C++虚函数与多态实例
都说virtual关键字是用来实现多态和动态绑定,但是咋一听感觉挺抽象的,下面结合个实例来看看。
父类:
#include <iostream>
using namespace std;
class Dad
{
public:
Dad(){}
void sayName()
{
cout<<"I am Dad."<<endl;
}
};
子类:
#include "Dad.cpp"
class Son :public Dad
{
public:
Son(){}
void sayName()
{
cout<<"I am Son"<<endl;
}
};
void print(Dad *obj)
{
obj->sayName();
}
int main()
{
Dad *obj1 = new Son();
obj1->sayName();
Son *obj2 = new Son();
cout<<"*******"<<endl;
print(obj2);
return 0;
}
运行结果:
I am Dad.
*******
I am Dad.
--------------------------------
Process exited after 0.05475 seconds with return value 0
请按任意键继续. . .
会发现:我们本身new出来的是Son,但是因为在调用sayName方法前都对该new出来的对象进行了转型:从Son转型为Dad,经过了这样的转型之后,如果没有sayName不是虚函数的话,那么编译器只认识Dad类的sayName函数,Son的sayName函数不可见;这里是静态绑定(编译时绑定)/静态连编,编译器根据对象引用的类型(这里是Dad)将sayName的调用绑定到Dad的sayName函数。
所以要是想再print函数中调用Son的sayName函数,要么重载(overload)print函数,添加
void print(Son *obj){}
版本,那这里就有两个版本,是不是很麻烦。
所以第二种方法就是使用虚函数(virtual)激活多态属性。如下,将Dad类的sayName函数声明为虚函数:
#include <iostream>
using namespace std;
class Dad
{
public:
Dad(){}
virtual void sayName()
{
cout<<"I am Dad."<<endl;
}
};
其他代码不用修改,再次运行工程,输出结果为:
I am Son
*******
I am Son
--------------------------------
Process exited after 0.05818 seconds with return value 0
请按任意键继续. . .
可以发现,这里成功调用了Son的sayName函数。刚才说到,若不使用虚函数的话,编译器会在编译时就将函数调用和某个类的成员函数绑定,而它是根据引用类型/指针的类型来确定如何绑定的。若使用虚函数,那么对于sayName这个函数的调用,程序将根据引用或指针指向的对象的类型来选择方法,并且编译器会跳过它的绑定,让程序运行时才去绑定函数调用的实际函数空间,这就是动态绑定(动态联编)或者说运行时绑定,编译时不会进行绑定,而当程序运行的时候,调用到sayName函数时,系统会根据实际的内存空间(运行时才new出来的堆空间)的类型(也就是说实际new出来的是哪个类)寻找函数所在的位置(这里找到的是Son的sayName版本),而不仅仅是对象引用的类型,因为对象引用的类型可以随便进行强制类型转换,但是new出来的空间却是代码写定了就唯一确定的。
所以C++经常在基类中将派生类会重新定义的方法声明为虚方法。另外,基类也常常声明虚析构函数,这样做是为了确保释放派生对象时,按正确的顺序调用析构函数。后面会有一篇介绍虚析构函数。
既然动态联编有这样的好处,那么C++为什么不默认使用动态联编呢?
《C++ primer plus》一书如下解释:原因有两个——效率和概念模型。首先概率方面,为使程序能够在运行阶段进行决策,必须采取一些方法来跟踪基类指针或引用指向的对象类型,这就增加了额外的开销(即虚函数表的开销)。例如,如果类不会用作基类,则不需要动态联编。同样,如果派生类不重新定义基类的任何方法,也不需要使用动态联编。在这些情况下,使用静态联编更合理,效率也更高。由于静态联编的效率更高,因此被设置为C++的默认选择。C++之父说:C++的指导原则之一是,不要为不使用的特性付出代价(内存或者处理时间)。仅当程序设计确实需要虚函数时,才使用它们。
所以回到C++ or Java之争的那句老话,C++提供给程序员所有的可能性,包括高效的实现和低效但编程简便的实现,将选择权交给程序员,而Java则认为鱼与熊掌不可兼得的话我选择对于程序员编程更方便的一种,也就是从Java的语言设计上,就限定了很多东西,程序员按照这个规范来编程的话会达到更多的便利,虽然很多情况下会导致程序运行效率不如它老爸C++。
虚函数的工作原理
摘自《C++ primer plus中文版》:
通常,编译器处理虚函数的方法是:给每个对象添加一个隐藏成员。隐藏成员中保存了一个指向函数地址数组的指针。这种数组成为虚函数表(virtual function table, vtbl)。虚函数表中存储了为类对象进行声明的虚函数的地址。例如,基类对象包含一个指针,该指针指向基类中所有虚函数的地址表。派生类对象将包含一个指向独立地址表的指针。如果派生类提供了虚函数的新定义,该虚函数表将保存新函数的地址;如果派生类没有重新定义虚函数,该vtbl将保存函数原始版本的地址。如果派生类定义了新的虚函数,则该函数的地址也将被添加到vtbl中。注意,无论类中包含的虚函数是1个还是10个,都只需要在对象中添加1个地址成员,只是表的大小不同而已。
调用虚函数时,程序将查看存储在对象中的vtbl地址,然后转向相应的函数地址表。如果使用类声明中定义的第一个虚函数,则程序将使用数组中的第一个函数地址,并执行具有该地址的函数。如果使用类声明中的第三个虚函数,程序将使用地址为数组中第三个元素的函数。
简而言之,使用虚函数时,在内存和执行速度方面有一定的成本,包括:
1. 每个对象都将增大,增大量为存储地址的空间。
2. 对每个类,编译器都创建一个虚函数地址表(数组)。
3.每个函数调用都需要执行一步额外的操作,即到表中查找地址。
虽然非虚函数的效率比虚函数稍高,但不具备动态联编功能。
对于虚方法,还要注意以下事项(笔面试可能会碰到):
1. 构造函数:构造函数不能是虚函数,派生类不继承基类的构造函数,所以将类构造函数声明为虚拟的没有什么意义。
2. 析构函数:析构函数应当是虚函数,除非类不用做基类。 通常应给基类提供一个虚拟析构函数,即便它并不需要析构函数。
3. 友元:友元不能是虚函数,因为友元不是类成员,而只有成员才能使虚函数。
另外,在C++中还有虚继承和虚拟基类这种东西,网上例如百度百科就有浅显易懂的解释,这里只用一张图解释就足以说明很多东西:
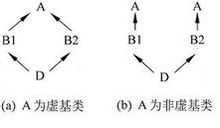
第一张图就是所谓的“菱形继承”。