- 所谓的平行语料,比如中文到英文的这样一种对等翻译;
无论 CNN 还是 RNN,LSTM,既然是深度学习,也即较深的网络层次,显然训练将是一个十分耗时的过程,所要学习的参数的数量将十分可观,如果不对网络的拓扑结构以及训练方法进行适当的优化的话,显然在实际中将是十分不可行。
- CNN:图像
- conv+maxpooling:共享参数
- RNN:模拟 sequence to sequence 的学习
- 既然是一种映射关系,便可以是各种各样的映射
- translation(tensorflow 已经给出相关实现),需要平行语料,
- 传统的统计机器翻译(SMF)需要极多的平行语料
- sequence generation,生成,就是生成一种
- web-document ⇒ query
- 自然语言处理(NLP),文本,问答(看图说话)
- 既然是一种映射关系,便可以是各种各样的映射
1. 从 BP 神经网络到 RNN
传统的神经网络,甚至包括 CNN,都是假设输入和输出之间都是独立的,比如图像上的猫和狗是彼此独立的,但对另外的有些任务而言,后续的输出和之前的内容是相关的:
- 我是中国人,我的母语是____;
RNN 由此引入了“记忆(memo)”的概念,
- R,Recurrent,循环来源于其每个元素都执行相同的任务(由此便可以共享参数);
但是输出依赖于输入和“记忆”;
- x 表示输入;
- o 表示输出;
- 圆弧表示循环;
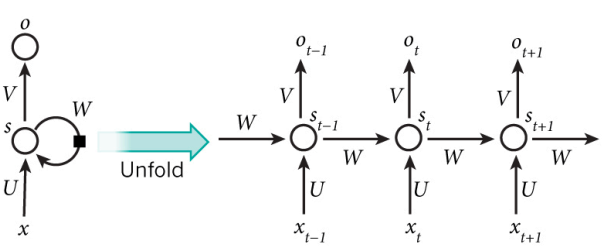
3. RNN 的定量分析
- 循环神经网络中的状态(state)通过一个向量来表示,这个向量的维度也称为循环神经网络隐藏层的大小,不妨假定其为
h 。 - 循环体中的神经网络的输入有两部分,一部分为上一时刻的状态(
ht−1 ),另一时刻为当前时刻的输入样本(xt )
- 对于时间序列数据来说,比如不同时刻商品的销量,则每一个时刻的输入样本可以是当前时刻的数值(如销量值),也即可以是标量;
- 对于语言模型而言,输入样本可以是当前单词对应的单词向量(word embedding)
- 如果输入向量的维度为
x ,RNN 循环体的全连接层
- 全连接层的输入大小为:
h+x ,可以理解为将上一时刻的状态(ht−1 )与当前时刻的输入(xt )拼接成一个大的向量而作为循环体中神经网络的输入; - 因为该神经网络的输出为当前时刻的状态,则此输出层的节点个数为
h , - 此循环体的参数个数为:
(h+x)×h+h
- 全连接层的输入大小为: