主要介绍如何抓取app数据及抓包工具的使用,能看到这相信你已经有爬虫基础了
编不下去了,主要是我懒,直接开干吧!
一.使用环境和工具
windows + python3 + Jsonpath + Charles + MuMu模拟器
二.下载工具
Charles下载:https://www.charlesproxy.com/latest-release/download.do
MuMu模拟器:http://mumu.163.com/baidu/
三.安装及配置工具
Charles
安装,直接傻瓜式安装就行
配置:
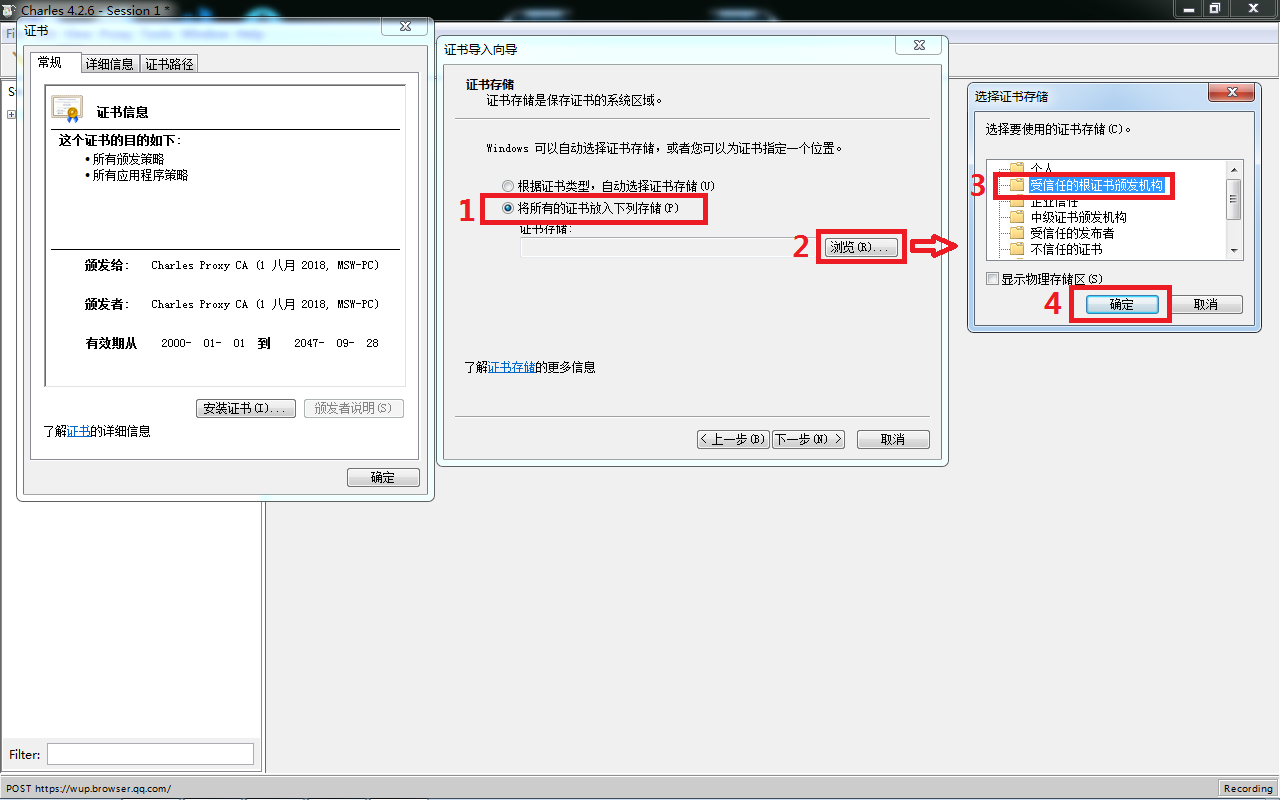
1.打开Charles->点击Help->SSL Procying->Install Charles Root Certificate,即可进入证书安装界面

2.安装证书->下一步->将所有的证书都放入下列存储(P)->浏览->受信任的根证书颁发机构->确定->下一步->完成

3.可设置端口号,一般为默认(如果系统没有其他软件与8888端口冲突,可忽略该步骤)

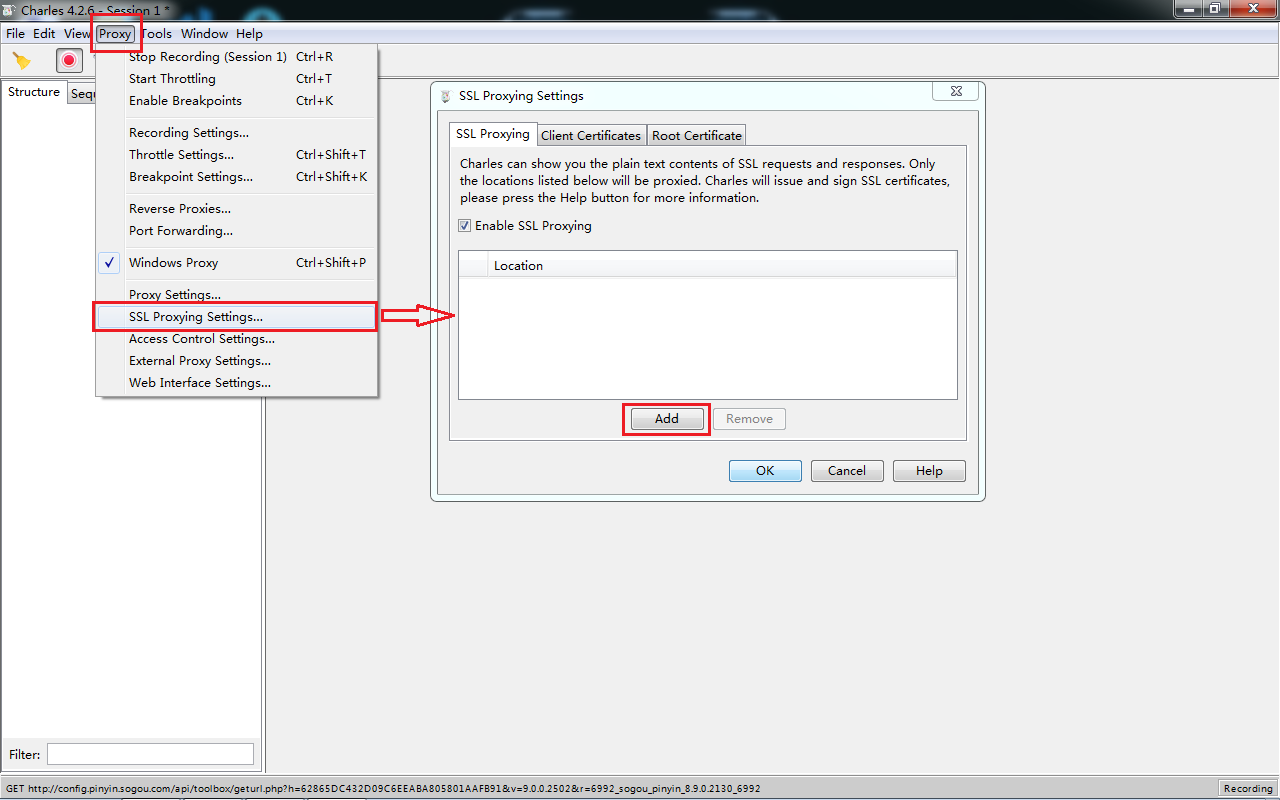
4.设置SSL代理(如果不设置,后面请求会是有很多443)
Proxy -> SSL Proxying Settings -> Add
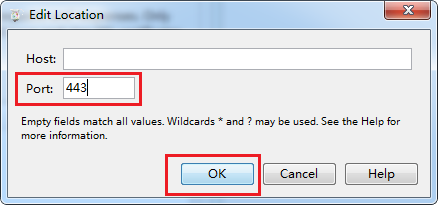
输入端口号443,点击OK
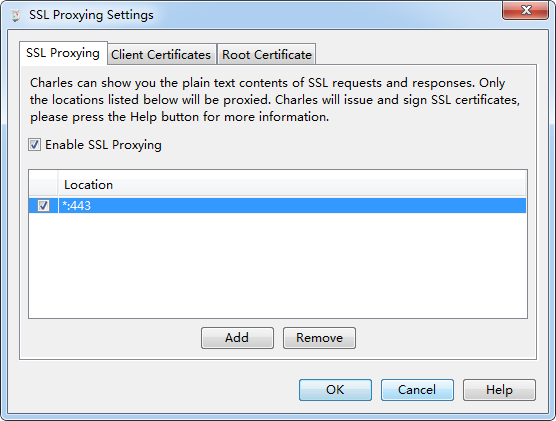
出现下面界面就添加成功了
MuMu模拟器
安装:同样是傻瓜式
配置:
1.设置代理


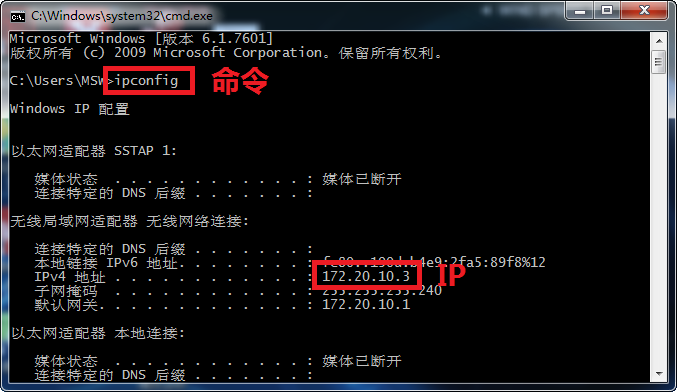
2.获取电脑ip , win + r -> 输入cmd -> 回车
3.安装证书
在虚拟器打开浏览器,输入cals.pro/ssl自动下载证书,下载完成后,点击打开
不出意外的话,工具安装和配置到这里就可以编写爬虫代码了
四.测试及找数据api接口
1.首先要打开Charles,再打开模拟器,下载掌阅app,打开模拟器,搜索免费
2.再看Charles软件,会发现左边的选项框中多了,一堆请求地址,随便点击一个,发现这个返回的数据和看到的好像不一样

3.再点下一个,再看看,哎,这个返回的数据好像挺多的,但是有编码问题看不出来是什么
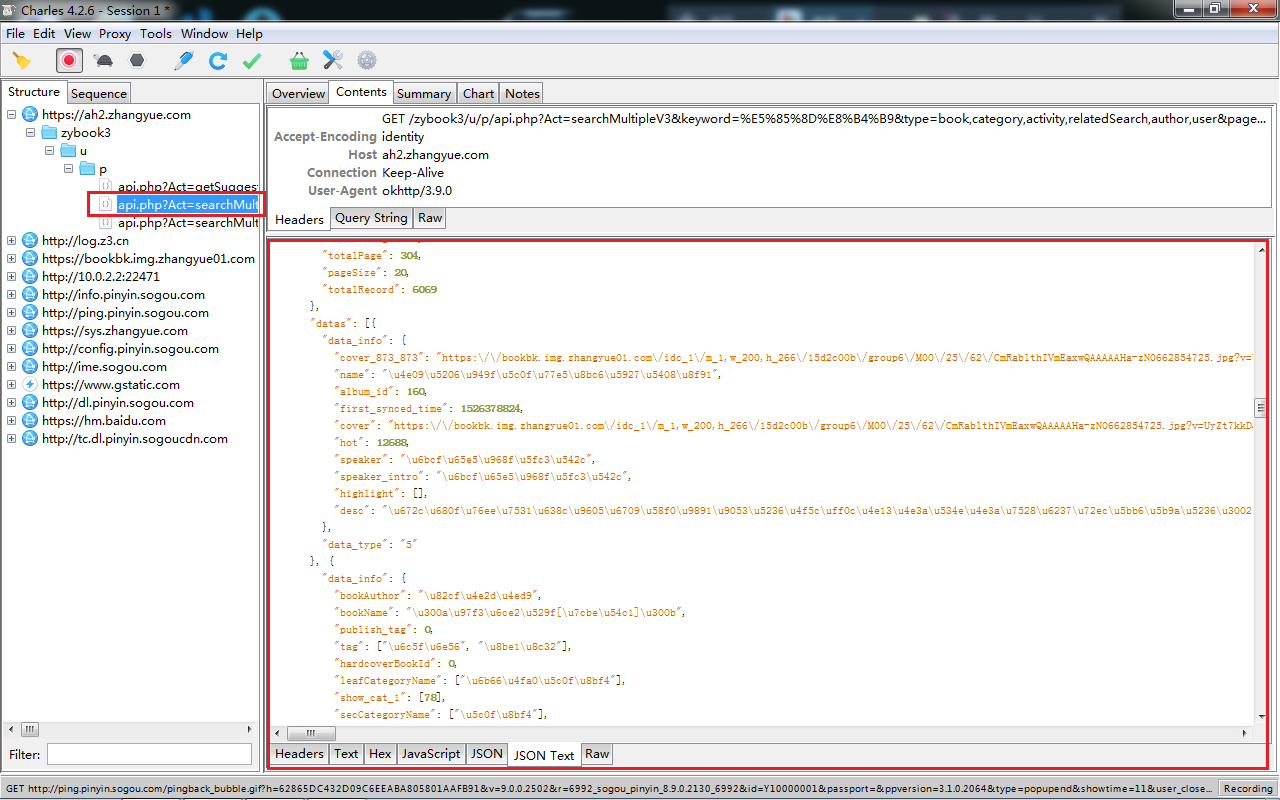
4.复制请求地址
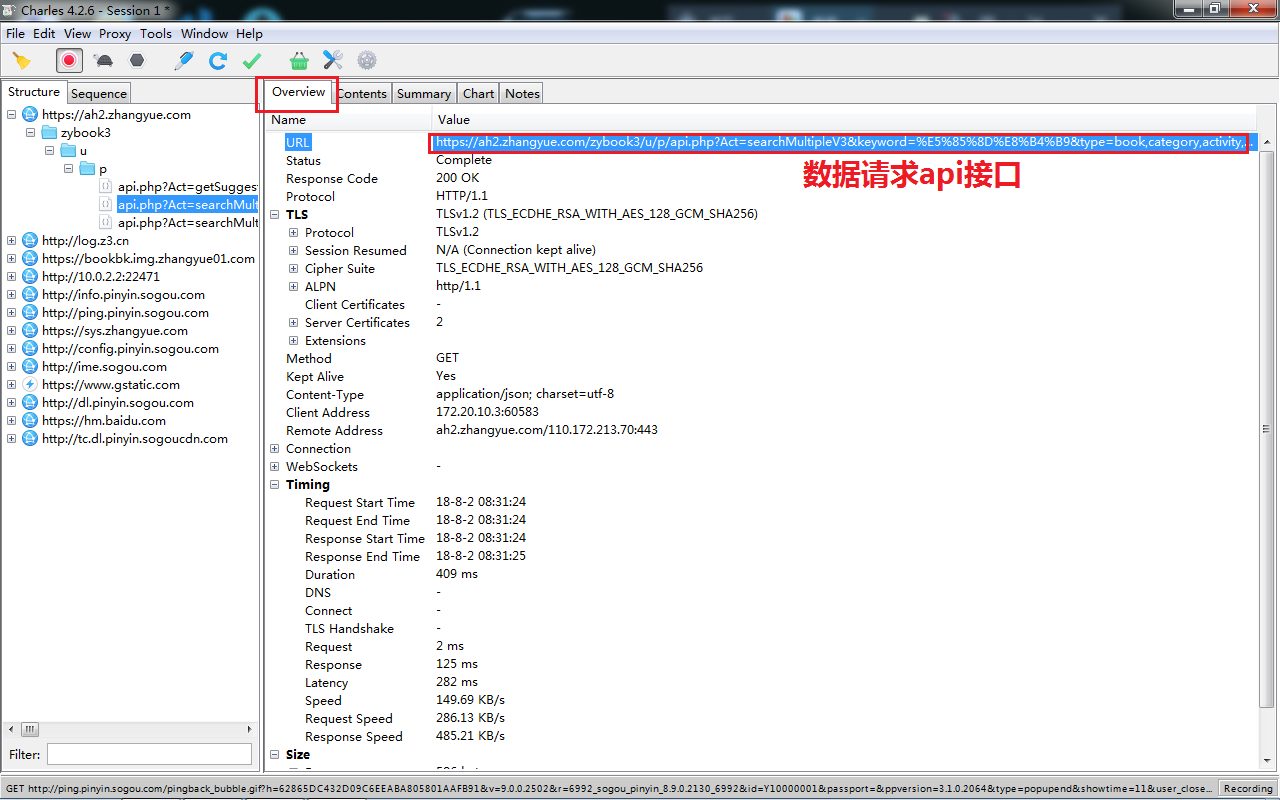
5.将请求地址在浏览器中打开,现在就可以看出来是什么了,会发现这些数据就是我们想要的数据
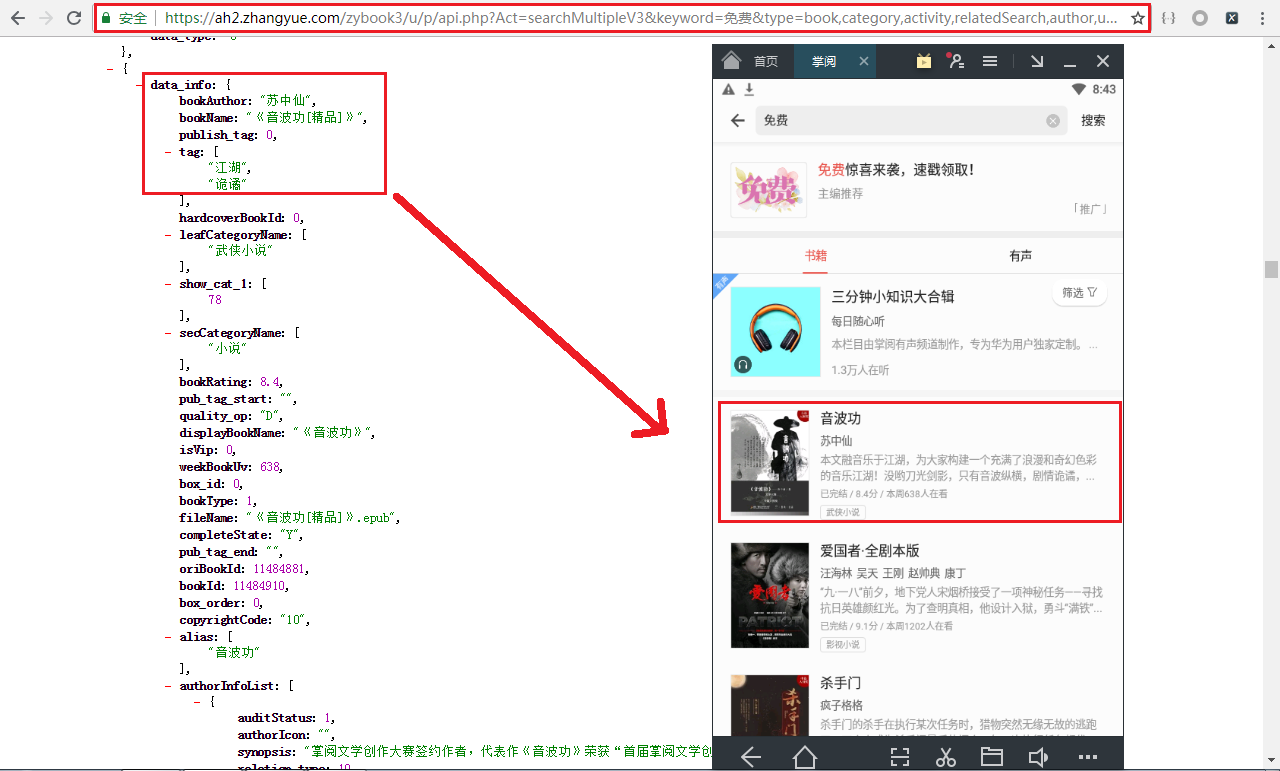
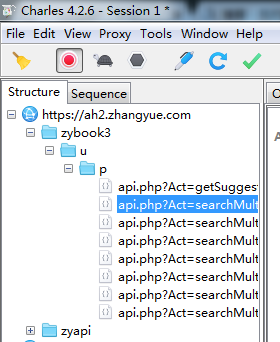
6.在验证一下,打开掌阅往下滑,会发现Charles中多了好多长的差不多的请求地址,这就证明猜测是正确的
五.编写爬虫程序
这里我用的是requests模块,只是开了个头
import requests import jsonpath import json # 经分析得知 # pageSize:表示的是每页返回多少条数据,currentPage:表示的是页数 url = 'https://ah2.zhangyue.com/zybook3/u/p/api.php?Act=searchMultipleV3&keyword=%E5%85%8D%E8%B4%B9&type=book,category,activity,relatedSearch,author,user&pageSize=500¤tPage=1' # 请求头 head= { "Host": "ah2.zhangyue.com", "Connection": "Keep-Alive", "Accept-Encoding": "gzip", "User-Agent": "okhttp/3.9.0" } # 携带请求头请求数据 response = requests.get(url,headers = head) # 将json数据转为字典 content = json.loads(response.text) # 使用jsonpath查找元素 res = jsonpath.jsonpath(content,'$.body.book.datas') # 遍历取出每本书的详细信息 for book in res[0]: print(book)
返回数据结果:
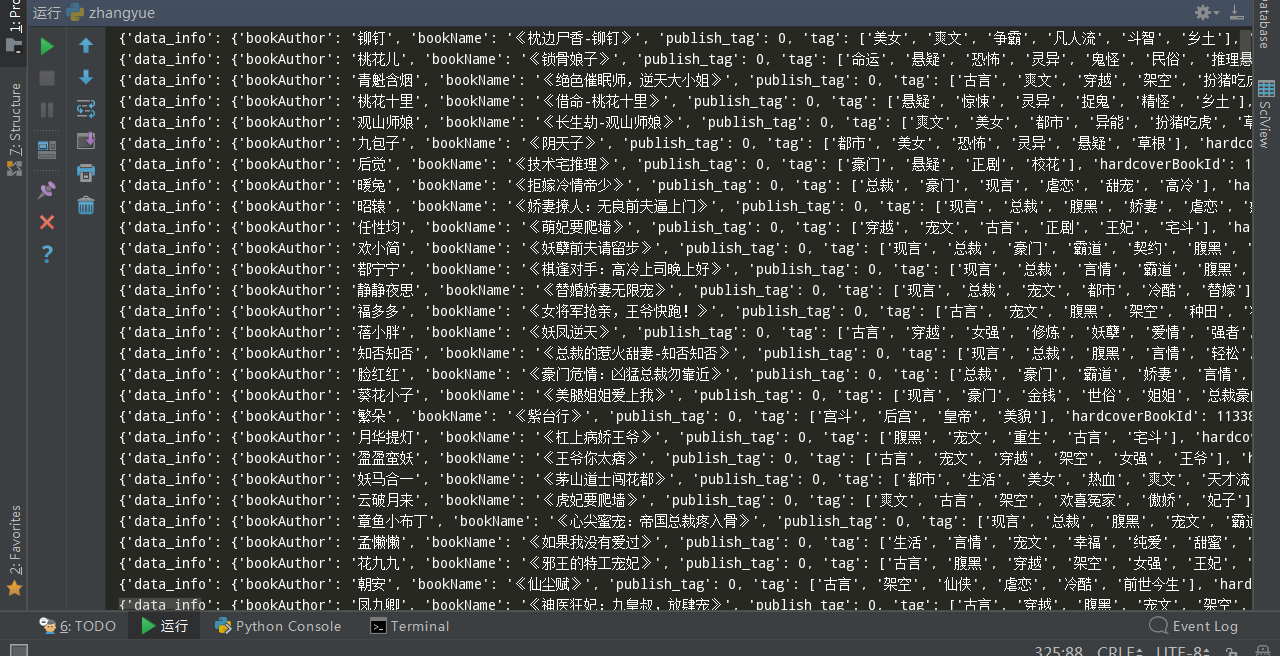
到这里,就可以爬取大部分app数据了
如有问题,欢迎交流