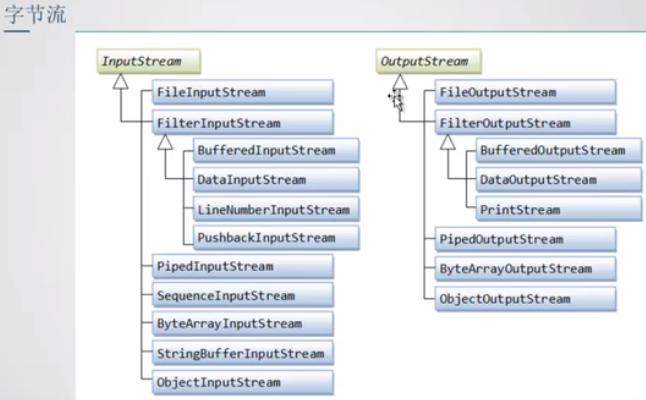
核心类

对象想要被传输, 需要通过序列化来将对象编程“序列”.

字符集对字符流的影响. 字符流底层还是字节流.
分隔符
public class IOTest { public static void main(String[] args) { // TODO Auto-generated method stub String path = "C:\JavaWork\eclipse-workspace\MyProject01\src\smart_production.JPG"; String path2 = "C:/JavaWork/eclipse-workspace/MyProject01/src/smart_production.JPG"; String path3 = "C:" + File.separator + "JavaWork" + File.separator + "eclipse-workspace" + File.separator + "MyProject01" + File.separator + "src" + File.separator + "smart_production.JPG"; System.out.println(path); System.out.println(path2); System.out.println(path3); } // 建议, path2 和 path3 都没有问题, 主要建议使用 path2 的方式 }
输出结果:
![]()
遍历文件夹文件
// 下级名称 list File dir = new File("C:/JavaWork/eclipse-workspace/MyProject01/src"); String[] subNames = dir.list(); for (String s:subNames) { System.out.println(s); } // 下级对象 listFiles() File[] subFiles = dir.listFiles(); for (File s:subFiles) { System.out.println(s.getAbsolutePath());
遍历所有的文件(子文件夹也遍历), 递归
File src = new File("C:/JavaWork/eclipse-workspace/MyProject01/src"); printName(src, 0); } // 用递归, 非常占用内存 public static void printName(File src, int deep) { System.out.println(src.getName() + " " + deep); if (null == src || !src.exists()) { return; } else if (src.isDirectory()) { for (File s:src.listFiles()) { printName(s, deep+1); } } }
字符集 & 乱码
编码: 由字符 -> 字节(2进制), encode
解码: 由字节 -> 字符(人能读懂), decode (计算机只认识 0低电平,1高电平 等字节)
"a" 有个代号整数比如64,然后转换成 2进制数, 就编码了(转换成字节码了). 所以这个代号的集合就是字符集. 同样 "中"这个字也是可以利用字符集来编码.
// 编码: 字节数组 byte[] datas = msg.getBytes(); // 默认使用工程的字符集 System.out.println(datas.length); // 解码: 字符串 msg = new String(datas, 0, datas.length, "UTF-8");
解码的过程中可能产生乱码:
因为长度不够, (如果采用一个一个字节的方式读取, 就可能产生乱码, 因为比如汉子, 它是多字节的.)
字符集跟之前不匹配.
字节流: 处理视频, 音频, word, excel 等.
字符流: 比如处理纯文本, 也就是说文件本身就是字符的, 那么,我们不用编码成字节了, 可以直接处理.
JAVA虚拟机本身无权操作文件, 是借助操作系统来完成的对文件的操作.
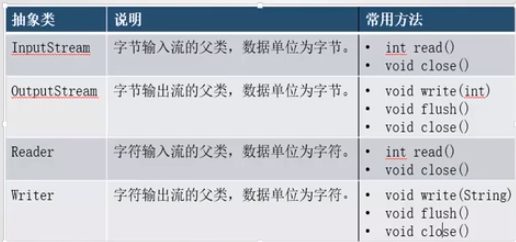
常用类及方法
字节流
标准步骤
1. 确定源
2. 选择流
3. 操作(读,写)
4. 释放资源
package com.pratice.java300; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; /* * 1. 创建源 * 2. 选择流 * 3. 操作(读写) * 4. 释放资源 */ public class IO02 { public static void main(String[] args) { // TODO Auto-generated method stub // 1.创建源 File src = new File("stanford.txt"); InputStream is = null; try { // 2.选择流 is = new FileInputStream(src); int temp = 0; // 3.开始处理, 文件读取完, 返回-1 while ((temp = is.read()) != -1) { System.out.println((char)temp); } } catch(FileNotFoundException e) { e.printStackTrace(); } catch(IOException e) { e.printStackTrace(); }finally { try { if (null != is) { // 4.关闭文件 is.close(); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }
上例中, 每次读取1个字节, 也可以一次多字节读取.
package com.pratice.java300; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; public class IOTest04 { public static void main(String[] args) { // TODO Auto-generated method stub File src = new File("stanford.txt"); InputStream is = null; try { is = new FileInputStream(src); int len = -1; // 每3个字节, 3个字节读取, 一次性读取的大小, 如果写100,那对于本例子等于一次性读取完 byte[] car = new byte[3]; while (null != is && (len = is.read(car)) != -1) { String str = new String(car, 0, len); System.out.println(str); } } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { if (null != is) { is.close(); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }
输出流, 注意输出字符, 要转换成字节数组来跟文件交互. (也是这4步骤)
package com.pratice.java300; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStream; public class IOTest05 { public static void main(String[] args) { // TODO Auto-generated method stub // 1. 创建源 File src = new File("asdf.txt"); //如果文件不存在, 自动创建 // 2. 选择流 OutputStream os = null; try { os = new FileOutputStream(src, false); //false 覆盖文件, true 追加文件 // 3. 操作写出 String str = "IO is so easy."; byte[] dates = str.getBytes(); // 因为是操作字节, 所以这里要转换成字节 os.write(dates); os.flush(); // 避免数据驻留在内存中 }catch(FileNotFoundException e) { e.printStackTrace(); }catch(IOException e) { e.printStackTrace(); }finally { if (null != os) { try { // 4.关闭文件 os.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } } }
文件 copy, 只需要将上边的代码合二为一就可以了.
package com.pratice.java300; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; // 实现文件copy public class IOTest05 { public static void main(String[] args) { // TODO Auto-generated method stub // 1. 创建源 File src = new File("stanford.txt"); //输入文件 File dest = new File("dest.txt"); // 输出文件, 如果文件不存在, 自动创建 // 2. 选择流 InputStream is = null; OutputStream os = null; try { is = new FileInputStream(src); os = new FileOutputStream(dest, true); int len = -1; // 3. 操作, 每次copy 3 字节进入目标文件 byte[] dates = new byte[3]; while (null != is && null != os && (len = is.read(dates)) != -1) { os.write(dates); // 这应该使用 os.write(dates, 0, len); os.flush(); // 避免数据驻留在内存中 } }catch(FileNotFoundException e) { e.printStackTrace(); }catch(IOException e) { e.printStackTrace(); }finally { if (null != os && null != is) { try { // 4.关闭文件 is.close(); os.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } } }
源文件是:
CS106A
CS107B
但是 copy 出来的文件是: (运行结果)
CS106A
CS106B
B
为什么呢?
因为上面的操作, 实际上是每次读取源文件, 把字节放到字节数组date中, 而实际程序运行时, 每次读取文件时, date数组实际上还还保存着上次读取文件的结果, (实际上每行的最后都有两个字节:换行, 回车)可是到了最后一次读取就出问题, 每次读取三个, 我们分配一下 共16个字符(12原本字符 + 4个(换行回车))
CS1
06A
换行回车C
S10
6B换行
回车B换行
所以这个粉色的B换行不是这次文件读取到的, 而是原来保存在 dates 数组中的. 所以这个会再次copy到 dest 文件, 这是有问题的.
所以, 如果想使用批量的读取, 那么也有解决办法,解决办法就是写文件使用 os.write(dates, 0, len); 这样读到最后, len 的长度是1, 所以只写一个元素.
文件流
通过字符的方式处理文件. 对比于字节数组, 这里的处理结果保存在字符数组中.
流程都一样, 都是那4步骤
文件字符输入流
package com.pratice.java300; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.io.InputStream; import java.io.Reader; public class IOTest6 { public static void main(String[] args) { // TODO Auto-generated method stub File src = new File("stanford.txt"); Reader reader = null; try { reader = new FileReader(src); int len = -1; // 每3个字符 char[] car = new char[3]; while (null != reader && (len = reader.read(car)) != -1) { String str = new String(car, 0, len); // 同样要注意文件最后的长度问题 System.out.print(str); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { if (null != reader) { reader.close(); } } catch (IOException e) { e.printStackTrace(); } } } }
文件字符输出流, 实际上都是按照字节来修改一下
package com.pratice.java300; import java.io.File; import java.io.FileNotFoundException; import java.io.FileWriter; import java.io.IOException; import java.io.Writer; public class IOTest7 { public static void main(String[] args) { // 1. 创建源 File dest = new File("dest.txt"); //输入文件 // 2. 选择流 Writer writer = null; try { writer = new FileWriter(dest, true); // 3. 操作 String msg = "IO 你好 asdf kkk"; char[] dates = msg.toCharArray(); //转换成字符数组 writer.write(dates, 0, dates.length);
writer.write(msg) // 直接丢就可以.
writer.append(msg) // 可以累加, 而且可以多次写.
writer.flush(); // 避免数据驻留在内存中 }catch(FileNotFoundException e) { e.printStackTrace(); }catch(IOException e) { e.printStackTrace(); }finally { if (null != writer) { try { // 4.关闭文件 writer.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
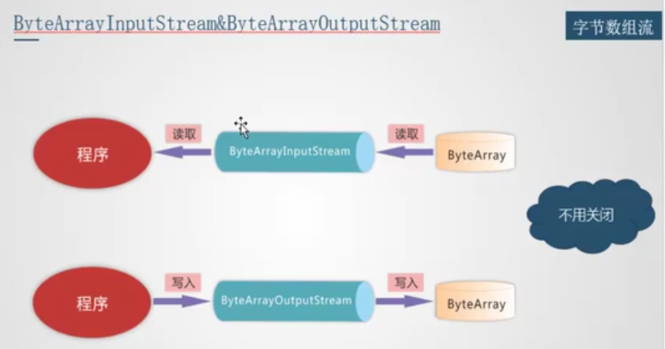
字节数组流 ByteArrayInputStream & ByteArrayOutputStream
源文件是一块内存, Java 可以直接访问. 这种在内存中的数组流, 不用关闭.(因为是在内存中) 由 GC 帮我们释放内存.
所有的东西, 都可以转成字节数组流, 因为是2进制的, 所以字节数组流方便我们进行网络传输.
流程上, 还是那4步骤.
package com.pratice.java300; import java.io.ByteArrayInputStream; import java.io.IOException; import java.io.InputStream; public class IOTest8 { public static void main(String[] args) { // 创建源 byte[] src = "asdffdaxxx".getBytes(); InputStream is = null; // 多肽, 为了更加通用 try { is = new ByteArrayInputStream(src); int len = -1; // 每5字节, 5个字节读取 byte[] flush = new byte[5]; while (null != is && (len = is.read(flush)) != -1) { String str = new String(flush, 0, len); System.out.println(str); } }catch (IOException e) { e.printStackTrace(); } } }
ByteArrayOutputStream 本身不需要输出到文件(是输出到内存中的流, 也就是一个新的字节数组), 所以同样也不需要关闭文件.
但是, 你有关闭代码也无所谓.
package com.pratice.java300; import java.io.ByteArrayOutputStream; import java.io.IOException; public class IOTest9 { public static void main(String[] args) { // 1. 创建源 byte[] dest = null; // 2. 选择流(新增方法) ByteArrayOutputStream baos = null; try { baos = new ByteArrayOutputStream(); // 3. 操作 String msg = "IO 你好 asdf kkk"; byte[] datas = msg.getBytes(); baos.write(datas, 0, datas.length); // 写到内存中 baos.flush(); // 避免数据驻留在内存中 // 获取数据 dest = baos.toByteArray(); System.out.println(dest.length + "-->" + new String(dest, 0, baos.size())); }catch(IOException e) { e.printStackTrace(); }finally { if (null != baos) { try { // 4.关闭文件 baos.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
将图片 copy 成字节数组流 -> copy 到其他的文件. (这样可以实现图片的 copy)
所以, IO 操作都是 流对流.
package com.pratice.java300; import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.Closeable; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; /* * 1. 封装拷贝 * 2. 封装释放资源 */ public class FileUtils { public static void main(String[] args) { // 文件到文件 try { InputStream is = new FileInputStream("stanford.txt"); OutputStream os = new FileOutputStream("oo.txt"); copy(is, os); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } // 文件到字节数组 byte[] datas = null; try { InputStream is = new FileInputStream("plane.jpg"); ByteArrayOutputStream os = new ByteArrayOutputStream(); copy(is, os); datas = os.toByteArray(); System.out.println(datas.length); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } // 字节数组到文件 try { InputStream is = new ByteArrayInputStream(datas); OutputStream os = new FileOutputStream("p-copy.jpg"); copy(is, os); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static void copy(InputStream is, OutputStream os) { try { int len = -1; byte[] flush = new byte[5]; while (null != is && (len = is.read(flush)) != -1) { os.write(flush, 0, len); } }catch (IOException e) { e.printStackTrace(); }finally { // close(is, os); close2(is, os); } } public static void close(InputStream is, OutputStream os) { try { if (null != os) { os.close(); } if (null != is) { is.close(); } }catch(IOException e) { e.printStackTrace(); } } // 释放资源, Closeable... 是可变参数的意思 public static void close2(Closeable... ios) { for(Closeable io:ios) { try { if (null != io) { io.close(); } }catch(IOException e) { e.printStackTrace(); } } } // try.with.resource 可以自动释放资源. public static void copy2(String srcPath, String destPath) { // 1. 创建源 File src = new File(srcPath); File dest = new File(destPath); // 2. 选择流, 自动释放资源就是在 try括号内部的这个 is, os try(InputStream is = new FileInputStream(src); OutputStream os = new FileOutputStream(dest);) { int len = -1; byte[] flush = new byte[5]; while (null != is && (len = is.read(flush)) != -1) { os.write(flush, 0, len); } }catch (IOException e) { e.printStackTrace(); } } }
BufferedInputStream 和 BufferedOutputStream 提高IO 性能. 把读写维护了一个缓冲区buffer, 当buffer满了之后,再调用IO 操作. 这样可以介绍IO操作.

默认的这个 buffer 是 8k, 我们可以先不考虑修改这个大小.
释放时,只需要释放最外层的流,它内部的,它会自己释放.
下边代码, 可以看到,在字节流上直接套上buffer就可以了, 后面的处理方法都是完全一样的.
package com.pratice.java300; import java.io.BufferedInputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; public class IOTest04 { public static void main(String[] args) { // 创建源 File src = new File("stanford.txt"); InputStream is = null; try { is = new BufferedInputStream(new FileInputStream(src)); int len = -1; byte[] car = new byte[1024]; while (null != is && (len = is.read(car)) != -1) { String str = new String(car, 0, len); System.out.println(str); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { if (null != is) { is.close(); } } catch (IOException e) { e.printStackTrace(); } } } }
输出流也是一样的,直接套上字节缓冲流就可以了,所以copy函数, 也只是将try()里的声明加上字节缓冲流就可以了.
同样, 也有字符缓冲流. BufferedReader, BufferedWriter
逐行读取, 读取不到就返回空 null.
package com.pratice.java300; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; public class BufferCopyTest { public static void main(String[] args) { copy("stanford.txt", "xxx.txt"); } public static void copy(String srcPath, String destPath) { File src = new File(srcPath); File dest = new File(destPath); try(BufferedReader br = new BufferedReader(new FileReader(src)); BufferedWriter bw = new BufferedWriter(new FileWriter(dest));) { String line = null; int lineCount = 0; while ((line = br.readLine()) != null) { if (lineCount == 0) { lineCount++; } else { bw.newLine(); // 这种换行方式, 不会在文件末尾增加新行 } bw.write(line); // bw.newLine(); // 实际上, 这样操作在文件最后会多一个换行回车 } bw.flush(); }catch(IOException e) { e.printStackTrace(); } } }
字节流转换为字符流
如果是纯文本的文件, 而且给的是字节流,那么转换成字符流更加方便. (注意字符集)
InputStreamReader 读取字节 -> 转换成字符(解码, 根据字符集来解码)
OutputStreamWriter: 读取字符 -> 字节 (编码)
写的方法基本一样, 这里copy 一下得了.
读取网页作为字节流, 按照UTF-8 字符集转换为字符流, 将读取的网页写到 baidu.html 文件里.
package com.pratice.java300; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStreamReader; import java.io.OutputStreamWriter; import java.net.URL; public class BufferWeb { public static void main(String[] args) { convertWeb(); } public static void convertWeb() { try(BufferedReader reader = new BufferedReader( // 套这层, 用buffer new InputStreamReader( // 套这层: 字节流 -> 字符流 new URL("http://www.baidu.com").openStream(), "UTF-8")); BufferedWriter writer = new BufferedWriter( // 套这层, 用buffer new OutputStreamWriter( // 套这层: 字符流 -> 字节流 new FileOutputStream("baidu.html"), "UTF-8"));){ // 字节输出流到文件 String msg = null; while ((msg = reader.readLine()) != null) { writer.write(msg); writer.newLine(); } writer.flush(); }catch(IOException e) { e.printStackTrace(); } } }
数据流 (保留了数据类型)
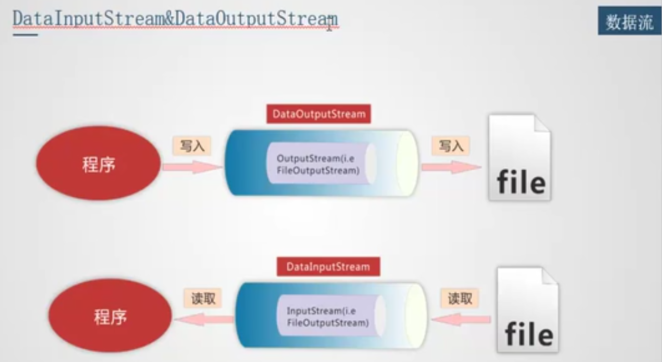
比如可以 readInt, 或者可以 writeInt 之类的. writeUTF("asdffda")

而且这个 baos 和 datas 都可以加 buffer 来增加性能
对象流

序列化(也叫持久化) 和 反序列化 (不是所有的对象都可以序列化), 想序列化必须实现序列化接口.
跟数据流代码很像.
打印流 (System.out 就是用这个实现的)
PrintStream ps = System.out;
CommonsIO
会有很多的 commons 的库. 一般公司有自己的commons库.
多个 jar 包 组成组件, 多个组件component 就组成框架了. CommonsIO 就是一个组件. CommonsIO 是 apache 基金会提供的组件.
可以通过 apache.org 看到提供的组件列表. 比如 kafka, hadoop 等
很多时候直接使用这个功能就好,代码都写好了.
CommonsIO 里边有 FileUtils
引用的办法:首先下载 window版的, 然后解压, 把 commons-io-2.6.jar 和 common-io-2.6-sources.jar(源码) copy 到项目里(新建一个libe文件夹)
解压后, 目录里有一个 docs 可以看到说明文档.
在 lib 文件夹中现在就有了这两个文件, 选中 commons-io-2.6.jar 然后右键 -> Build Path ->(Add to Build Path) -> 这样就自动进入 Referenced Libraries中了, 就可以直接用了.
想关联我们的源码时, 当点击鼠标想看对象时, 当出现如下图时, 点 Attach Source.. 就是关联源码
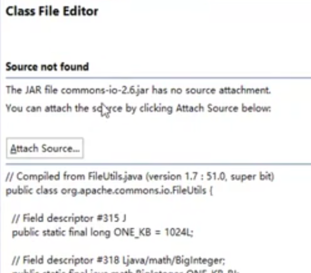
在这可以直接选择 work_plack , 因为刚刚你已经把源码 copy 到了lib 目录下.
总结
文件主要是流,从三个角度说
1)输入流,输出流
2)字节流,字符流, 字节和字符的转换流
3) 装饰流, 为了提高性能(buffer)
4) data 流
5) object 流, 序列化 -> 反序列
重点掌握 文件 copy.
固定套路(顺序步骤): 1,2,3,4
工作中主要还是使用 commonsIO 的. (我们写原生的代码还是比较少的, 这种类似的公共组件, 主要是借助知名公司的公共组件)