实例
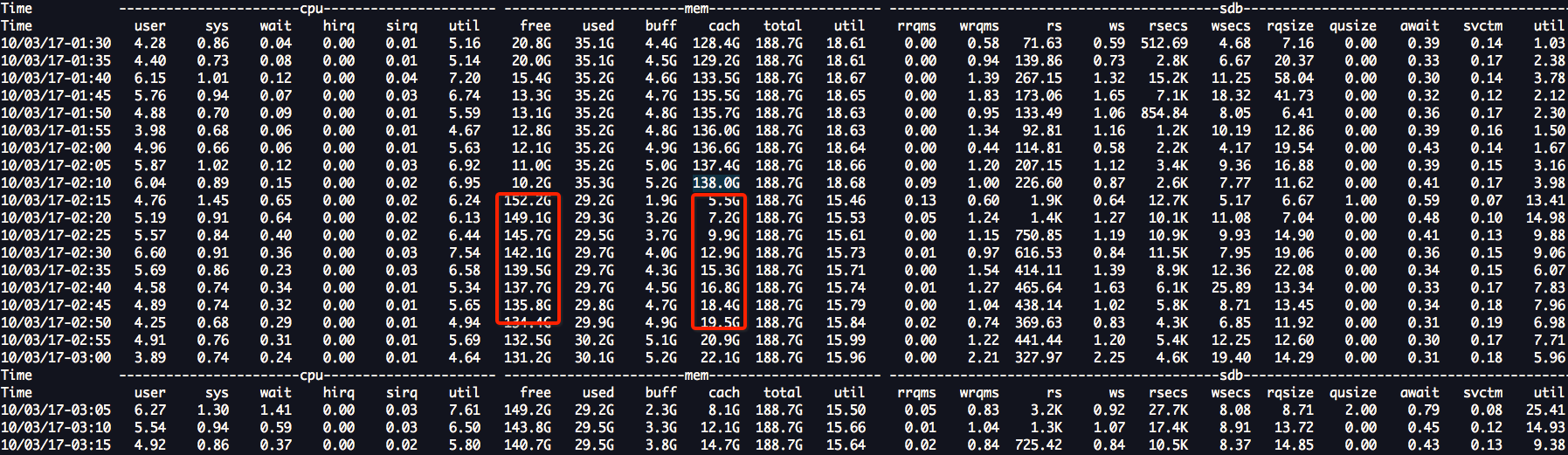
git server是一个io密集型的服务,当cache量很大的时候,cache会全部一次释放,导致那么一瞬间,IO read压力很大,因为,用户的大量请求,需要重新从磁盘读到内存,但是这个时刻,CPU的使用率也只有28%,可见,CPU的使用率虽然低,但是IO已经到达瓶颈,如果,kernel管理内存方式中有没有一种机制,可以控制cache释放多少?比如他们现在一下子cache释放150G,有什么参数可以修改一下,cache一次只回收50G,我想可以很大程度上改善这个问题,如果没有这个机制,也许只有扩容了。。。。
min
从上文中,可以看出min的值,决定了low的值,和high的值;其计算关系就是:
watermark[min] = min_free_kbytes换算为page单位即可,假设为min_free_pages。(因为是每个zone各有一套watermark参数,实际计算效果是根据各个zone大小所占内存总大小的比例,而算出来的per zone min_free_pages)
watermark[low] = watermark[min] * 5 / 4
watermark[high] = watermark[min] * 3 / 2
修改min_free_kbytes的值在这里:
[root@muahao_host /home/ahao.mah]
#cat /proc/sys/vm/min_free_kbytes
3145728
/proc/zoneinfo 文件中的单位是page,page的大小是4KB
[root@muahao_host /home/ahao.mah]
#cat /proc/zoneinfo | grep min
min 63
min 7139
min 779229
[root@muahao_host /home/ahao.mah]
#echo "3145728/4" |bc
786432
[root@muahao_host /home/ahao.mah]
#echo "63+7139+779229" |bc
786431
如上,计算出来,/proc/sys/vm/min_free_kbytes 的值和zoneinfo中的值是基本一致的!!
如下,计算min的值,居然只有2GB这让我很疑惑!!!
[root@muahao_host /home/ahao.mah]
#echo "(63+7139+779229)*4/1024/1024" |bc
2
low
[root@muahao_host /home/ahao.mah]
#cat /proc/zoneinfo | grep low
low 78
low 8923
low 974036
[root@muahao_host /home/ahao.mah]
#echo "78+8923+974036" |bc
983037
[root@muahao_host /home/ahao.mah]
#echo "(78+8923+974036)*4/1024/1024" |bc
3
high
[root@muahao_host /home/ahao.mah]
#cat /proc/zoneinfo | grep high
high 94
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high: 0
high 10708
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high 1168843
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
high: 186
[root@muahao_host /home/ahao.mah]
#cat /proc/zoneinfo | grep high | grep -v :
high 94
high 10708
high 1168843
[root@muahao_host /home/ahao.mah]
#echo "(1168843+10708+94)*4/1024/1024" |bc
4
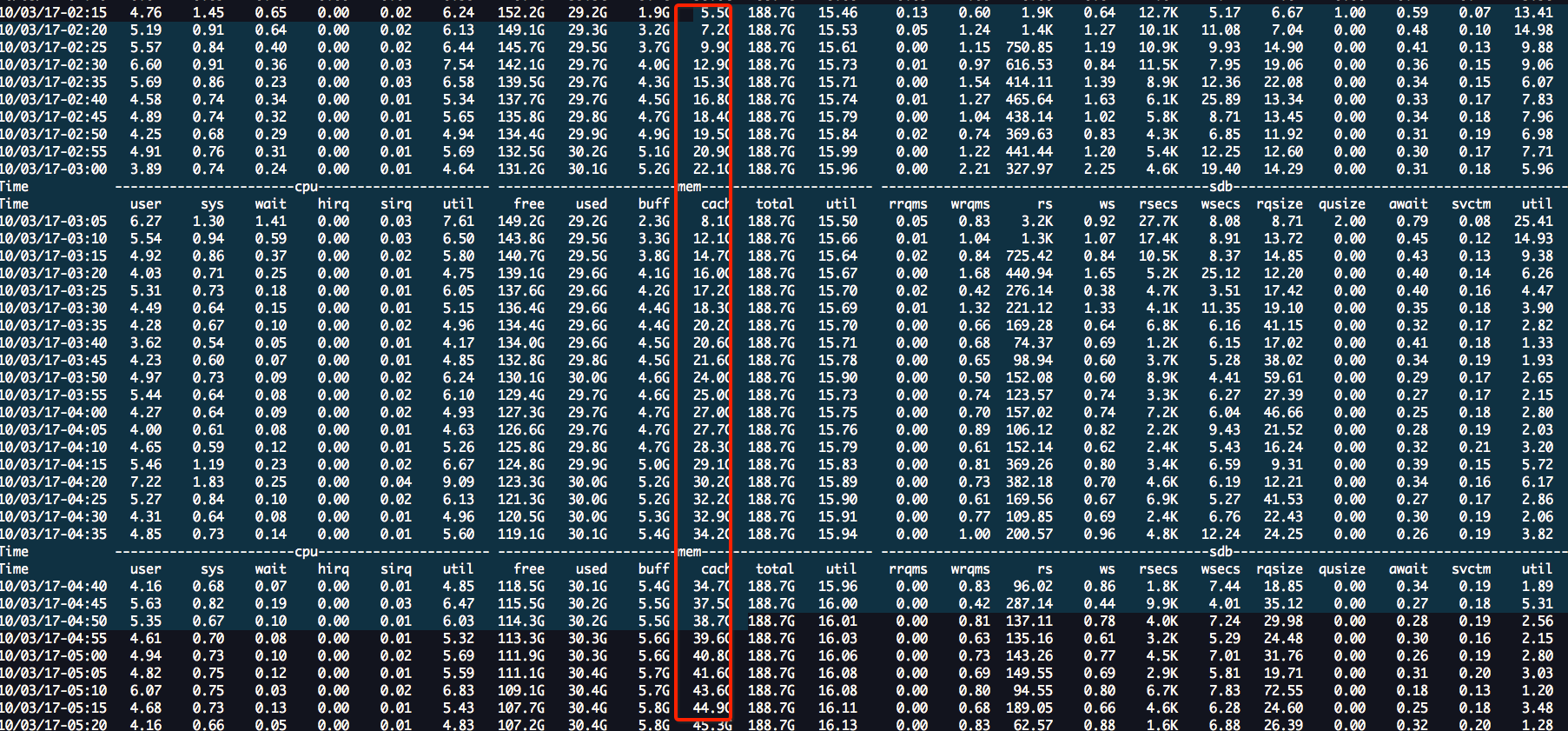
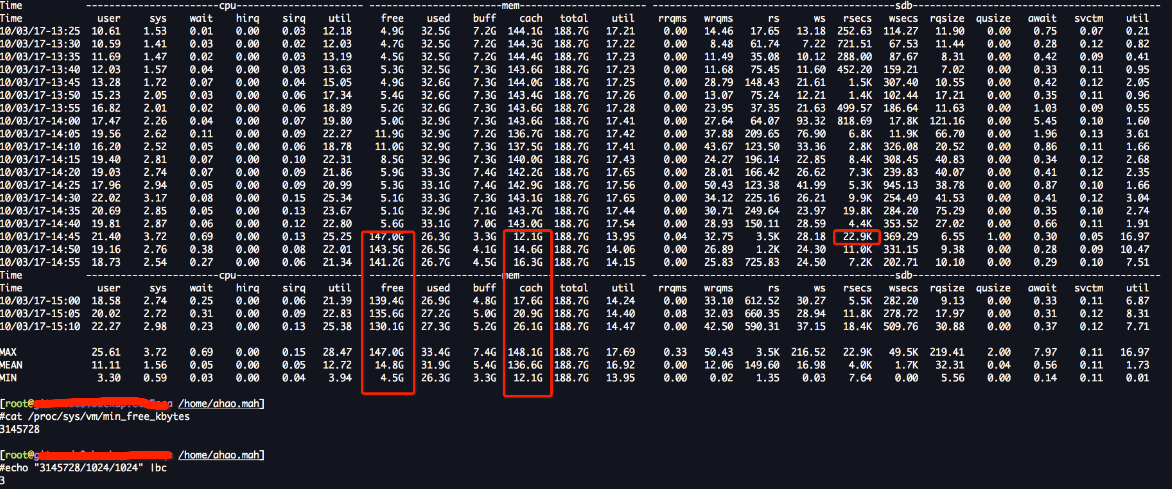
下图是我一直很疑惑的地方!为什么会在free只剩下5G的时候开始回收? 按道理应该到low值的时候开始使用kswapd回收呀,那么这里的low值应该是3G呀?看tsar的图,应该还没有到low值就回收了,唯一可能的原因也许是,不是kswapd回收的,而是,用户请求的内存过大,直接触发了direct claim可能,但是,果direct claim的话,是不是就不关系 high water mark了?也许只有这样才能解释的通!!!
Q1: 这个里的回收是swapd呢?还是direct claim呢?
A: 这里我看像是direct claim,因为,还没有大low值,回收就开始了;
Q2: 如果是direct claim,kernel这个机制会回收那么多?还遵循水位吗?直接从140G到12G是不是有点不科学?
A: 经过和同事的讨论,他认为direct claim回收,其实也不是一次全部回收,只要满足kernel的内存请求,也就会适可而止了,那么该如何解释我这里的140G到12G这么大力度的回收呢?原因也许只有一个,内存碎片化太严重!!而你请求的又是很大的连续的地址,第一次释放了一些cache,发现没有,即使释放50G cache可能都不行,关键是,释放的内存地址都不连续啊,有个毛用!! 如果你请求order是3,那么就是8个连续的page,一个page 是4KB,那么这么长的连续的地址,在内存中是很少的,你可以通过看/proc/buddyinfo来看,内存的碎片程度!!
看buddyinfo的时候,我们就看 Normal,碎片很严重的时候,可能就后面几个数字都是0;
#cat /proc/buddyinfo
Node 0, zone DMA 1 1 0 0 2 1 1 0 1 1 3
Node 0, zone DMA32 190 202 132 186 539 712 463 230 77 51 65
Node 0, zone Normal 13000 21608 30616 8586 8695 8090 2093 2123 410 119 1
回头再看看我的问题,我从140G掉到5G,是在5分钟内完成,/03/17-02:15 到10/03/17-10:55 经历了大概8个小时,cache从5G涨到140G,140G继续持续跑了几天后,不知道在什么时候,某一个瞬间,从140G瞬间跌倒5G,这个现象更像是,内存碎片很严重,到某个时间点,来了一些连续内存请求,导致,cache大量回收!!!想找到根本原因,可以部署扁鹊,或者用sysdig去查看到底执行了什么函数,在那个时间点