caffe中训练和测试mnist数据集都是批处理,可以反馈识别率,但是看不到单张样本的识别效果,这里使用windows自带的画图工具手写制作0~9的测试数字,然后使用caffemodel模型识别。
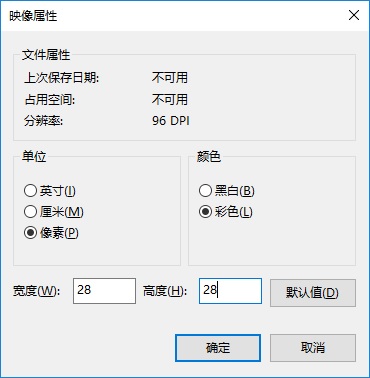
1. 打开画图工具,设置画板宽高为28*28,然后分别画出0~9的数字,分别保存为0~9.bmp文件。
宽高属性修改:
手写的10个数字:
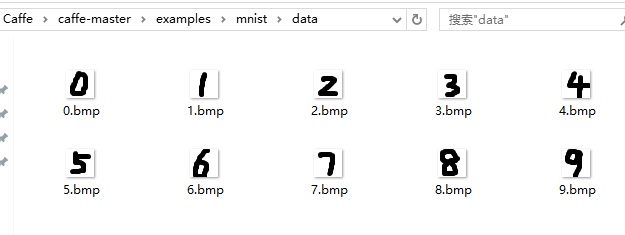
画图工具保存的这10张手写数字图像是彩色三通道的,需要转换成单通道灰度图像,这个转换可以通过OpenCV完成。
2. 使用OpenCV转换灰度图像
OpenCV的imread函数的第二个参数设置为0,会把读入的图像自动转换成灰度图像。
强调一点是,mnist的训练和测试数据集都是黑底白字的,而用画图制作的图像是白底黑字的,所以要做一个底色的变换,要不然识别率很低。以下是处理程序:
#include <iostream>
#include <highgui/highgui.hpp>
#include <imgproc/imgproc.hpp>
using namespace std;
using namespace cv;
void main()
{
Mat image;
stringstream str;
//0~9.bmp图像保存路径
string pathFile = "D:\Software\Caffe\caffe-master\examples\mnist\data\";
string s;
for (int i = 0; i < 10; i++)
{
str.clear();
str << i;
string str1;
str >> str1;
s = pathFile + str1;
s += ".bmp";
image = imread(s, 0);
threshold(image, image, 0, 255, CV_THRESH_OTSU);
//图像做底色反转变换
image = ~image;
//转换的二值图像保存在同一个文件夹下,在名称前加0区分
s = "";
s = pathFile + "0" + str1+".bmp";
imwrite(s, image);
}
}完成之后在data目录下新生成00~09.bmp(黑底白字)共10个二值图像。
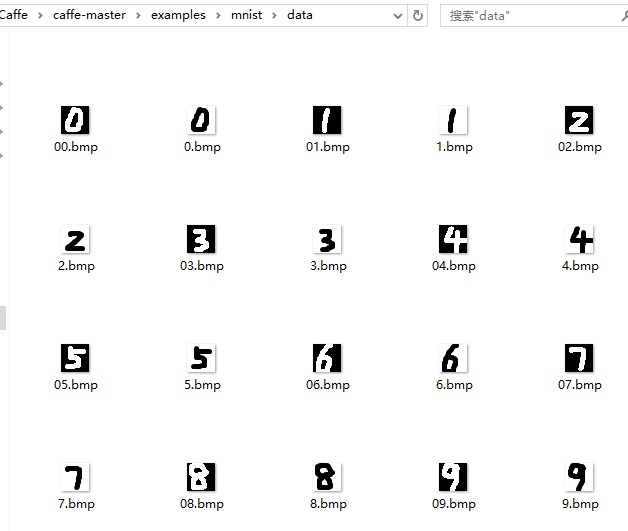
3. 单张手写样本测试
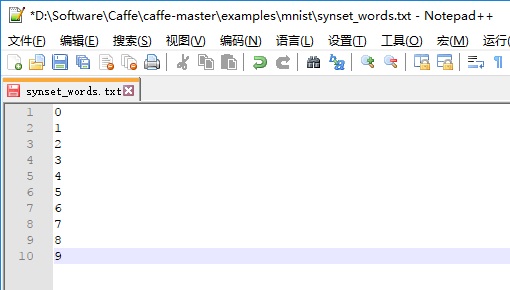
在.examplesmnist目录下新建一个标签文件synset_words.txt,输入以下内容:
在caffe-master目录下新建一个mnist-class.bat脚本文件,输入以下内容:
for /l %%i in (0,1,9) do (.Buildx64Debugclassification.exe .examplesmnistlenet.prototxt .examplesmnistCaffeModellenet_iter_10000.caffemodel .examplesmnistmean.binaryproto .examplesmnistsynset_words.txt .examplesmnistdata�%%i.bmp
)
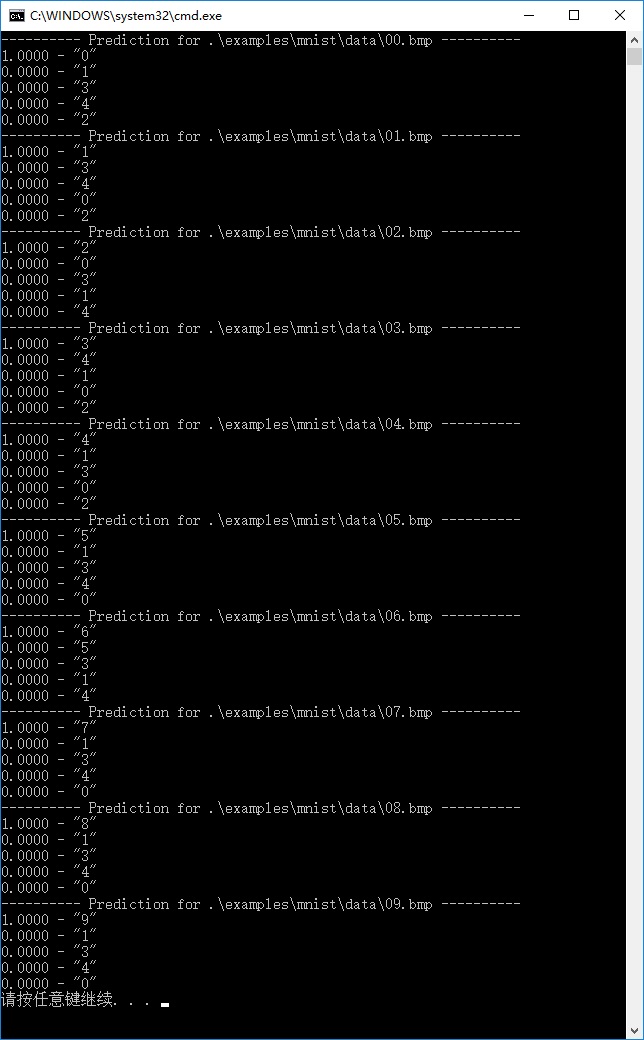
pause双击运行,得到识别结果,0~9都可以正确识别: