HttpClient:
场景需求如下:
1、项目中需要与一个基于HTTP协议的第三方的接口进行对接
2、项目中需要动态的调用WebService服务(不生成本地源码)
3、项目中需要利用其它网站的相关数据
这些需求可能或多或少的会发生在平时的开发中,针对每种情况,可能解决方案不止一种。本文使用HttpClient这种工具来讲解HttpClient的相关知识,以及如何使用HttpClient完成上述需求。
HttpClient 不是浏览器?
有人说,HttpClient不就是一个浏览器嘛。。。
可能不少人对HttpClient会产生这种误解,他们的观点是这样的:既然HttpClient是一个HTTP客户端编程工具,那不就相当于是一个浏览器了吗?无非它不能把HTML渲染出页面而已罢了。
其实HttpClient不是浏览器,它是一个HTTP通信库,因此它只提供一个通用浏览器应用程序所期望的功能子集,最根本的区别是HttpClient中没有用户界面,浏览器需要一个渲染引擎来显示页面,并解释用户输入
HttpClient 是什么?
HTTP 协议可能是现在 Internet 上使用得最多、最重要的协议了,越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资源。
虽然在 JDK 的 java.net 包中已经提供了访问 HTTP 协议的基本功能,但是对于大部分应用程序来说,JDK 库本身提供的功能还不够丰富和灵活。
HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
为什么要用HttpClient,它跟同类产品有什么区别呢?
1):提到HttpClient,就不得不提jdk原生的URL了。
jdk中自带了基本的网络编程,也就是java.net包下的一系列API。通过这些API,也可以完成网络编程和访问。
此外,另一个开源项目jsoup,它是一个简单的HTML解析器,可以直接解析指定URL请求地址的内容,它可以通过DOM方式来取数据,也是比较方便的API。
那既然已经有这些工具了,为什么还是有好多好多使用HttpClient的呢?
这里其实是有一个错误的认识:Jsoup是解析器不假,但它跟HttpClient不是同类产品(类似Hibernate和MyBatis),实际上日常使用通常会用HttpClient配合Jsoup做网页爬虫。
HttpClient还是有很多好的特点(摘自Apache HttpClient官网):
1、基于标准、纯净的java语言。实现了HTTP1.0和HTTP1.1;
2、以可扩展的面向对象的结构实现了HTTP全部的方法(GET, POST等7种方法);
3、支持HTTPS协议;
4、通过HTTP代理建立透明的连接;
5、利用CONNECT方法通过HTTP代理建立隧道的HTTPS连接;
6、Basic, Digest, NTLMv1, NTLMv2, NTLM2 Session, SNPNEGO/Kerberos认证方案;
7、插件式的自定义认证方案;
8、便携可靠的套接字工厂使它更容易的使用第三方解决方案;
9、连接管理器支持多线程应用;支持设置最大连接数,同时支持设置每个主机的最大连接数,发现并关闭过期的连接;
10、自动处理Set-Cookie中的Cookie;
11、插件式的自定义Cookie策略;
12、Request的输出流可以避免流中内容直接缓冲到socket服务器;
13、Response的输入流可以有效的从socket服务器直接读取相应内容;
14、在HTTP1.0和HTTP1.1中利用KeepAlive保持持久连接;
15、直接获取服务器发送的response code和 headers;
16、设置连接超时的能力;
17、实验性的支持HTTP1.1 response caching;
18、源代码基于Apache License 可免费获取。
HttpClient 能干嘛?
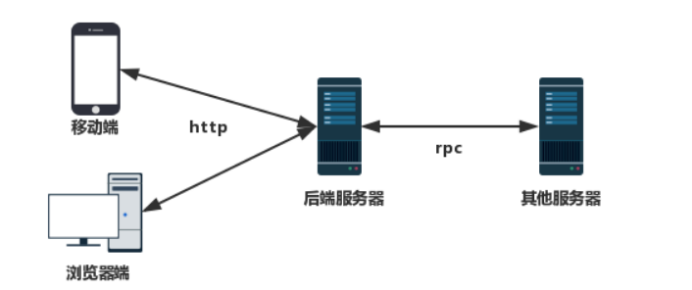
在后端开发过程中,后端服务不一定部署在一台服务器上,所以我们需要一种技术可以实现后端调用其他后端的服务,这种调用被称为RPC(远程过程调用),如下图所示:
HttpClient编写程序流程总结:
POM:
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.2</version>
</dependency>
流程:
1、创建HttpClient对象
这儿使用的是org.apache.http.impl.client.CloseableHttpClient,他是HttpClient接口的一个实例,创建该对象的最简单方法:CloseableHttpClient client = HttpClients.createDefault();
HttpClients是创建CloseableHttpClient的工厂,采用默认的配置来创建实例,一般情况下我们就用这个默认的实例就足够,后面我们可以去看下怎么定制自己需求配置的来创建HttpClient接口的实例。如果你去看这个函数的源代码,你可以看到
org.apache.http.client.CookieStore,org.apache.http.client.config.RequestConfig等等都是采用默认的。
2、创建某种请求方法的实例
创建某种请求的实例,并指定请求的url,如果是get请求,创建对象HttpGet,如果是post 请求,创建对象HttpPost。
类型的还有 HttpHead, HttpPost, HttpPut, HttpDelete, HttpTrace, 还有 HttpOptions。分别对应HEAD、POST PUT、DELETE、TRACE、OPTIONS方法,每个方法是做什么的如下表:

可以看得到在Http协议中,只有post方法和put方法的请求里面有实体
3、如果有请求参数的话,Get方法直接写在url后面,例如

或者使用setParameter来设置参数:
使用 URIBuilder 对路径请求信息进行封装。
http://www.google.com/search?q=httpclient&btnG=Google+Search&aq=f&oq=

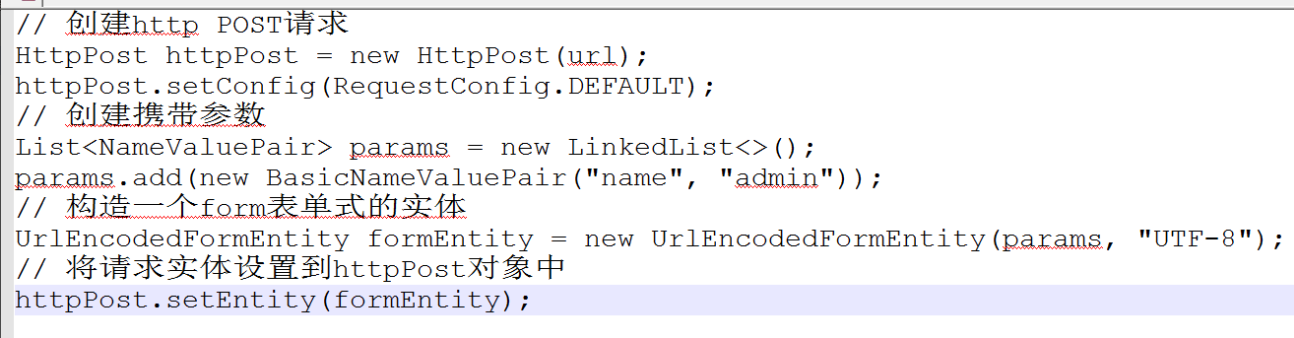
POST 请求也可以使用 此方式进行携带参数。(携带参数有多种)
在介绍另外几种:

3):发送请求
调用CloseableHttpClient对象的execute(HttpUriRequest request)发送请求,该方法返回一个CloseableHttpResponse对象。
CloseableHttpResponse response = client.execute(httpPost);
很明显CloseableHttpResponse就是用了处理返回数据的实体,通过它我们可以拿到返回的状态码、首部、实体等等我们需要的东西。
4):获取请求结果
调用CloseableHttpResponse的getAllHeaders()、getHeaders(String name)等方法可获取服务器的响应头;
调用CloseableHttpResponse的getEntity()方法可获取HttpEntity对象,该对象包装了服务器的响应内容。程序可通过该对象获取服务器的响应内容

通过CloseableHttpEntity的getEntity取得实体之后,有两种处理结果的方法,
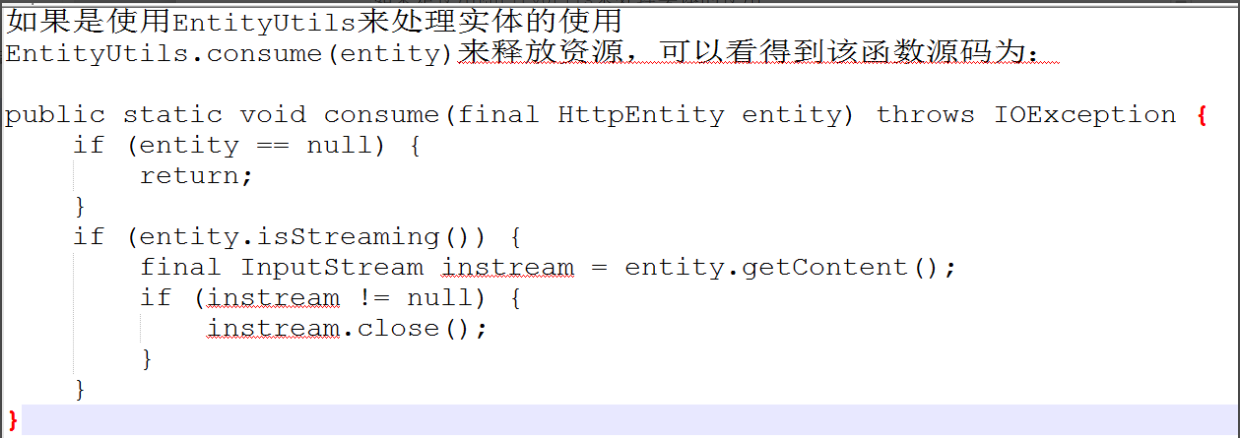
方法一:使用EntityUtils来处理。
该类是官方提供的一个处理实体的工具类,toSting方法将返回的实体转换为字符串,
但是官网不建议使用这个,除非响应实体从一个可信HTTP服务器发起和已知是有限长度的。
方法二:使用InputStream来读取
因为httpEntity.getContent方法返回的就是InputStream类型。
这种方法是官网推荐的方式,需要记得的是要自己释放底层资源。
关闭连接释放资源: