步骤:
1.准备utf-8编码的文本文件file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=)
7.排除语法型词汇,代词、冠词、连词等无语义词
8.输出TOP(20)
完成:
1.英文小说 词频统计
2.中文小说 词频统计
一、英文词频统计
fo = open('xiaoshuo.txt', 'r', encoding='utf-8')
stra = fo.read().lower()
fo.close()
print(stra) #1.准备utf-8编码的文本文件file 2.通过文件读取字符串 str
sep = ',.;!'
for ch in sep:
stra = stra.replace(ch,'') #进行预处理,清除掉sep中存在的标点符号
print(stra)
strList=stra.split(' ')
print(len(strList),strList) #分解提取单词,转化为列表list
strSet = set(strList)
print(len(strSet),strSet) #转化为集合
strDict = {}
for world in strSet:
strDict[world] = strList.count(world)
print(len(strDict),strDict) #转化为字典,计算上一个集合中每个单词出现的次数
wcList = list(strDict.items())
print(wcList) #将字典中的目录转化为列表输出
wcList.sort(key=lambda x:x[1],reverse= True)
print(wcList) #按降序输出
e = {'a','the','an','and','i','or','of'}
strSet = strSet - e
print(len(strSet),strSet) #排除语法型词汇,代词、冠词、连词等无语义词
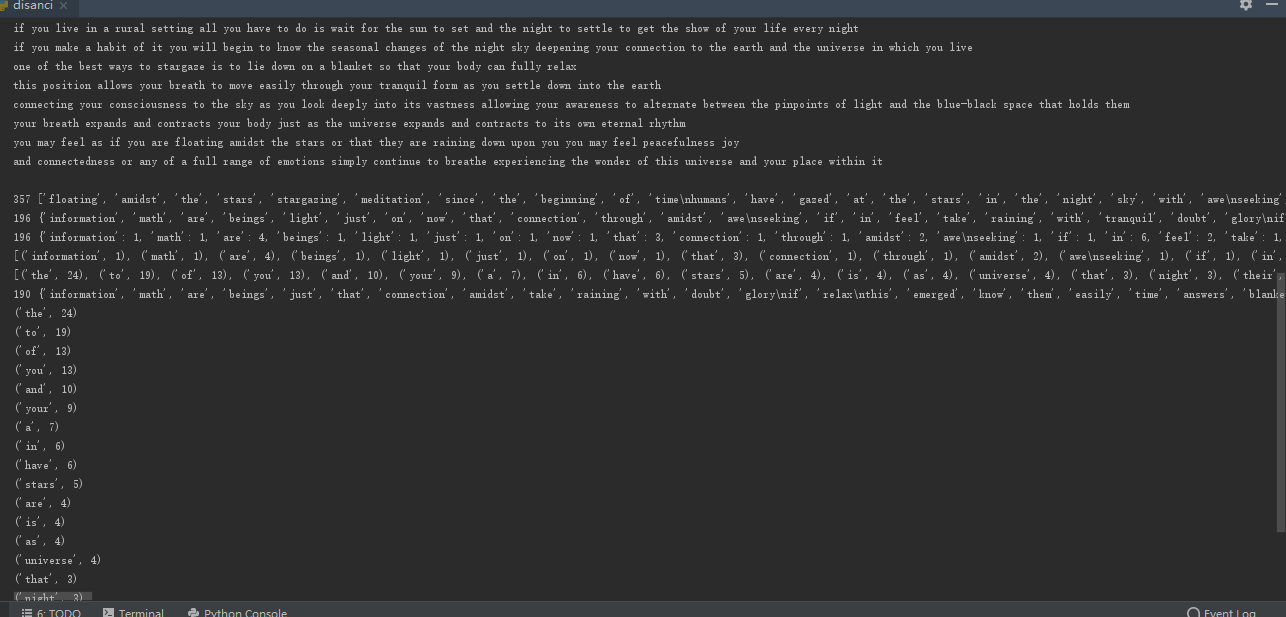
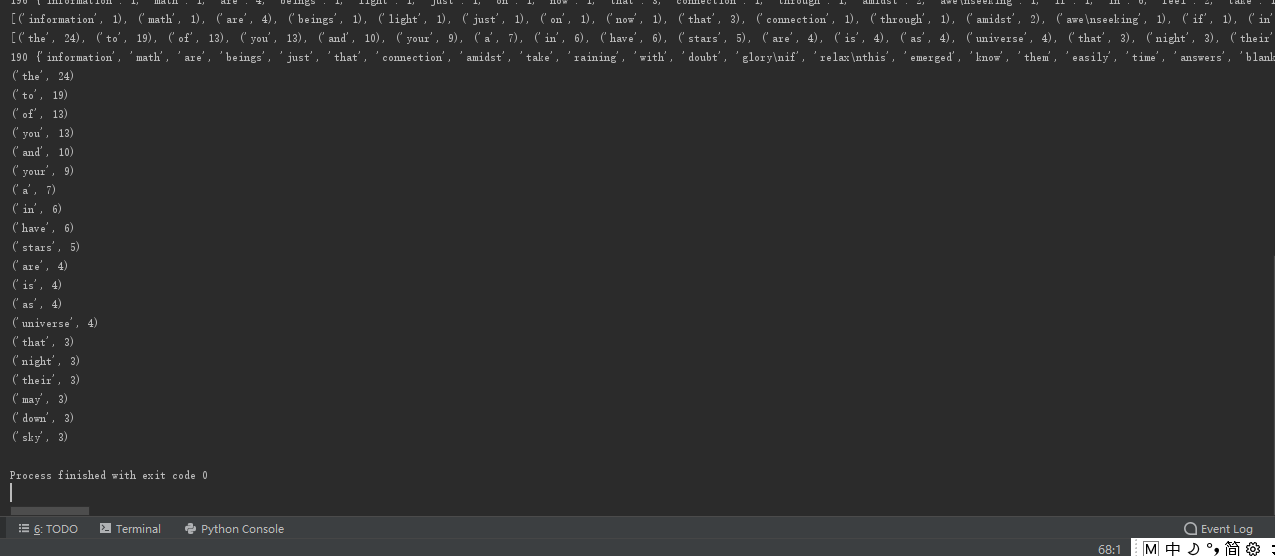
for i in range(20):
print(wcList[i]) #TOP20输出
运行结果:

二、中文词频统计
import jieba
of = open('zhongwen.txt','r',encoding='utf-8')
strb = of.read().lower()
of.close()
print(strb)
print(list(jieba.cut(strb)))
print(list(jieba.cut(strb,cut_all=True)))
print(list(jieba.cut_for_search(strb)))
运行结果:
