第一章:探索性数据分析
开始之前,导入numpy、pandas包和数据
#加载所需的库
import numpy as np
import pandas as pd
from pandas import DataFrame
#载入之前保存的train_chinese.csv数据,关于泰坦尼克号的任务,我们就使用这个数据
df=pd.read_csv("train_chinese.csv")
df.head(3)

1.6 了解你的数据吗?
教材《Python for Data Analysis》第五章
1.6.1 任务一:利用Pandas对示例数据进行排序,要求升序
# 具体请看《利用Python进行数据分析》第五章 排序和排名 部分
#自己构建一个都为数字的DataFrame数据
frame = DataFrame({'b': [4.3, 7, -3, 2], 'a': [0, 1, 0, 1], 'c': [-2, 5, 8, -2.5]})
print(frame)
'''
我们举了一个例子
pd.DataFrame() :创建一个DataFrame对象
np.arange(8).reshape((2, 4)) : 生成一个二维数组(2*4),第一列:0,1,2,3 第二列:4,5,6,7
index=[2,1] :DataFrame 对象的索引列
columns=['d', 'a', 'b', 'c'] :DataFrame 对象的索引行
'''
 【代码解析】
【代码解析】
pd.DataFrame() :创建一个DataFrame对象
np.arange(8).reshape((2, 4)) : 生成一个二维数组(2*4),第一列:0,1,2,3 第二列:4,5,6,7
index=['2, 1] :DataFrame 对象的索引列
columns=[‘d’, ‘a’, ‘b’, ‘c’] :DataFrame 对象的索引行
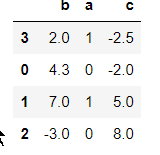
【问题】:大多数时候我们都是想根据列的值来排序,所以将你构建的DataFrame中的数据根据某一列,升序排列
frame.sort_values(by=['c'])
【思考】通过书本你能说出Pandas对DataFrame数据的其他排序方式吗?
根据索引的顺序排列 比如让b a c 升序 ->a b c sort_index(axis=1) ascending设置升序还是降序
【总结】下面将不同的排序方式做一个总结
1.让行索引升序排序
2.让列索引升序排序
3.让列索引降序排序
4.让任选两列数据同时降序排序
frame.sort_index(axis=0,ascending=True) #默认 行索引+升序
frame.sort_index(axis=1,ascending=True) #默认 列索引+升序
frame.sort_index(axis=1,ascending=False) #默认 列索引+降序
frame.sort_values(by=['a','c'],ascending=True)
1.6.2 任务二:对泰坦尼克号数据(trian.csv)按票价和年龄两列进行综合排序(降序排列),从这个数据中你可以分析出什么?
df.sort_values(by=['票价','年龄'],ascending=False).head(10)

【思考】排序后,如果我们仅仅关注年龄和票价两列。根据常识我知道发现票价越高的应该客舱越好,所以我们会明显看出,票价前20的乘客中存活的有14人,这是相当高的一个比例,那么我们后面是不是可以进一步分析一下票价和存活之间的关系,年龄和存活之间的关系呢?当你开始发现数据之间的关系了,数据分析就开始了。
当然,这只是我的想法,你还可以有更多想法,欢迎写在你的学习笔记中
df.sort_values(by=['乘客等级(1/2/3等舱位)','年龄'],ascending=True).head(10)
舱位yue高级 死亡率越低 这种情况下票价与年龄影响不大

因为排序只能对数值进行排序
1.6.3 任务三:利用Pandas进行算术计算,计算两个DataFrame数据相加结果
# 具体请看《利用Python进行数据分析》第五章 算术运算与数据对齐 部分
#自己构建两个都为数字的DataFrame数据
frame1_a = pd.DataFrame(np.arange(9.).reshape(3, 3),
columns=['a', 'b', 'c'],
index=['one', 'two', 'three'])
frame1_b = pd.DataFrame(np.arange(12.).reshape(4, 3),
columns=['a', 'e', 'c'],
index=['first', 'one', 'two', 'second'])
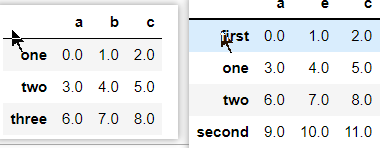
frame1_a
frame1_b
将frame_a和frame_b进行相加
frame1_a+frame1_b
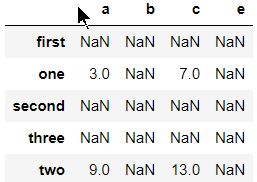
【提醒】两个DataFrame相加后,会返回一个新的DataFrame,对应的行和列的值会相加,没有对应的会变成空值NaN。
当然,DataFrame还有很多算术运算,如减法,除法等,有兴趣的同学可以看《利用Python进行数据分析》第五章 算术运算与数据对齐 部分,多在网络上查找相关学习资料
1.6.4 任务四:通过泰坦尼克号数据如何计算出在船上最大的家族有多少人?(‘兄弟姐妹个数’+‘父母子女个数’)
m = max(df['堂兄弟/姐妹个数']+df['父母与小孩个数'])
print(m)
#排序后第一hang相加即可
df.sort_values(by=['堂兄弟/姐妹个数','父母与小孩个数'],ascending=False).head(10)
10

1.6.5 任务五:学会使用Pandas describe()函数查看数据基本统计信息
#(1) 关键知识点示例做一遍(简单数据)
# 具体请看《利用Python进行数据分析》第五章 汇总和计算描述统计 部分
#自己构建一个有数字有空值的DataFrame数据
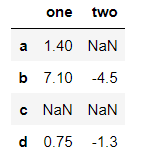
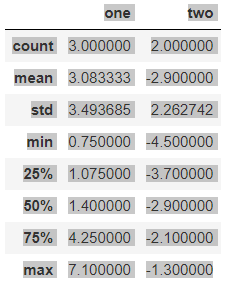
frame2 = pd.DataFrame([[1.4, np.nan],
[7.1, -4.5],
[np.nan, np.nan],
[0.75, -1.3]
], index=['a', 'b', 'c', 'd'], columns=['one', 'two'])
frame2
frame2.describe()
1.6.6 任务六:分别看看泰坦尼克号数据集中 票价、父母子女 这列数据的基本统计数据,你能发现什么
#代码
print(df['票价'].describe())
#还没啥想法
print(df['父母与小孩个数'].describe())

【思考】从上面数据我们可以看出,试试在下面写出你的看法。然后看看我们给出的答案。
当然,答案只是我的想法,你还可以有更多想法,欢迎写在你的学习笔记中。
多做几个组数据的统计,看看你能分析出什么?
【思考】有更多想法,欢迎写在你的学习笔记中。
【总结】本节中我们通过Pandas的一些内置函数对数据进行了初步统计查看,这个过程最重要的不是大家得掌握这些函数,而是看懂从这些函数出来的数据,构建自己的数据分析思维,这也是第一章最重要的点,希望大家学完第一章能对数据有个基本认识,了解自己在做什么,为什么这么做,后面的章节我们将开始对数据进行清洗,进一步分析。