合进行“全连接”,三个参数,第一个参数为连接的集合;第二个参数为原集合元素不足时的补位元素;第三个参数为连接集合元素不足时的补位元素;
zipWithIndex 将集合中的每个元素变成一个二元元组,二元元组的_2即位当前元素在集合中的索引。
unzip 将容器中的二元元组拆分,将每个二元元组中的_1放到一个集合中,_2的放到一个集合中。即拆分成两个集合。
unzip3 将容器中的三元元组拆分,将每个三元元组中的_1放到一个集合中,_2的放到一个集合中,_3的放到一个集合中。即拆分成了三个集合。
eg:
val price=List(2,10,8)
val num=List(10,10,10)
val collection=list1.zip(list2)
val newColl=for( (price,num) <- collection )yield{
price*num
}.sum
val count=collection.map(x=> x._1*x._2).sum
3.集合
1.集合分为:
序列 集 映射
Traversable(Trait)
|
Iterable(Trait)
———————————————————————————-
| | |
Seq Set Map(Trait/object)
2.Seq
是一个有先后次序的值得序列,允许存放重复元素。
2.1整体上分为:
索引序列IndexedSeq,线性序列(链表)LinearSeq.
Seq
———————————————————————————-
| | |
IndexedSeq Buffer LinearSeq
| | |
Array Vector Range | List LinkedList
String StringBulid ArrayBuffer ListBuffer Queue Stack Stream View
IndexSeq索引序列:
允许我们通过整型的下标快速访问任意元素,如ArrayBuffer是带下标的。
LinearSeq线性序列:
被分为了头尾部分,并且用head,tail和isEmpty方法等。
注意:
Array其实不是真正的序列,是通过将Array包装成WrappedArray(mutable),才可以像集合一样使用。
3.Set
Set是一组没有重复元素的集合。
Set
———————————————————————————
| | | |
BitSet HashSet ListSet SortedSet
|
TreeSet
在SortedSet中,元素以某种排过序的顺序被访问。
4.Map
Map是一组(K,V)对偶,其中键必须是唯一的。
Map
———————————————————————————
| | | |
HashMap LinkedListMap ListMap SortedMap
TreeMap
SortedMap按照键的排序访问。
5.
每个Scala集合特质或类,都有一个带有apply方法的伴生对象,这个apply方法可以用来构建该集合中的实例。
eg:
Iterable(0xFF, 0xFF00, 0xFF0000)
Seq(color.RED, color.GREEN, Color.BLUE)
Map(color.RED -> -0xFF0000, Color.GREEN -> 0xFF00, Color.BLUE -> 0xFF)
SortedSet("Hello" , "World") 最终代码:


1 package Stuachievement 2 object Thefirst { 3 def main(args:Array[String]) 4 { 5 6 var ii=1 7 do{ 8 println("样例"+ii+":") 9 val inputFile=scala.io.Source.fromFile("test"+ii+".txt") 10 val originalData=inputFile.getLines.map{_.split{"\s+"}}.toList 11 val courseNames=originalData.head.drop(2) 12 val allStudents=originalData.tail 13 val courseNum=courseNames.length 14 def statistc(lines:List[Array[String]])= 15 { 16 17 (for(i<- 2 to courseNum+1) yield 18 { 19 20 val temp =lines map 21 { 22 elem=>elem(i).toDouble 23 } 24 (temp.sum,temp.min,temp.max) 25 })map{case(total,min,max)=>(total/lines.length,min,max)} //最后一个map对for的结果进行修改,将总分转为平均分 26 } 27 28 def printResult(theresult:Seq[(Double,Double,Double)]) 29 { 30 31 (courseNames zip theresult)foreach 32 { 33 case(course,result)=> 34 println(f"${course+":"}%-10s${result._1}%5.2f${result._2}%8.2f${result._3}%8.2f") 35 } 36 } 37 38 val allResult=statistc(allStudents) 39 println("course average min max") 40 printResult(allResult) 41 42 val (maleLines,femaleLines)=allStudents partition 43 { 44 _(1)=="male" 45 } 46 47 val maleResult=statistc(maleLines) 48 println("course average min max (males)") 49 printResult(maleResult) 50 51 val femaleResult=statistc(femaleLines) 52 println("course average min max (females)") 53 printResult(femaleResult) 54 ii=ii+1 55 println() 56 }while(ii!=3) 57 58 } 59 60 }
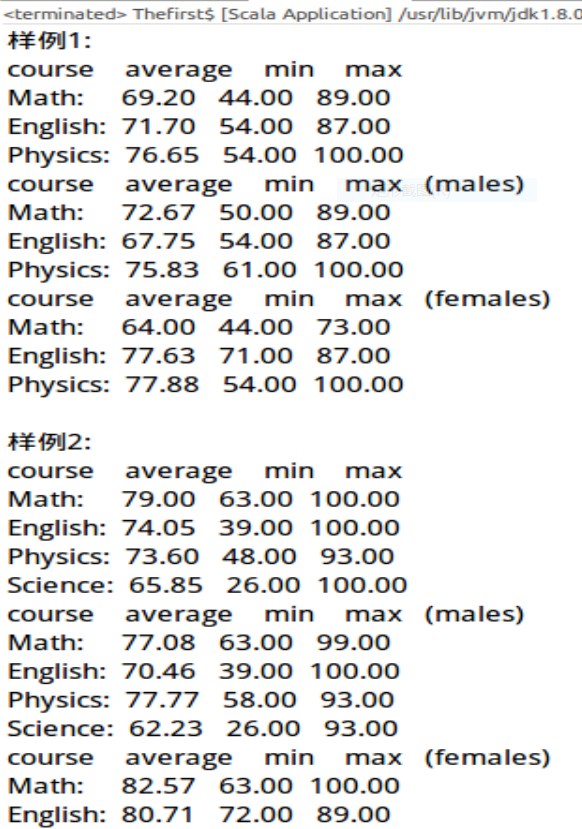
最终结果: