OopMapBlock是一个简单的内嵌在Klass里面的数据结构,用来描述oop中包含的引用类型属性,即该oop所引用的其他oop在oop中的内存分布,然后就可以根据当前oop的地址找到所有引用的其他oop了,其定义如下:
源代码位置:oops/instanceKlass.hpp
// ValueObjs embedded in klass. Describes where oops are located in instances of
// this klass.
class OopMapBlock VALUE_OBJ_CLASS_SPEC {
public:
// Byte offset of the first oop mapped by this block.
int offset() const { return _offset; }
void set_offset(int offset) { _offset = offset; }
// Number of oops in this block.
uint count() const { return _count; }
void set_count(uint count) { _count = count; }
// sizeof(OopMapBlock) in HeapWords.
static const int size_in_words() {
return align_size_up(int(sizeof(OopMapBlock)), HeapWordSize) >>
LogHeapWordSize;
}
private:
int _offset;
uint _count;
};
OopMapBlock结构可以描述某个对象中引用区域的起始偏移和引用个数。offset描述第一个所引用的oop相对于当前oop地址的偏移量,count表示包含的oop的个数,注意这里的包含并不是指这些oop位于OopMapBlock里面,而是有count个连续存放的oop。为啥会有多个OopMapBlock了?因为每个OopMapBlock只能描述当前子类中包含的引用类型属性,父类的引用类型属性由单独的OopMapBlock描述。
之前介绍过,可以利用-XX:+PrintFieldLayout来查看布局情况。该选项只在调试版本中有效。至于布局模式,可以使用-XX:+FieldsAllocationStyle=mode来指定,默认是1。之前介绍过布局模式有3种,如下:
- allocation_style=0,字段排列顺序为oops、longs/doubles、ints、shorts/chars、bytes,最后是填充字段,以满足对齐要求;
- allocation_style=1,字段排列顺序为longs/doubles、ints、shorts/chars、bytes、oops,最后是填充字段,以满足对齐要求;
- allocation_style=2,JVM在布局时会尽量使父类oops和子类oops挨在一起。
当allocation_style的值为2时,父子oop的布局会连续在一起,这样至少有2个好处:
- 减少OopMapBlock的数量。由于GC收集时要扫描存活的对象,所以必须知道对象中引用的内存位置。原始类型不需要扫描。
- 连续的对象区域使得缓存行的使用效率更高。试想如果父对象和子对象的对象引用区域不连续,而中间插入了原始类型字段的话,那么在做GC对象扫描时,很可能需要跨缓存行读取才能完成扫描。
下面我们用HSDB来实际探查下相关的内存布局:
package jvmTest;
import java.lang.management.ManagementFactory;
import java.lang.management.RuntimeMXBean;
class Base{
private int a=1;
private String s="abc";
private Integer a2=12;
private int a3=22;
}
class A extends Base {
private int b=3;
private String s2="def";
private int b2=33;
private Base a=new Base();
}
class B extends A{
private String s3="ghk";
private Integer c=4;
private int c2=44;
}
public class jvmTest {
public static void main(String[] args) {
Base a=new Base();
A a2=new A();
B b=new B();
while (true){
try {
System.out.println(getProcessID());
Thread.sleep(600*1000);
} catch (Exception e) {
}
}
}
public static final int getProcessID() {
RuntimeMXBean runtimeMXBean = ManagementFactory.getRuntimeMXBean();
System.out.println(runtimeMXBean.getName());
return Integer.valueOf(runtimeMXBean.getName().split("@")[0]).intValue();
}
}
运行main方法后,用HSDB查看main线程的线程栈,从中找出变量a,a2,b对应的oop的地址,如下:

分别查看0x00000000d69d98a0,0x00000000d69db5f8,0x00000000d69dd070对应的oop,如下:

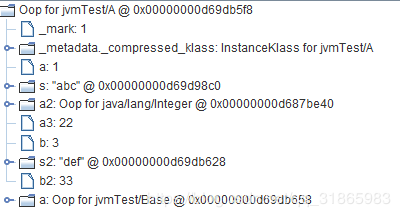

上从面的截图可知,子类会完整的保留父类的属性,从而方便调用父类方法时能够正确的使用父类的属性。上述对oop的属性打印是按照类声明属性的顺序来的,内存中是这样保存的么?可以通过查看属性的偏移量来判断。
在Class Browser中搜索jvmTest,可以查找到我们三个自定义类对应的Klass,如下图:
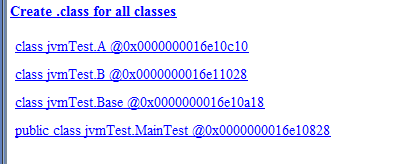
分别点击这三个类查看属性的偏移量,如下:



根据上述偏移量,我们可以得出jvmTest.B对象的内存布局,如下:

int本身占4个字节,引用类型属性本质上就是一个指针,这里因为默认开启了指针压缩,所以也是4字节。
我们再看下表示OopMapBlock在Klass中的字宽数的属性_nonstatic_oop_map_size在三个类中的取值,如下:
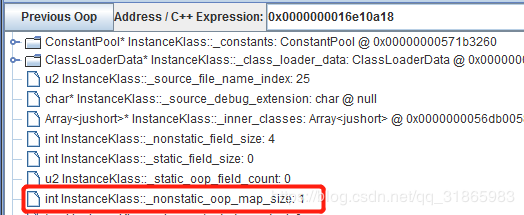
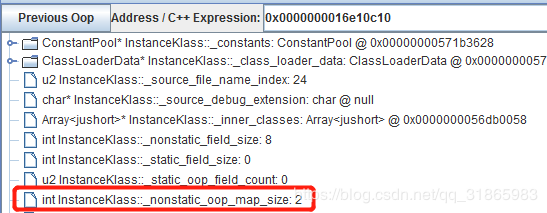
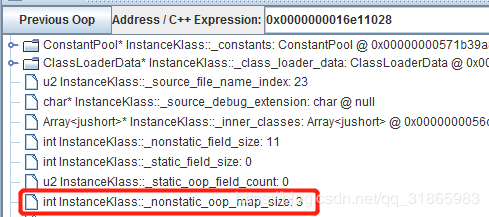
OopMapBlock本身就只有两个int属性,所以一个OopMapBlock实例只有8字节,即一个字宽,jvmTest.B的_nonstatic_oop_map_size属性值为3,即由3个OopMapBlock,下面通过CHSDB的mem命令来看看这3个OopMapBlock对应的内存数据。
首先执行inspect对象得到该Klass本身的大小,即sizeof的大小,如下:

vtable,itable,OopMapBlock这三个都是内嵌在Klass里面的,所谓的内嵌实际是指这块内存是紧挨着Klass自身的属性对应的内存的下面,从上一节的分析可知,OopMapBlock在itable的后面,itable在vtable的后面,而vtable是紧挨着Klass的,从上述inspect命令的输出,也可知道itable和vtable的内存大小,单位是字宽,如下:

因此OopMapBlock的起始地址就是Klass的地址加上Klass本身的大小440字节即55字宽,再加上vtable的5字宽,itable的2字宽,总共加62字宽,OopMapBlock本身占用3个字宽,因此用mem查看这65字宽的数据,如下:

最后的3个字宽如下:

每个字宽对应一个OopMapBlock,前面4字节就是count属性,这里都是2,后面4字节就是offset,分别是20,36,48,与jvmTest.B的内存结构是完全一致的。
在parseClassFile()方法中开辟了OopMapBlock的内存空间后,还会调用方法来填充OopMapBlock,这都是在解析Class文件的阶段完成的,如下:
// Compute transitive closure(闭包) of interfaces this class implements // Do final class setup fill_oop_maps(this_klass, info.nonstatic_oop_map_count, info.nonstatic_oop_offsets, info.nonstatic_oop_counts);
调用的fill_oop_maps()方法的实现如下:
void ClassFileParser::fill_oop_maps(instanceKlassHandle k,
unsigned int nonstatic_oop_map_count,
int* nonstatic_oop_offsets,
unsigned int* nonstatic_oop_counts) {
OopMapBlock* this_oop_map = k->start_of_nonstatic_oop_maps();
const InstanceKlass* const super = k->superklass();
const unsigned int super_count = super ? super->nonstatic_oop_map_count() : 0;
if (super_count > 0) {
// Copy maps from superklass
OopMapBlock* super_oop_map = super->start_of_nonstatic_oop_maps();
for (unsigned int i = 0; i < super_count; ++i) {
*this_oop_map++ = *super_oop_map++;
}
}
if (nonstatic_oop_map_count > 0) {
if (super_count + nonstatic_oop_map_count > k->nonstatic_oop_map_count()) {
// The counts differ because there is no gap between superklass's last oop
// field and the first local oop field. Extend the last oop map copied
// from the superklass instead of creating new one.
nonstatic_oop_map_count--;
nonstatic_oop_offsets++;
this_oop_map--;
this_oop_map->set_count(this_oop_map->count() + *nonstatic_oop_counts++);
this_oop_map++;
}
// Add new map blocks, fill them
while (nonstatic_oop_map_count-- > 0) {
this_oop_map->set_offset(*nonstatic_oop_offsets++);
this_oop_map->set_count(*nonstatic_oop_counts++);
this_oop_map++;
}
assert(k->start_of_nonstatic_oop_maps() + k->nonstatic_oop_map_count() == this_oop_map, "sanity");
}
}
相关文章的链接如下:
1、在Ubuntu 16.04上编译OpenJDK8的源代码
13、类加载器
14、类的双亲委派机制
15、核心类的预装载
16、Java主类的装载
17、触发类的装载
18、类文件介绍
19、文件流
20、解析Class文件
21、常量池解析(1)
22、常量池解析(2)
23、字段解析(1)
24、字段解析之伪共享(2)
25、字段解析(3)
作者持续维护的个人博客classloading.com。
关注公众号,有HotSpot源码剖析系列文章!

参考文章:
(1)https://zhuanlan.zhihu.com/p/28226360
(2)https://blog.csdn.net/lqp276/article/details/52190503
(3)https://blog.csdn.net/qq_31865983/article/details/104284546#t3
(6)https://blog.csdn.net/qq_31865983/article/details/104284546#4%E3%80%81OopMapBlock