自编码器生成模型入门
之所以讲解本章内容,原因有三。
- 生成模型对大多数人来说是一个全新的领域。大多数人一开始接触到的往往都是机器学习中的分类任务——也许因为它们更为直观;而生成模型试图生成看起来很逼真的样本,所以人们对它了解甚少。考虑到自编码器(最近GAN的前身)丰富的资源和研究,所以选择在一个更简单的环境介绍生成模型。
- 生成模型非常具有挑战性。由于生成模型代表性不足,大多数人不知道典型的生成结构是什么样子的,也不知道面临何种挑战。尽管自编码器在许多方面与最常用的模型相近(例如,有一个明确的目标函数),但它们仍然展现出许多GAN也面临的挑战,如评估生成样本质量有多困难。
- 生成模型是当前文献中的研究点。自编码器本身有它自己的用途。自编码器是一个活跃的研究领域,甚至在某些领域是最前沿的并且被许多GAN模型显示地采用。
一、生成模型简介
你应该对“深度学习如何获取图像中的原始像素并将其转化为类别的预测”这种操作并不陌生。例如,可以取包含图像像素的3个矩阵(每个颜色通道各1个)在一个转换系统中传递,最后得到一个数字。如果想反过来做,该怎么办呢?
从要生成内容的描述指令开始,最后在转换系统的另一端得到图像。这是最简单、最非正式的生成模型。
更正式一点,取一个特定的描述指令(z)——简单地假设它是介于0和9之间的数字——并尝试得到一个生成的样本(\(x^*\))。理想情况下\(x^*\)应该和另一个真实的样本x看起来一样真实。描述指令z是潜在空间( latent space)中的某个激励,我们不会总是得到相同的输出\(x^*\)。这个潜在空间是一个习得的表征——希望它按人类思考方式对人们有意义(“解离”)。不同的模型将学习相同数据的不同潜在表征。
潜在空间是数据的隐式表示。自编码器不是在未压缩的版本中表达单词或图像(例如机器学习工程师,或图像的JPEG编码器),而是根据对数据的理解来对其进行压缩和聚类。
二、自编码器如何用于高级场景
顾名思义,自编码器可以帮助我们对数据进行自动编码,它由两部分构成:编码器和解码器。为了便于说明,我们考虑这样一个用例:压缩。
三、什么是GAN的自编码器
自编码器是一种神经网络,它的输入和输出是一致的,目标是使用稀疏的高阶特征重新组合来重构自己。
自编码器与GAN的一个关键区分点是:我们用一个损失函数对整个自编码器网络进行端到端的训练,而GAN的生成器和判别器分别有损失函数。
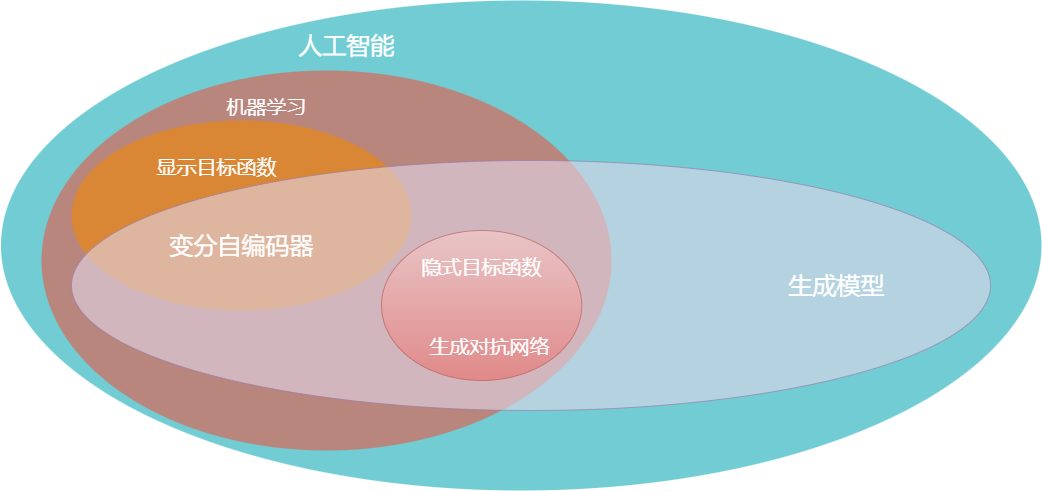
现在看看自编码器和GAN所处的位置,如下图所示。两者都是生成模型,且都是人工智能(AI)和机器学习(ML)的子集。
端到端思想:深度学习的一个重要思想即“端到端”的学习方式,属表示学习的一种。这是深度学习区别于其他机器学习算法的最重要的一个方面。过去解决一个人工智能问题(以图像识别为例)往往通过分治法将其分解为预处理、特征提取与选择、分类器设计等若干步骤。分治法的动机是将图像识别的母问题分解为简单、可控且清晰的若干小的子问题。不过分步解决子问题时,尽管可在子问题上得到最优解,但子问题上的最优并不意味着就能得到全局问题的最后解。对此,深度学习则为我们提供了另一种范式,即“端到端”学习方式,整个学习流程并不进行人为的子问题划分,而是完全交给深度学习模型直接学习从原始输入到期望输出的映射。相比分治策略,“端到端”的学习方式具有协同增效的优势,有更大可能获得全局最优解。
在这种情况下,对于自编码器(或其变分形式,VAE),我们有一个试图优化的已明确写出的函数(一个代价函数);但在GAN中没有像均方误差、准确率或ROC曲线下面积这样明确的指标进行优化。GAN有两个不能写在一个函数中的相互竞争的目标。
四、自编码器的构成
与机器学习中的许多进展一样,自编码器的高级理念很直观,并遵循以下简单步骤,如下图所示。
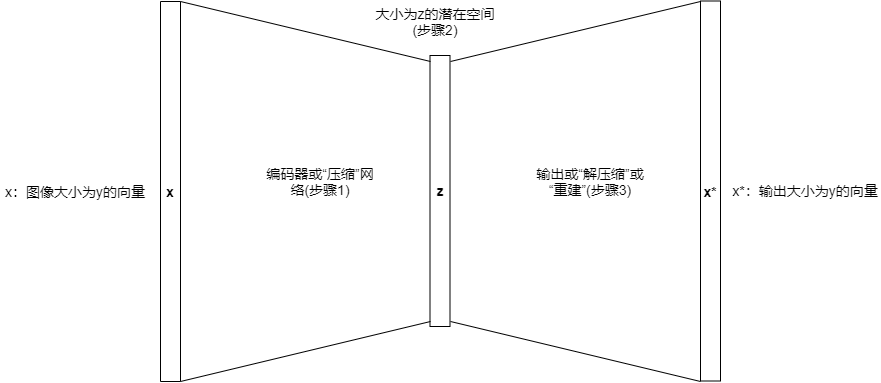
步骤解释:
(1)压缩关于机器学习工程师的所有知识。
(2)将其组合到潜在空间(给祖母的信中)。当利用对单词的理解作为解码器(步骤3)重建一个含义有损的版本时,你就得到了一个与原始输入(即你的想法)在同一个空间的(祖母的头脑中)想法的表示。
(1)编码器网络:取一个表示x(如一个图像),然后用学过的编码器(通常是一个单层或多层的神经网络)将维数从y减小到z。
(2)潜在空间(z):在训练时,试图建立具有一定意义的潜在空间。潜在空间通常是有较小维度的表示,起着中间步骤的作用。在这种数据的表示中,自编码器试图”组织其思想“。
(2)解码器网络:用解码器将原始对象重建到原始的维度,这通常由一个神经网络完成。它是编码器的镜像,对应着z到x*的步骤。我们可以用解码的逆过程,从潜在空间的256个像素长的向量中得到784个像素长的重构向量(28x28大小的图像)。
下面给出一个自编码器训练过程的示例。
- 将图像x通过自编码器输入。
- 得到x*,即重建的图像。
- 评估重建损失,即x和x*之间的差异:
- 使用图像x和x*的像素之间的距离(如MAE)完成;
- 给定一个显示目标的函数(||x-x*||),以通过梯度下降的形式进行优化
因此我们的任务就是找到解码器和编码器的参数,这些参数将最小化我们用梯度下降法更新的重构损失。
五、自编码器的使用
尽管自编码器很简单,但是有很多理由值得我们关注它。
- 首先,我们可以自由地压缩!这是因为上图中的中间步骤(2)在潜在空间的维度上変成了一个智能缩减的图像或对象。从理论上讲,这可能比原始输入小几个数量级,而且显然不是无损的,但是如果愿意的话,我们可以随意利用这种副作用。
- 仍使用潜在空间,我们可以联想到许多实际应用,如单类分类器(one- class classifier)——一种异常检测算法,可以在缩减的可更快搜索的潜在空间中查看项目,以检查和目标类别的相似性。这就可以用于搜索(信息检索)或者异常检测(比较潜在空间中的接近度)。
- 另一个用例是黑白图像的数据去噪或彩色化。如果有旧的/有噪声的一张照片或者一段视频——例如第二次世界大战时期的影像,那么可以减少它们的噪点并重新着色。因此自编码器与GAN的相似之处在于,GAN在这类应用程序中也表现很出色。
- 有些GAN的架构,例如BEGAN,将自编码器用作其架构的一部分以帮助稳定训练。
- 训练自编码器不需要带标签的数据。这让我们更轻松,因为不需要我们去寻找标签就可以自训练。
- 最后同样重要的是,可以用自编码器生成新图像。自编码器已应用于生成从数字到人脸到卧室的任何事物,但通常图像的分辨率越高,性能就越差,因为输出往往看起来很模糊。但是对于MINST数据集和其他低分辨率图像来说,自编码器的效果很好。
这些都可以做到,因为我们找到了已拥有数据的新表示。这种表示很有用,可以提取出压缩信息的核心信息;基于隐式表达,它也很容易操作或生成新的数据。
六、变分自编码器
变分自编码器( Variational Auto- Encoders, VAE)作为深度生成模型的一种形式,是于2014年提出的生成式网络结构。
它以概率的方式描述对潜在空间的观察,在数据生成方面表现出了巨大的应用价值。
VAE和生成对抗网络( Generative AdversarialNetworks, GAN)被视为无监督式学习领域最具硏究价值的方法之一。
自编码器很好地解決了图像的编码解码问题,但如果使用随机数产生隐含变量并不能输出正确的图像。因为输入图像编码的隐含变量可能没有一个正确的分布。
为了能够让隐含变量服从一定的分布,就需要对隐含变量进行限制。具体的方式是限制隐含变量的KL散度( Kullback Leibler Divergence)。
KL散度是两个概率分布间差异的非对称性度量。假设两个分布P、Q的概率密度函数为p(x)和q(x),定义两个分布之间的KL散度如下所示。
为了让隐含变量能够服从预设的分布,可以令Q为预设的分布,P为隐含变量的分布,令这两个分布的KL散度最小,这样就能让P分布逐渐逼近Q分布。
为了解決这个问题,在VAE模型中使用了重参数化( Reparameterization)的技巧。所谓重参数化,就是在实际的模型中,编码器并不会生成隐含变量,而是输出隐含变量服从的参数,然后使用这些参数产生服从一定分布的隐含变量。
以正态分布为例,在正态分布中,重要的参数有两个,\(\mu\)代表分布的平均值,\(\sigma\)代表分布的标准差,这里用N(\(\mu, \sigma^2\))来表示相应的正态分布。编码器的目的就是用来生成\(\mu\)和\(\sigma\)两个参数。
七、无监督学习
无监督学习( unsupervised learning)是一种从数据本身学习而不需要关于这些数据含义的附加标签的机器学习。例如,聚类是无监督的,因为只是试图揭示数据的底层表示;异常检测是有监督的,因为需要人工标记的异常情况。
我们可以了解无监督机器学习为何与众不同,可以使用任何数据而不必为特定目的对其进行标记。我们可以使用任何互联网上的数据而不必为关心的每一种表示标记每个样本,例如,这张图片中有只狗吗?有辆车吗?
在监督学习中,如果数据没有针对确切任务的标签,那么别的(几乎)所有标签都可能是没用的。如果你有一个可以对谷歌街景中的汽车分类的分类器,想对动物进行分类但是没有这些动物图像的标签,这种情况下使用相同数据集训练一个动物分类器基本上是不可能的。即使这些样本中经常出现动物,也需要标注者重新标注同样的谷歌街景数据集中的动物。
本质上,我们需要在了解具体用例之前就考虑到数据的应用,这很困难!但是对于许多压缩类型的任务,你总是有带标记的数据,即数据本身。 研究人员把这种类型的机器学习称为自监督。
由于训练数据也充当了标签,从一个关键的角度来看,训练许多这样的算法会容易得多——毕竟现在有更多的数据可以处理。
1. 自编码器
自编码器由两个神经网络组成:编码器和解码器。两者都有激活函数,且只为每个函数使用一个中间层,这意味着每个网络中有两个权重矩阵——对于编码器网络,一个从输入到中间层,一个从中间层到潜在空间;对于解码器网络,又有一个从潜在空间到不同的中间层和一个从中间层到输出的权重矩阵。如果每个网络都只有一个权重矩阵,那么过程将类似于主成分分析(Principal Component Analysis,PCA)的成熟分析技术。