概述
深度学习作为机器学习领域的分支,近年来在图像识别与检索、自然语言处理、语音识别等诸多领域中都展现出非常优越的性能。深度学习以人工神经网络为基本架构,通过对数据表征进行学习,将底层特征表示转化为高层特征表示,通过多层网络模型完成学习任务。
长期以来,深度学习研究人员致力于开发更深、更大的模型,达到更高的精度和准确度,同时也导致模型具有大量参数(例如 VGG16 有一亿三千多万个参数),存储空间占用率高,计算复杂的特性。为了达到优越的学习效果,必须使用 GPU 加速。对硬件的高要求使得深度网络模型在实际应用中受到限制,诸如手机等便携式以及嵌入式设备,无法满足深度学习的大规模计算要求。
因此,需要进行模型压缩。压缩网络模型的最终目的是产生小规模、高精度及准确度的模型。
模型压缩是指对深度学习使用的深度网络进行重构、简化以及加速的技术。
- 重构:指利用深度网络的典型模块重新设计一个简单的网络结构;
- 简化:指在现有深度网络结构上进行参数压缩、层次以及维度的缩减;
- 加速:指提高深度网络训练、预测的速度。
网络经过训练之后,参数存在大量冗余,这些冗余的参数是不重要的、可以删除的,去除这些参数并不影响网络的精度。由于参数减少,网络的计算得以简化并且速度大幅提高,从而能提升网络的整体性能。
模型压缩的思想最早可以追溯到1989年的Yann LeCun等前辈提出的论文,利用信息论的思想,通过删除网络中不重要的权重,使得神经网络能够更好地泛化,提高学习速率,达到压缩网络尺寸的目的。当时,并没有什么深度网络,并且连个深度网络都很难训练出来,不知道LeCun等是由于怎样的需求想到了模型压缩的思想。
2015年,Han发表的Deep Compression是一篇对于模型压缩方法的综述型文章,将裁剪、权值共享和量化、编码等方式运用在模型压缩上,取得了非常好的效果,作为ICLR 2016的最佳论文。
研究框架
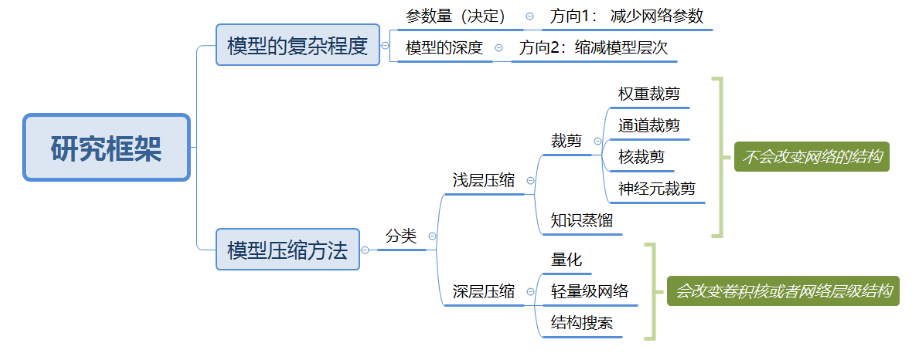

浅层压缩
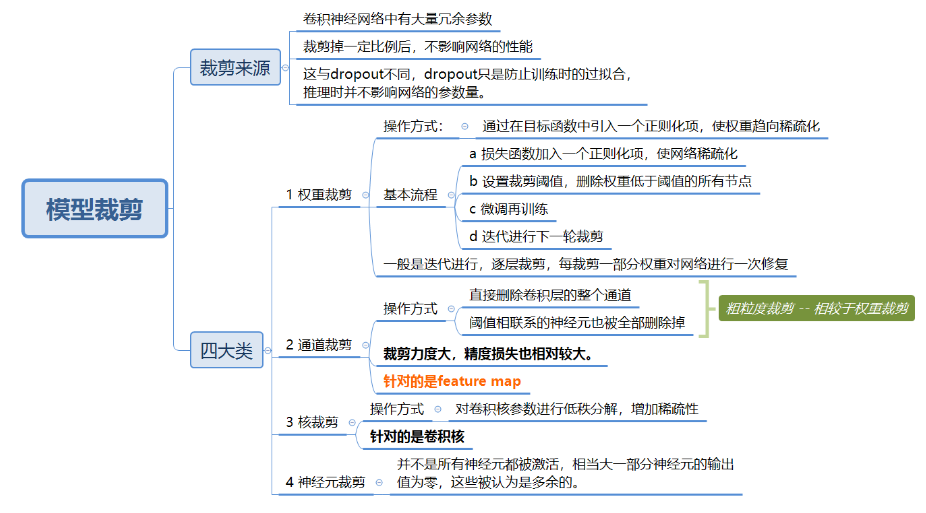
模型裁剪
诸如卷积神经网络这种网络结构,存在大量的冗余参数,可以在不影响网络性能的基础上,裁剪掉一部分冗余参数。


知识蒸馏
采用迁移学习,通过将预先训练好教师模型输出作为监督信号去训练另外一个轻量化网络。
这种模型压缩是一种将大型教师网络的知识转移到较小的学生网络的方法,将复杂、学习能力强的教师网络学到的特征表示蒸馏出来,传递给参数量小、学习能力弱的学生网络,一般可以提高学生网络的精度。
将教师模型的泛化能力传递给学生模型的一个有效方法是将教师模型产生的分类概率作为训练学生模型的"软目标",以指导学生网络进行训练,实现知识迁移。
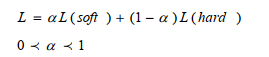
对于上述内容的理解
知识蒸馏,实际上是一种将深度模型的能力传授给轻量化模型的过程。将训练好的深度模型作为教师,作为一种软目标。将轻量化模型作为学生,学生(轻量化模型)不仅学习教师(深度模型)的知识-- 软目标,也接触社会,理解自己对人生的感悟,即真实值 -- 硬目标。
通过这种操作,使其学习到深度模型可以表达的能力,也避免深度模型自身的错误。也可谓是青出于蓝的模型塑造过程。
重点idea就是提出用soft target来辅助hard target一起训练,而soft target来自于大模型的预测输出。这里有人会问,明明true label(hard target)是完全正确的,为什么还要soft target呢?
hard target 包含的信息量(信息熵)很低,soft target包含的信息量大,拥有不同类之间关系的信息(比如同时分类驴和马的时候,尽管某张图片是马,但是soft target就不会像hard target 那样只有马的index处的值为1,其余为0,而是在驴的部分也会有概率。)[5]
这样的好处是,这个图像可能更像驴,而不会去像汽车或者狗之类的,而这样的soft信息存在于概率中,以及label之间的高低相似性都存在于soft target中。但是如果soft targe是像这样的信息[0.98 0.01 0.01],就意义不大了,
知识蒸馏的过程还可以与注意力机制相结合,强迫学生卷积神经网络模拟强大老师网络注意力映射,从而可以模仿教师网络。详情可见paper。
深层压缩
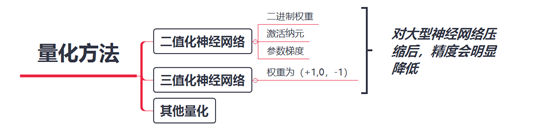
量化
量化就是将神经网络的浮点运算转换为定点运算。有利于:
- 移动设备上实现网络的实时运行
- 对部署云计算也有帮助
神经网络中的运算为浮点运算,一般而言,参数都是FP32(32位浮点数),通过量化,可以将一个参数采用低精度FP16(半精度浮点)和
- INT8(8位定点整数)
- INT4(4位定点整数)
- INT1 (1位定点整数)
表示。
何为定点?
定点表示,即约定机器数中的小数点位置是固定不变的。根据小数点固定的位置不同可以分为定点小数和定点整数。

浮点量化的步骤:
- 权重矩阵汇总找到参数最小值min,最大值max,确定映射区间Xscale和零点量化值Xzero_point.
- 每个FP32值转化为INT8值,公式如下,类似于归一化的过程:

量化卷积层通常需要 8bits、全连接层需要 4bits 。
轻量级网络
设计轻量级网络,直接适用于移动和嵌入式设备。比较出名的就是MobileNet中提出的深度可分离卷积结构。
- MobileNet
基于深度可分离卷积,核心思想就是将卷积核分解:
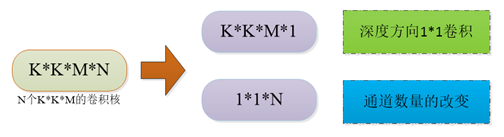
其计算量相较于标准卷积下降8-9倍,同时精度下降很少(ImageNet上下降1%)。
详情可见:https://www.cnblogs.com/monologuesmw/p/12270137.html
- ShuffleNet
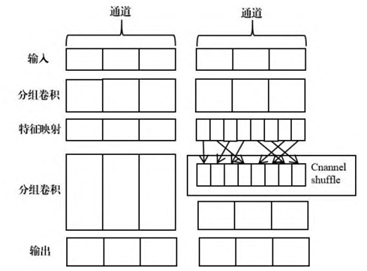
深度可分离卷积实现了网络压缩的目的,但是 1×1 卷积的计算消耗还是比较大, MobileNet在 1×1 的卷积中花费了 94.86%的计算时间,并且占有整个网络模型中 75%的参数量。
为了进一步减少参数量,ShuffleNet在1*1卷积上采用分组(group)操作。提出一种channel shuffle的方法,使分组后的1*1卷积可以共享信息。如下图,左侧是没有信息互通,右侧是使用了channel shuffle。
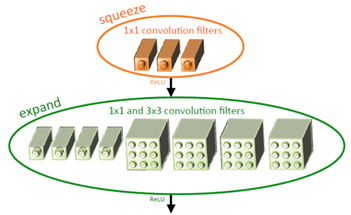
- SqueezeNet
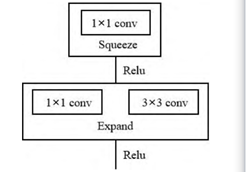
SqueezeNet使用1*1卷积进行模型的压缩-扩张。如下图所示,模块由Squeeze卷积层和Expand层组成。Squeeze卷积层使用1*1卷积,Expand层使用1*1卷积核3*3卷积的组合。
这三部分构成了模型的核心部件Fire Module,如下图所示:
网络结构搜索
网络结构搜索一般采用神经结构搜索方法设计新的基线网络,通过寻找新的尺度均匀地缩放网络维度。MobileNet V3便是通过NAS模块级搜索和NetAdapt层级搜索自动设计出的网络结构。
总结
本文阐述了现有模型压缩的一些方法,其中,模型裁剪和知识蒸馏使用频率较高,百度使用SE-ResNeXt在FGVC 2020比赛中占据榜首,其中便使用了知识蒸馏的方式。
本篇仅是对模型压缩的一个扫盲式的总结,具体的操作方式和各种tricks需要在具体的文献和代码中挖掘。