要用server来监控底下各个客户端的时间,使用自带的监控项 system.localtime[
然后使用触发器函数fuzzytime (sec)(检查项目时间戳和zabbix服务器时间相差多大。sec为秒数,支持float,int,返回值 0,1,fuzzytime(60)=0 → 如果时间差超过60秒,就会检测到一个问题)来判定时间的偏移量,从而实现server和各个agent的时间同步
system.localtime的类型设置为被动式的取值方式,单位设成自定的unixtime,周期自定义
在配置的时候需要先将server等设备的时间同步,客户那里配置的有ntp服务,所以在设备商直接安装ntp即可,
yum -y insstall ntp
vim /etc/ntp.conf 在 最后添加上客户的ntp时钟服务器地址
server 192.168.1.15 prefer
systemctl start ntpd
systemctl enable ntpd
ntpq -pn 查询当前时间和时间服务器的偏移量
ntpdate -u 10.10.238.60 直接刷新本地时间,使之与时间服务器同步
实际上如果不着急的话不用ntpdate -u来刷新时间,这样刷新的话直接修改时间,
用ntp服务修改了server show database数据库的时间,由于server设备上的时间超前4m,强行将时间调回,将这4分钟的任务瞬间堆起来了,导致队列中超过十分钟的任务飙升,在查询一些zabbix信息的时候显示 一排黄字 zabbix server is not running,the infomation displayed not be current, server崩溃然后自己重启,过了多半个小时队列中堆积的任务才慢慢消下去。
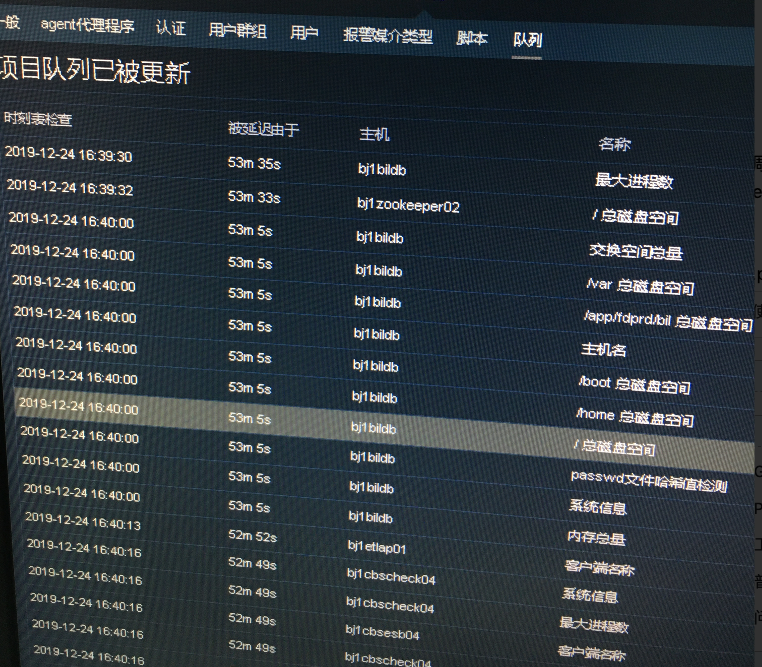
这些队列在慢慢的恢复中
队列清理过程

队列是一个zabbix server的概览,可以看到其中各任务的耗时情况,如果超过10分钟多的监控项,就应该查看这个agent是否有问题,是重复添加设备了还是说其他的策略没开,等等