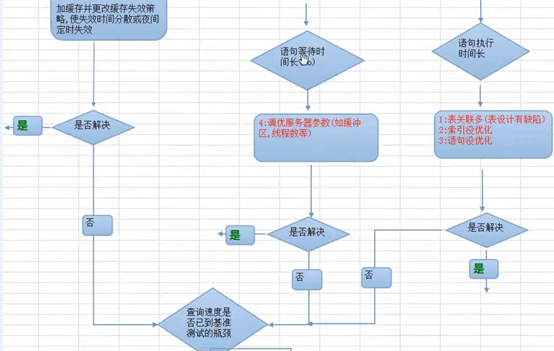
给你一台服务器让你去优化,第一,先要去观察问题,只有观察到了问题,才能知道如何去优化。
先做基准测试,看看我们的服务器潜力到底有多大。


1.打开Mysql服务

2.查看我们Mysql的版本和安装了哪些相关的东西

3.登录Mysql

4.执行show status;
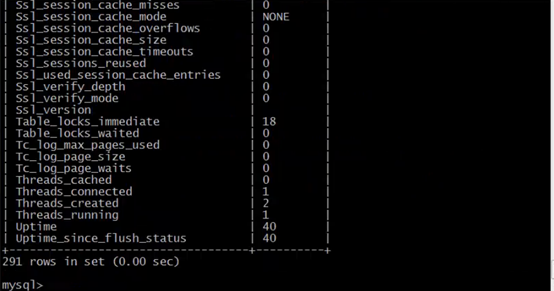
5.返回200多行数据,着重关注这3行
当前已经发生了多少次查询

有几个线程过来连接了(有多少个连接)

有几个进程正在工作(连接中有多少个是活动的)

AWK:按行读取文件,把当前行赋给变量$0,把当前行的第一列赋给$1,第二行赋给$2,以此类推。
下面这几条命令执行的就是
- 把score.txt中的内容原样打印出来。
- 把每一行的第一列的值打印出来
- 把每一行的第二列的值打印出来

AWK还可以使用正则匹配。如下这条命令,就是把l开头的行,打印出来。

show status;命令,也可以用mysqladmin -uroot ext替换。
所以如下这条命令就是,把mysqladmin –uroot ext命令的结果,传给awk,然后把Queries开头的行的第四列的值打印出来

如下的命令是,把Queries,Threads_Connected,Threads_running开头的行的第四列的值打印出来。

在AWK中,我们还可以设置变量,下面的名师是,把Queries,Threads_Connected,Threads_running开头的行的第四列的值分别赋给变量q,c,r,然后再通过变量,把这些值打印出来,得到的结果是一样的。
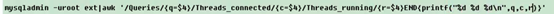
AWK的执行过程是会,把正则匹配及处理方式带入到每一行。循环过程中的每一行,先通过正则对这一行进行匹配,如果匹配成功,则用处理方式进行处理,否则,跳过。就像上述命令,就是正则先匹配Queries,Threads_Connected,Threads_running,匹配成功之后,用处理方式进行处理,处理方式就是打印,也就是printf函数

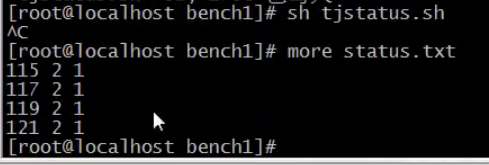
试验
1.启动memcached,给他512M内存

2.启动Nginx

3.由于我们的nginx是fastcgi的方式,所以需要把php也起来

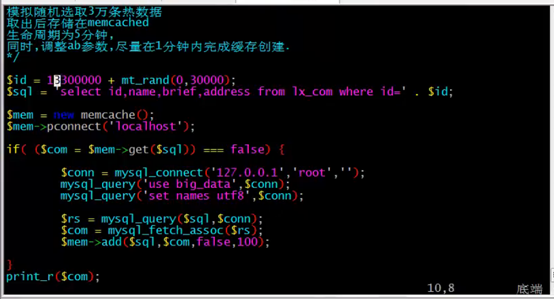




表的优化与列类型选择
列选取原则
- 字段类型优先级,整型>data,time>enum>char,varchar>blob
原因:整型,time运算块,节省空间
char varchar要考虑字符集的转换与排序时的校对集,速度慢
Blob无法使用内存临时表
- 够用就行,不要慷慨(如smallint,varchar(N))
原因:大的字段浪费内存,影响速度
以varchar(10),varchar(300)存储的内容相同,但是在表联查时,varchar(300)需要花更多的内存
- 进来避免用NULL
原因:NULL不利于索引,要用特殊的字符来标注
在磁盘上占据的空间其实更大
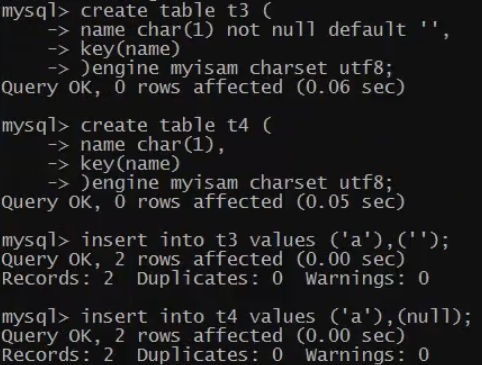
试验
可以建立2张字段相同的表,一个允许为null,一个不允许为null,各加入1W条数据,查看索引文件的大小。可以发现null的索引要大些


Enum类说明
- enum列在内部用整型来存储


2.enum列月enum列想关联速度最快(意思是如果一张表的字段使用了enum,那么另外一张表也尽量使用enum)
3.enum列比char,varchar的弱势—---在碰到与char关联时,要转化,要花时间
4.有时在于,当char非常长时,enum依然是整型固定长度。当查询的数据量越大时,enum的有时越明显
5.enum与char,varchar关联,因为要转化,速度要比enum->enum,char->char要慢
但有时候也这样用----就是在暑假了特别大时,可以节省IO

Mysql事务
我们首先开启两个Mysql客户端,分别用黑色和绿色表示。
在黑色客户端总,创建一张账户表(用户名,钱数)
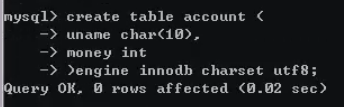
并且插入两条数据,zhang:5000块钱 li:3000块钱
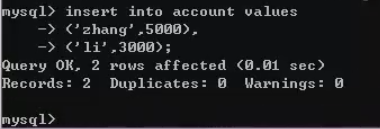
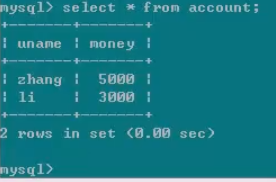
此时,我们可以在绿色客户端中看到我们插入的数据
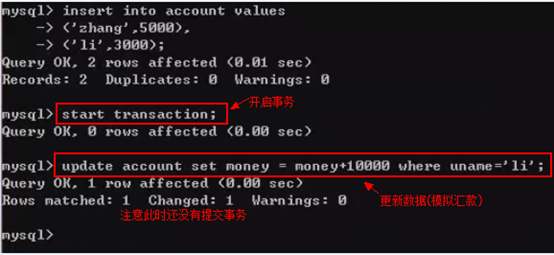
现在我们在黑色客户端中,开启事务,并且模拟给li用户汇款10000。
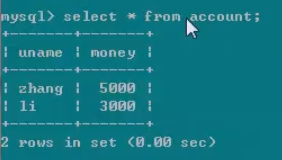
这时,我们在绿色的客户端中,再次查询账户,可以看到,li的账户的钱并没有增加。
因为,我没有提交事务。也就是说这个事务还没有完。如果此时能查到li的账户的钱多了。那么就违背了原子性了。原子是最小的,我们不可能看到原子的一半。提交事务之前,我们的操作是被写到事务日志中,而没有被写到磁盘中。
我们在黑色客户端中执行commit,来提交事务

现在我们在绿色客户端中在查询就可以查到li的账户多了10000块钱

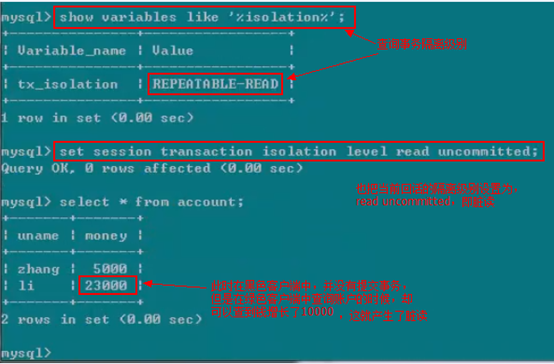
read uncommitted
现在我们做测试,修改一下隔离级别改为(read uncommitted,脏读)
现在黑色客户端中,修改事务隔离级别,并模拟汇款操作,但不提交事务

同时修改绿色客户端的事务级别,并且进行账户查询。(这里有个疑问,如果绿色客户端不修改事务隔离级别,结果会是什么呢?)
read committed
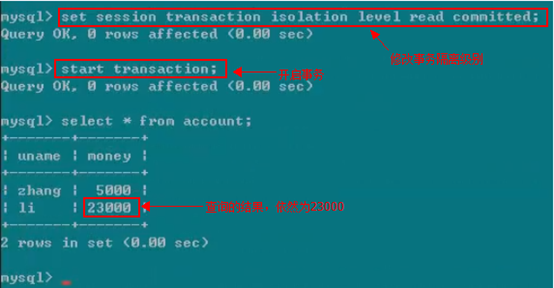
现在我们做测试,修改一下隔离级别改为(read committed)
我们在黑色的客户端中,修改事务隔离级别,并开始事务,模拟汇款操作。但不提交事务

我们在绿色客户端中,也同样修改事务隔离级别,并且开启一个事务,然后查询账户。按照脏读的级别来讲,虽然黑色客户端并没有提交事务,但绿色客户端现在我们应该能看到账户的钱在增加。但是对于read committed级别,黑色客户端不提交事务,绿色客户端是看不到钱在增加的。也就是说黑色客户端事务没有结束,绿色客户端是读不到数据的变化。
现在,我们让黑色客户端提交事务。
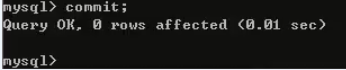
此时,再在绿色客户端查询账户信息,可以查询到前增长了,变成33000了。其实此时还是不应该被读到的。为什么说还是不应该被读到呢?在黑色客户端事务没有结束的时候,绿色客户端读不到数据的变化。但是在黑色客户端事务结束了,我们读到数据的变化不是正常的吗。原因是这,因为我们在绿色客户端中也开启了一个事务。并且这个事务也没有结束。他应该也收不到外界的影响才对。也就是说在他开启事务的那一瞬间,外面的世界是什么样,在他结束事务之前,他眼中外面的世界,应该始终都是一个样。或者说,在事务过程中,外界的变化怎么变化都影响不到我,外界的变化应该不被该事务内部所看到。
一个没结束的事务,他的内部数据变化不能被外面所看到。反之,一个事务没结束,他也不能看到外面的变化
repeated able 就是我们最终想要的一个事务级别。
黑色客户端,修改事务隔离级别,开启事务,update数据模拟汇款操作,但并不提交事务
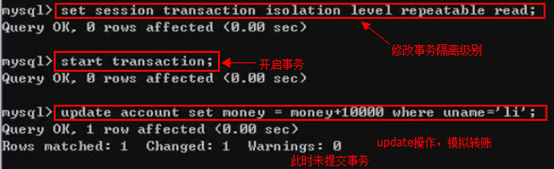
此时在绿色客户端修改隔离级别,并开启事务,此时查询的数据仍然是33000,没有变化。也就是在黑色客户端没有提交事务的时候,绿色客户端是看不到的。

此时在让黑色客户端提交事务

此时我们再在绿色客户端中查询账户信息。依然看不到变化。仍然是33000

最后我们让绿色客户端也提交事务。提交事务之后,再来查看账户信息。此时就可以看到账户信息变化为43000了。
serialize
把所有操作都串行化,所有 操作都一句一句的执行,有先后之分,这样互相操作之间就肯定没有影响了。这个级别非常高,但是效率就比较低了。
一般项目中的事务隔离级别都设为默认的repeatable