链接:https://www.zhihu.com/question/64300184/answer/231367777
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
什么做分享的大佬回答了我还要出来回答呢:因为大佬们讲的太好了!
听完之后觉得应该写下来,不然以后就忘了。
上午场
0x0000
腾讯副总Rose在conf开始之前发表了开幕词,回顾了他的光荣历史。2003年是Windows客户端的天下(电脑版QQ)。2005年Web开始发力(QQ空间、QQ邮箱),性能优化这些问题开始受到重视。2009年达到巅峰,前端团队规模达到几十人。2012年,随着APP的兴起,Web日渐衰落。但是在今天Web仍有立足之地,敏捷开发、混合开发、H5,形成了一股新热潮。
感觉低头走路的时候也要抬头看看,时代在进步,变亦变,不变亦变。在最后的时候一位导师说的话挺让人有感触:你们首先是工程师,然后才是前端工程师。
0x0001
第一场是W3C交互技术负责人Philippe分享的《Now and the Future》。这位大佬一口纯正的英国口音,表示理解无能,只能看着PPT勉强理解一下了。Philippe回顾了W3C历史上的丰功伟绩。还顺便科普了一下草案的制定过程,听得半懂:
- Working Draft(打算推进)
- Candidate Recommendation(收集资料)
- Proposed Recommendation(定稿)
- W3C Recommendation(大家认可)
之后Philippe从几个方面,讲了一下现在(已经被支持)及未来的发展方向。我印象比较深的是渲染、安全、媒体、通信还有新应用这些。
- 性能:
- requestAnimateFrame(帧级别的定时器)
- will-change(CSS动画的预加载)
- Web assembly(前端使用汇编)
- 生命周期(参见vue等)
- 安全:
- refer(预防csrf)
- httpOnly(预防XSS)
- authorization(存放身份信息)
- secure content(不太懂)
- 通信
- service worker(后面有PWA讲到了,感觉是个代理)
- 消息推送(服务端主动推送消息)
- 应用
- VR、AR等
Philippe还鼓励在座的大佬们共同参与W3C的制定,并给出了github地址 。
在提问中有一个很有意思的问题:前端发展越来越快,W3C会不会跟不上前端界的发展。Philippe老爷子很自信的回答:不会的,浏览器厂商一直在抱怨我们的标准制定的太快了,他们来不及实现。年轻人,先有标准,才有浏览器实现。
0x0002
说实话,我觉得Michael Yeung的分享《PWA与AWP》带给我的收获最大,可惜忘记给大佬点赞了。
大佬一上来就指出了前端发展的几个问题:
- APP的使用量远远大于Web
- 用户在top3的APP上花了80%的时间(28定律)
- 世界目前APP的月均每人下载量为0
这样一来Web不是没救了。不甘寂寞的前端程序员提出了AMP。AMP是一种规范,用来提高网页加载速度,想要给用户带来和原生APP一样的体验。
他的原理其实就是通过约束程序员随意的代码,牺牲少部分功能,提高加载速度。AMP必须遵守下面几条规范:
- 使用图片、视频资源,必须指定长宽,防止回流(重新渲染)造成的卡顿
- 不允许使用同步JS
- 不允许在页面直接引用第三方JS(可以封装组件)
- 只允许内联CSS
然后,大佬介绍了AMP的进阶版PWA。PWA比他的老爸更像原生APP。想要具有原生APP的以下特点:
- 可靠(断网也能加载出来)
- 快速(一次下载就能飞起来)
- 吸引(和原生一样丰富的API,大佬说这个目前有点虚)
要有这些功能该怎么办呢,只能由浏览器放权,提供接口给Web。其实个人理解小程序或许就是一个PWA(提供了大量接口的Web)。当前浏览器(safari不支持)提供的接口有:
- 独立的任务详情页
- 本地快捷图标
- 资源存储可控
前两个是浏览器提供的,和开发者没什么关系。所以详细讲了前端开发者如何控制资源的缓存和请求。这里主要用到的是service worker。service worker其实是一个用JS代码实现的代理层。web要请求html、css、图片资源的时候,都要经过service worker的代理。
- service worker拦截到请求的时候,也可以选择从本地获取缓存,如果有就返回给web。(又快又可靠,可惜不是最新的)
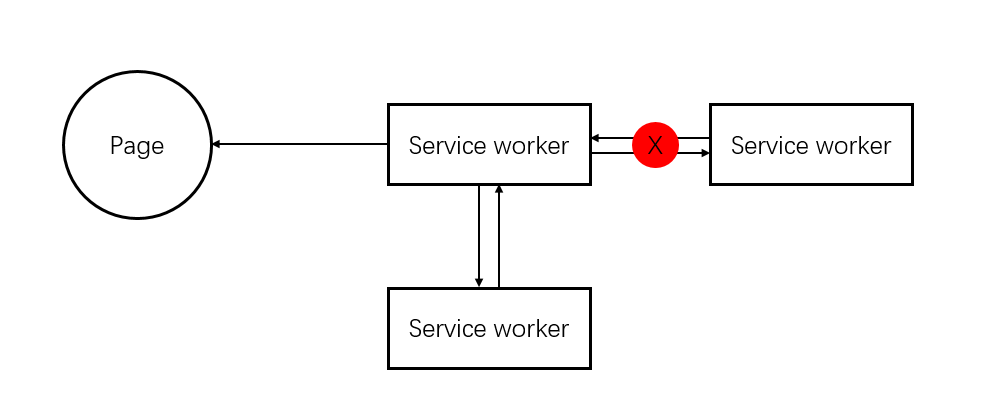
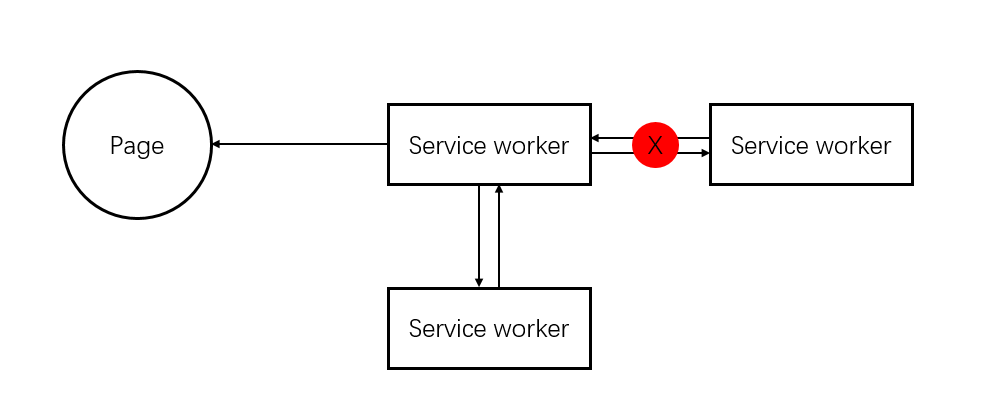
- service worker拦截到请求的时候,可以选择先从internet上获取,如果获取不到就读取本地缓存,返回给web。(又新又快又可靠)
大佬为了让台下的小白能快速上手,贴心的讲解了一下service worker的生命周期。register的时候加载所要执行的js,install的时候缓存本地资源,active的时候实现代理逻辑(可以先读本地,也可以先读remote)。
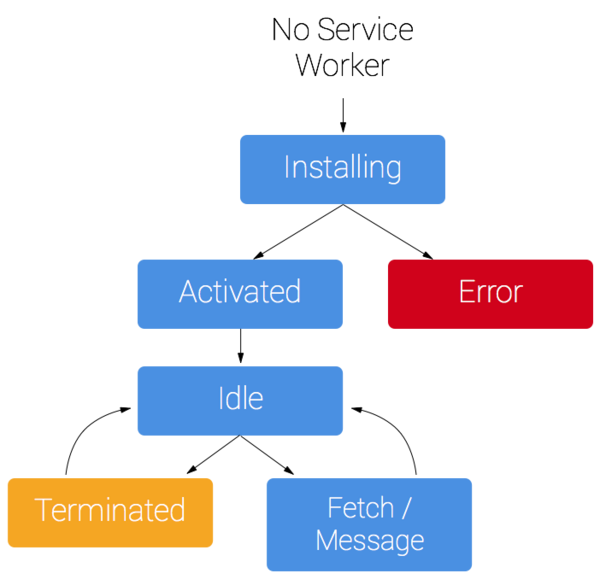
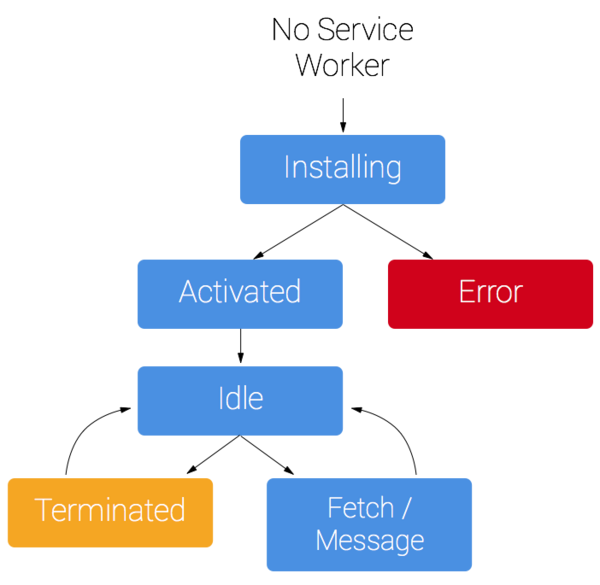
Show me the code!首先要先判断浏览器是否支持service worker。如果支持的话就可以执行某个js文件了。
if (navigator.serviceWorker) {
navigator.serviceWorker.register('worker.js').then(function(registration) {
console.log('regist success');
}).catch(function (err) {
console.log('regist error')
});
}接着在worker文件里定义install,缓存需要存储的文件。
var cacheFiles = [
'index.html'
];
self.addEventListener('install', function (evt) {
evt.waitUntil(
caches.open('my-test-cahce-v1').then(function (cache) {
return cache.addAll(cacheFiles);
})
);
});这时候断开网络,打开页面,发现还是显示了404,这是因为我们没有拦截fetch请求。
self.addEventListener('fetch', function (evt) {
evt.respondWith(
caches.match(evt.request).then(function(response) {
if (response) {
return response;
}
var request = evt.request.clone();
return fetch(request).then(function (response) {
if (!response && response.status !== 200 && !response.headers.get('Content-type').match(/image/)) {
return response;
}
var responseClone = response.clone();
caches.open('my-test-cache-v1').then(function (cache) {
cache.put(evt.request, responseClone);
});
return response;
});
})
)
});这样就大功告成了。在用户第二次打开页面的时候,service worker就会直接代理请求,加载缓存在本地的文件了。
这里有观众提问:这样实现和long cache有什么区别呢?Michael 的原话我记不太清了。大意是,这种实现方式是浏览器放权的一种思想,将资源加载完全交由开发者处理。
0x0003
Limin zhu大佬带来的是《Typescript》(这位大佬最终成了本期最佳讲师)。Z老师安利的确实很棒,之前也有很多人推荐过ts,如今下定决心用一用了。
Z老师一上来就指出了前端开发的苦逼现状,70%时间在读代码,25%时间在改bug,5%时间在写需求。作为一个大四的百度实习生,表示真的很对啊,真的很想去做新需求啊!Z老师一波安利,使用了ts和vscode可以让我们65%的时间在读代码,20%的时间在改bug,15%的时间在写需求。还是相当的诱人的。
如何快速上手ts,Z老师的给出了一个从未见过、及其方便的方案。首先你要有一个vscode,换编辑器吧,骚年。然后你只需要在头部注释@ts-check 就可以对全文进行检验了,你在编码的时候编辑器就会提示你可能出现的错误。注意,类型的注释格式必须和下面代码一样。
// @ts-check
/**
* @type {number}
*/
let test = 'hello world'
//提示:[js] Type '"hello world"' is not assignable to type 'number'.大佬还演示了如何使用typescript工具编译ts文件为javascript 。直接上代码吧,首先要安装typescript。
npm install -g typescript我这里就使用官网的示例文件了,你也可以自己编写一个ts文件。
// 注意看person后面的string类型声明
function greeter(person: string) {
return "Hello, " + person;
}
var user = "Jane User";
document.body.innerHTML = greeter(user);然后运行编译就可以咯,很简单。
tsc greeter.ts当然,实际项目中我们不可能这样使用,通常我们会结合webpack打造一个自动化的工作流。使用ts-loader就可以咯。当然还可以辅助sourcemap这些工具进行调试。
module: {
loaders: [
{ test: /.ts$/, loader: 'ts-loader' }
]
}大佬还演示了如何在react项目中使用ts,这里我就不再粘贴代码过来了,我对比了一下大佬的代码,发现好像就是这个github的。
0x0004
喵喵喵?这个大佬在说啥。狂记了一波笔记,回来了解一下再写。
上午过得还是挺快的,进门就领了牌子、衣服、本子、笔。会场挺大的,坐在前面看的很清楚。总的来说举办的真不错。不过一天下来真的困的要死啊,程序员为何要为难程序员呢。明天再来接着写吧。
下午场
0x0000
听完上午大牛的分享,就跑去楼下吃午餐。主办安排的时间太紧凑了,吃完就又跑回分会场,准备听下午的分享。下午分成了三个分会场,Node.js、框架性能、综合会场。其实还是挺想听Node.js的,但是感觉框架性能分会场的比较适合我的业务场景,所以还是去了框架性能分会场。
0x0001
百度外卖的林溪大佬为我们带来的是《Tree-Shaking》。
什么是tree shaking呢。直接翻译过来应该是摇树。把树上枯萎的叶子、果子摇下来,树就会变得更美观、更容易把养料用在该用的地方。tree shaking就是摇代码这棵树,在编码完成后,去掉没有用的代码。
tree shaking有什么意义呢:
- 减少网络传输的体积
- 提高加载速度
- 减小代码包
目前有三种tree shaking的工具:
- roll up(开山)
- webpack(uglify支持)
- closure compiler(配置比较复杂)
tree shaking的原理是这样的:
- 消除Dead code(不会执行或者结果不会用到)
- 消除无用模块
消除无用模块是基于ES6来说的,由于ES6模块具有以下特征,所以可以在静态检验的时候就可以确定依赖,消除不需要引用的部分。
- 只能在顶层作用域出现(一般写在最前面)
- 名称只能是常量不可更改
这里大佬特别指出,对于那些函数式编程的库,消除模块的作用比较明显。因为函数式编程可以规避动态访问,tree shaking可以放心的去掉静态检验中没有引用的函数。
这里我按照大佬的讲解配置了一下webpack.config.js
new webpack.optimize.UglifyJsPlugin({
beautify: false,
comments: false,
compress: {
warnings: false,
drop_console: true,
collapse_vars: true,
reduce_vars: true
}
})如果你使用了antd大佬还给你提供了babel-plugin-import-fix。
import {Button} from 'antd';主要实现的功能就是把上面的内容变成下面的。
import {Button} from 'antd/lib/button';
import 'antd/lib/button/style'不仅js可以tree shaking,css也可以。大佬好像是基于postcss的解析做的。根据大佬所说,他只对class和id做了tree shaking,而没有动伪类等等。其实个人感觉,有的时候我也会拼接class,这样来看应该是会有副作用报错的吧。下载插件后这样使用。
var ExtractTextPlugin = require('extract-text-webpack-plugin')
const CssTreeShakingPlugin = require("webpack-css-treeshaking-plugin")
module.exports = {
plugins: [
new CssTreeShakingPlugin({
remove: false,
ignore: ['state-d']
}),
new ExtractTextPlugin({
filename: 'build/style.css'
})
]
};大佬最后总结了一波他的探索过程,大佬在对比结果的时候使用的工具很有意思,大家可以从这里下载,在每次打包之后可以分析各个文件大小,绘制出交互图像。


最后,要保证tree shaking的效果,请遵循以下两点建议:
- 使用eslint做检查
- 函数式编程
最后有一个大佬提问:我们也在做tree-shaking,发现对于有些库效果不明显,只能减少10+kb,应该怎样处理。回答是这样的:tree-shaking现在还处于实践阶段,但是总有一天我们可以消除无用的代码。(膜)
0x0002
徐杰大佬讲解的是《RN在QQ空间中的应用》。其实这几天React真的很不太平,先是Wordpress改版成React,然后React又不给用了。接着百度内部全面剔除React。想着听听算了,不过徐杰大佬应该是架构师这一层面的吧,给出了很多自己的考虑和思路,大团队使用RN的考虑还是很让人耳目一新的。
徐杰大佬主要讲的是一个在手Q中(ios)的页面。一上来大佬就先分析了在用RN改版前的加载耗时情况:
- Webview启动耗时(最多,然而H5不可控)
- 请求资源耗时
- 页面渲染耗时
为了突破webview耗时过多的瓶颈,才把H5重构成RN的。据说每多等一秒,就有很多转化率流失。(说服产品的好理由啊,彰显前端价值)。
然而使用RN也有以下的顾虑:
- 性能
- 可靠性(红屏)
- 组件化(可复用)
最后大佬提出了两种解决思路:
- 业务拆包
- base bundle一并下发
- task bundle按需下发
- 降级方案
- 默认使用RN方案(成功率有96%,其余好像都是网络环境的原因失败)
- 如果失败使用H5降级方案(这里需要原生同学帮忙)
效率问题是所有前端开发者注重的大问题。为了提高加载速度,不断折腾,或许是前端最有趣的事情之一吧。
0x0003
王跃大佬带来的是《小程序核心架构剖析》。同行的小伙伴本来是不想听的,结果听了之后的评价是:这是本次conf干货最多的一个分享(他好像也没来的及投票)。
根据大佬的解说,初步了解了小程序的盛况,腾讯内部有100+小程序,外部有?(这里保密了)个小程序,小程序的入口就有50多个(应该是算上了各种卡片、推送等等的吧)。接着大佬分享了对小程序的分析。
小程序编译后的静态文件分为以下几部分:
- WAService(逻辑)
- WAWebview(视图)
- WAConsole(调试)
- app-config(所有配置项,包括一些默认的)
- app-service(全局逻辑,包括global这些)
- page_frame.html(模板)
- pages(css样式)
他们是这样编译来的:
- WXML ==> page_frame
- WXSS ==> page
- js ==> WXService
- json ==> app-config
在运行时,小程序开了2两个webview(感觉像是两个线程),他们之间的通信通过jsBridge传递到native,再由native传递回jsBridge。主要的传递方法我就记住了webkit上的postmessage和addEventlist。
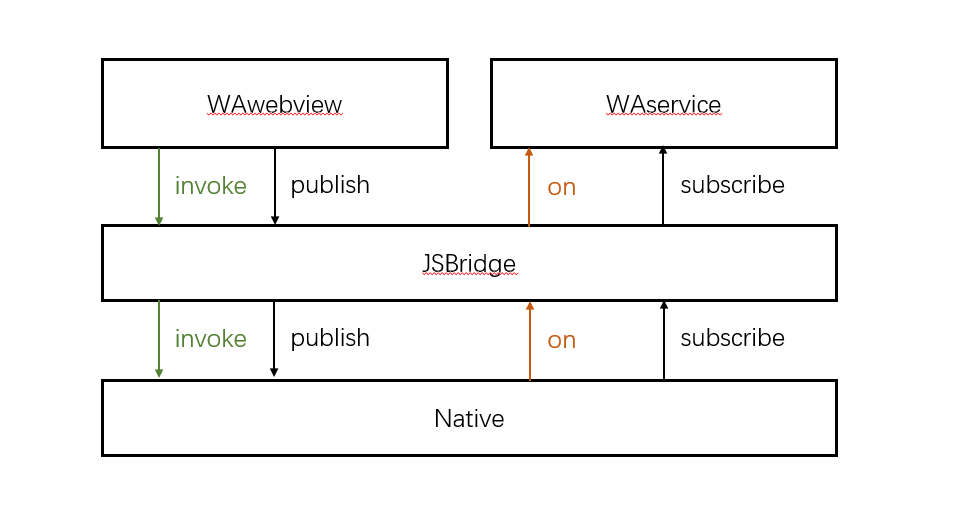
WAwebview主要以webkit为内核,主要跑了以下文件:
- WAWebview.js
- page-frame.html
- page
WAwebview主要提供了以下服务:(感觉就是react的作用)
- component
- API(主要是给component调用的)
- render
- event
- jsBridge
- reporter
WAservice在PC上是webkit内核,在ios上是JScore内核,在android上是V8内核,这样做的目的是精简内核,毕竟webkit里有很多用不到的东西。而PC主要用于调试,选之前的技术栈就可以了。主要跑了以下文件:
- WAservice.js
- app-config.js
- app-service.js
WAservice主要提供了以下服务:(感觉就是redux的作用)
- API(全局)
- module
- global
- reporter
接着大佬根据原理,讲解了一些小技巧:
- page:一般不超过5个,超过后小程序就会自动复用
- size: 一般不超过2M
- Dom: 一般不超过16000
- Data: 会占用内存,数据传输jsBridge会耗时,只要setData自己有用的资源就可以了
- 动画:可以用css3解决
- 请求:小程序使用的是service worker
- 渲染:diff算法
- 预加载优化
- 小程序会在打开一个页面的时候,先加载下一个页面的page_frame,加载时会自动拷贝page对象,因此,我们可以提前在page对象里注入数据。
- 开发者可以自己预测用户可能会点击的下一个页面,并将数值缓存到localstorage
- 对媒体资源如图片等设定长宽,防止reflow的时候画面闪动(AMP)
良心之作,会后给大佬微信,没想到大佬居然回我了,终于找到了小程序源码。原来大佬是android翻的文件,双击666。难怪我在PC上硬是没找到编译后的文件,不知道拦截上传行不行。
0x0004
林子杰大佬分享的是《页面性能体系的评估》,这位大佬很像我的一个师兄,好年轻啊。
大佬首先推荐了scrat框架,包含了脚手架、测试等很多功能。接着,大佬演示了如何使用scrat和UC浏览器进行性能优化。在例子中主要用的技巧是:
- require.sync
- settimeout(balabala,0)
那么性能测试应该包含哪些维度呢:
- 谷歌浏览器
- FP 首次绘制时间
- FMP 关键内容绘制时间(这个比较难以测量)
- TTI 可交互时间(所有都加载完,用户可以点击)
- UC浏览器
- responsetime T0 (服务器返回)
- 首次绘制内容 T1 (有东西显示)
- 绘制满屏内容 T2 (html和css完成)
- 加载完所有资源 T3 (图片和媒体资源)
根据页面种类不同,所需要重视的维度也有所不同:
- 营销游戏:T3、FPS(流畅度)
- Feed流: T1、T2
- 长列表: T1、T2、FPS
根据网络环境不同,对指标的要求也有所不同:
- WIFI环境
- 普通页面在1000ms之内
- 视频等富媒体页面在2000ms之内
- 2G/3G/4G(由于网络环境不稳定,一般看比例)
- 1s占比
- 2s占比
- 3s占比
性能优化后如何进行调试:
- 线下
- 真机调试
- 内核工具
- 测试平台
- 线上
- API
window.chrome.loadTimes() //谷歌几种常见的优化方法:
- 优化图片占比
- 优化总体size
- T1/T2分析
- 可以将部分T1资源后置到T2
- 可以考虑localstorage是否合适
- JS耗时分析(断点调试长耗时算法)
- 排版渲染(防止回流等)
- 提高缓存命中概率
以前没注意到还有这么多接口可以查看统计数据,UC浏览器的接口好像比chrome多封装了一些,有空用用看。有个嘉宾提问:UC封装了这么多统计接口,会不会影响页面加载?回答:不会的,可以切换实验环境和实际环境。
0x0006
好了,到这里就基本结束了。中间的茶点和充电宝很棒。很感谢IMWeb提供了这个机会,让我们向大佬们学习。建议你明年一起去咯~说不定还能见面呢,一起学习。能力有限,记得不多(也不一定准),不好意思了。