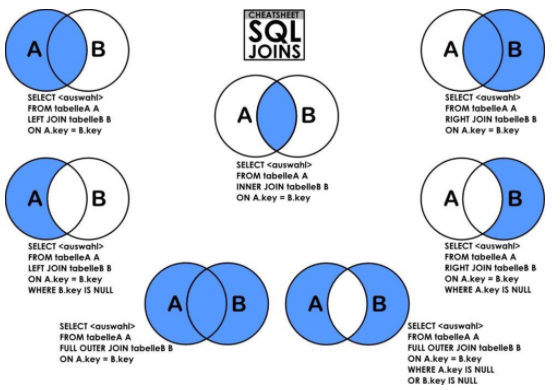
JOIN的含义就如英文单词“join”一样,连接两张表,语法如下所示:
SELECT * FROM A INNER|LEFT|RIGHT JOIN B ON condition
JOIN 按照功能大致分为如下三类:
INNER JOIN(内连接,或等值连接):取得两个表中存在连接匹配关系的记录。
LEFT JOIN(左连接):取得左表(A)完全记录,即是右表(B)并无对应匹配记录。
RIGHT JOIN(右连接):与 LEFT JOIN 相反,取得右表(B)完全记录,即是左表(A)并无匹配对应记录。
注意:mysql不支持Full join,不过可以通过UNION 关键字来合并 LEFT JOIN 与 RIGHT JOIN来模拟FULL join
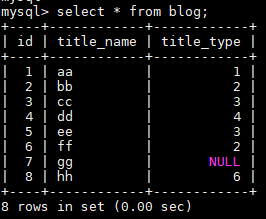
0.准备数据
|
表
|
表数据
|
命令
|
|---|---|---|
| blog 记录文章名与文章类型 |
|
create table blog( id INT primary key auto_increment, title_name varchar(40), title_type int ); insert into blog values(0,'aa',1),(0,'bb',2),(0,'cc',3),(0,'dd',4),(0,'ee',3),(0,'ff',2),(0,'gg',default),(0,'hh',6); |
| blog_type 记录文章类型 |
|
create table blog_type( id INT primary key auto_increment, name varchar(40) ); insert into blog_type values(0,'C'),(0,'PYTHON'),(0,'JAVA'),(0,'HTML'),(0,'C++'); |

1.内连接:INNER JOIN
内连接INNER JOIN/JOIN是最常用的连接操作。从数学的角度讲就是求两个表的交集:
- select * from blog inner join blog_type on blog.title_type=blog_type.id;
- select * from blog join blog_type on blog.title_type=blog_type.id;
- select * from blog,blog_type where blog.title_type=blog_type.id;
输出结果:

2.左连接:LEFT JOIN
左连接LEFT JOIN的含义就是求两个表的交集外加左表剩下的数据,左连接从左表(A)产生一套完整的记录,与匹配的记录(右表(B)) .如果没有匹配,右侧将包含null。
- select * from blog left join blog_type on blog.title_type=blog_type.id;
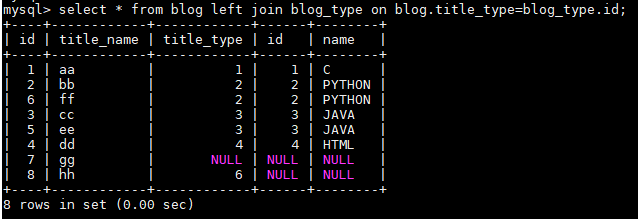
- select * from blog left join blog_type on blog.title_type=blog_type.id where blog_type.id is null;

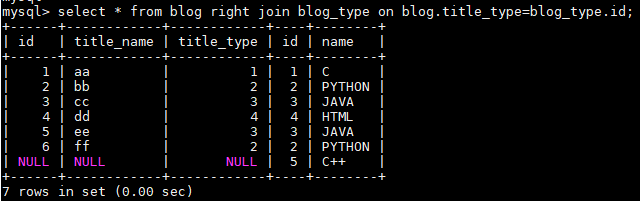
3.右连接:RIGHT JOIN
同理右连接RIGHT JOIN就是求两个表的交集外加右表剩下的数据。
select * from blog right join blog_type on blog.title_type=blog_type.id;
4.USING子句
MySQL中连接SQL语句中,ON子句的语法格式为:table1.column_name = table2.column_name。当模式设计对联接表的列采用了相同的命名样式时,就可以使用 USING 语法来简化 ON 语法,格式为:USING(column_name)。 所以,USING的功能相当于ON,区别在于USING指定一个属性名用于连接两个表,而ON指定一个条件。另外,SELECT *时,USING会去除USING指定的列,而ON不会。实例如下。
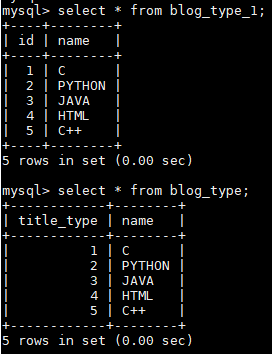
create table blog_type_1 as select * from blog_type;
alter table blog_type drop id;
alter table blog_type add title_type int not null primary key auto_increment first;
|
mysql
|
结果
|
|---|---|
|
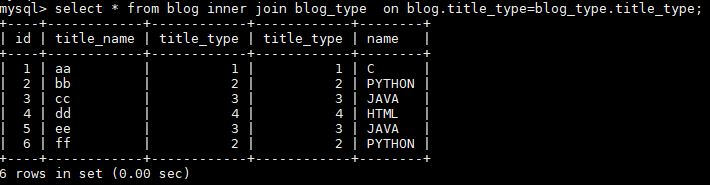
select * from blog inner join blog_type on blog.title_type=blog_type.title_type; |
|
|
select * from blog join blog_type using(title_type); USING会去除USING指定的列 |
|

join中改善性能的一些注意点:来自https://www.cnblogs.com/fudashi/p/7506877.html
- 小表驱动大表能够减少内循环的次数从而提高连接效率。
- 在被驱动表建立索引能够提高连接效率
- 优先选择驱动表的属性进行排序能够提高连接效率
扩展知识点:
0.表别名的使用:
对单表做简单的别名查询通常是无意义的。一般是对一个表要当作多个表来操作,或者是对多个表进行操作时,才设置表别名。
1.group by的用法
2.子查询
嵌套在其它查询中的查询称之为子查询或内部查询,包含子查询的查询称之为主查询或外部查询
1)不相关子查询
内部查询的执行独立于外部查询,内部查询仅执行一次,执行完毕后将结果作为外部查询的条件使用
一般在子查询中,程序先运行在嵌套在最内层的语句,再运行外层。因此在写子查询语句时,可以先测试下内层的子查询语句是否输出了想要的内容,再一层层往外测试,增加子查询正确率。否则多层的嵌套使语句可读性很低。
举栗:想要从数据库中获取文章类型是Python的文章列表
|
A
|
B
|
|---|---|
|
select title_name from blog where title_type= (select id from blog_type_1 where name='PYTHON');
|
select title_name from blog A join blog_type_1 B on A.title_type=B.id where B.name='PYTHON';
|
分步执行:
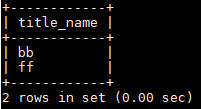
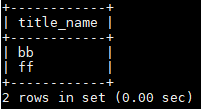
获取id: select id from blog_type_1 where name='PYTHON';---->id=2
获取文章列表:select title_name from blog where title_type=2;-→title name=(bb,ff)
联合查询:
子查询的方式:select title_name from blog where title_type=(select id from blog_type_1 where name='PYTHON');
联表查询的方式:select title_name from blog A join blog_type_1 B on A.title_type=B.id where B.name='PYTHON';
2)相关子查询
内部查询的执行依赖于外部查询的数据,外部查询每执行一次,内部查询也会执行一次。每一次都是外部查询先执行,取出外部查询表中的一个元组,将当前元组中的数据传递给内部查询,然后执行内部查询。
根据内部查询执行的结果,判断当前元组是否满足外部查询中的where条件,若满足则当前元组是符合要求的记录,否则不符合要求。然后,外部查询继续取出下一个元组数据,执行上述的操作,直到全部元组均被处理完毕。
举栗:从历史最好记录的表中获取各个指标最新时间的值
表数据:
蓝色框框中的fr指标数据是重复的,预期想要获取各个指标最新时间的指标值
|
相关子查询
|
联表查询
|
|---|---|
| select * from test_best_history_for_storm_largescale t where date =(select max(date) from test_best_history_for_storm_largescale where fr=t.fr and area="largescale_fuji") and area="largescale_fuji"; | select * from test_best_history_for_storm_largescale A join (select max(date) date,fr from test_best_history_for_storm_largescale where area='largescale_fuji' group by fr)B on A.date=B.date and A.fr=B.fr and A.area='largescale_fuji'; |
|
|