- 进一步介绍了Transformation操作
- 进一步介绍了Action操作
- 知识点解析:Function
- 知识点解析:Suffle
Transformation
map
map(func) converts each element of the source RDD into a single element of the result RDD by applying a function.
也就是说,rdd里的一个元素,经过转换,生成另一个元素。这里的转换,可以是一个String对应到一个Int,如下:
val textFile = sc.textFile("data.txt")
val lineLengths = textFile.map(s => s.length)
也可以是一个Int,对应到一个(Int, Int),如下:
val a = sc.parallelize(1 to 9, 3)
def mapDoubleFunc(a : Int) : (Int,Int) = {
(a,a*2)
}
val mapResult = a.map(mapDoubleFunc)
最终,输出是N维的,和输入相同。
flatMap
flatMap(func) works on a single element (as map) and produces multiple elements of the result (as mapPartitions).
flatMap transforms an RDD of length N into another RDD of length M.
举例如下,输入是一串String,输出可能是任意个String。维度可能发生变化。
// count each word's apperance in a file
val textFile = sc.textFile("data.txt")
val wordCounts = textFile.flatMap(line => line.split(" ")).groupByKey(identity).count()
wordCounts.collect()
https://data-flair.training/blogs/apache-spark-map-vs-flatmap/
mapPartitions
mapPartitions(func) converts each partition of the source RDD into multiple elements of the result (possibly none).
val a = sc.parallelize(1 to 9, 3)
def doubleFunc(iter: Iterator[Int]) : Iterator[(Int,Int)] = {
var res = List[(Int,Int)]()
while (iter.hasNext)
{
val cur = iter.next;
res .::= (cur,cur*2)
}
res.iterator
}
val result = a.mapPartitions(doubleFunc)
result.collect()
mapPartitions v.s. map
- 操作对象不同:前者针对partition操作,后者针对每一个element操作,一般来说前者的loop更少,更加快。
- 传参不同:前者需要一个func,且type为
Iterator<T> => Iterator<U>,后者只需要一个func。 - 结果维度不同:前者的维度可能是任意值,后者的维度一定是N,和传入参数维度相同。
https://blog.csdn.net/lsshlsw/article/details/48627737
aggretation
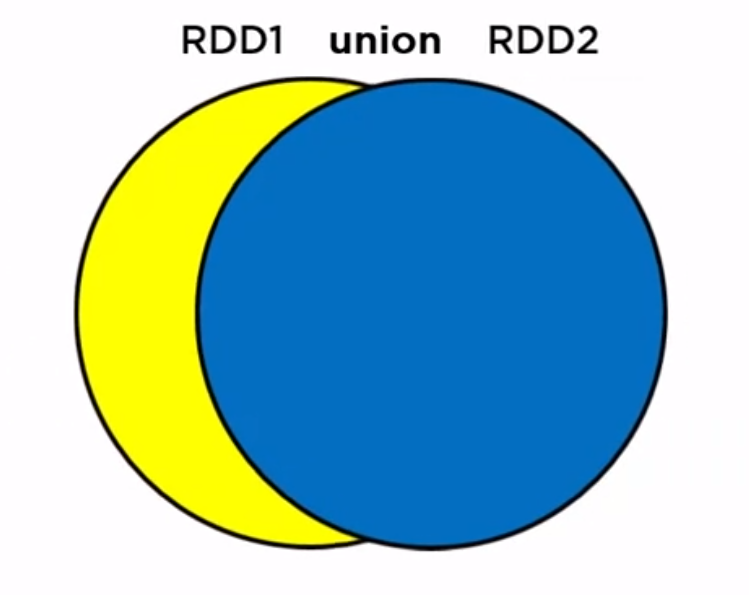
rdd1.union(rdd2):combine two rdds
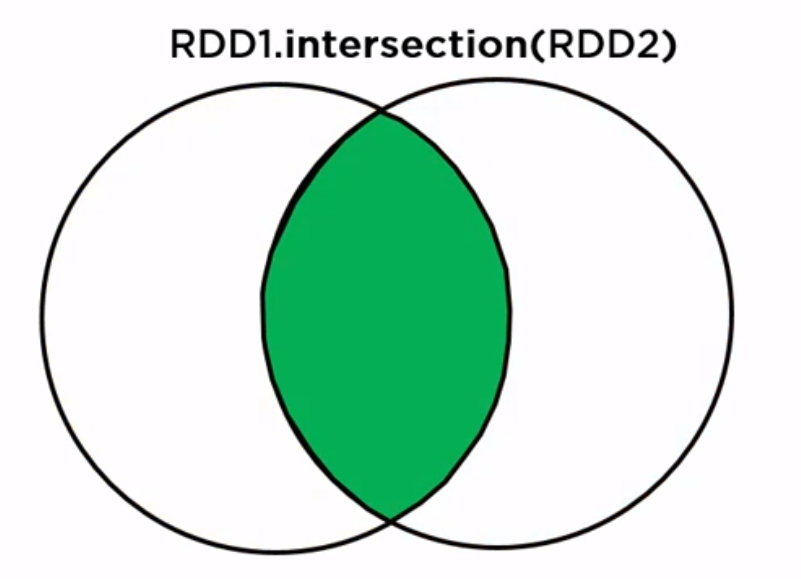
rdd1.intersection(rdd2): pick the intersection only, like inner join
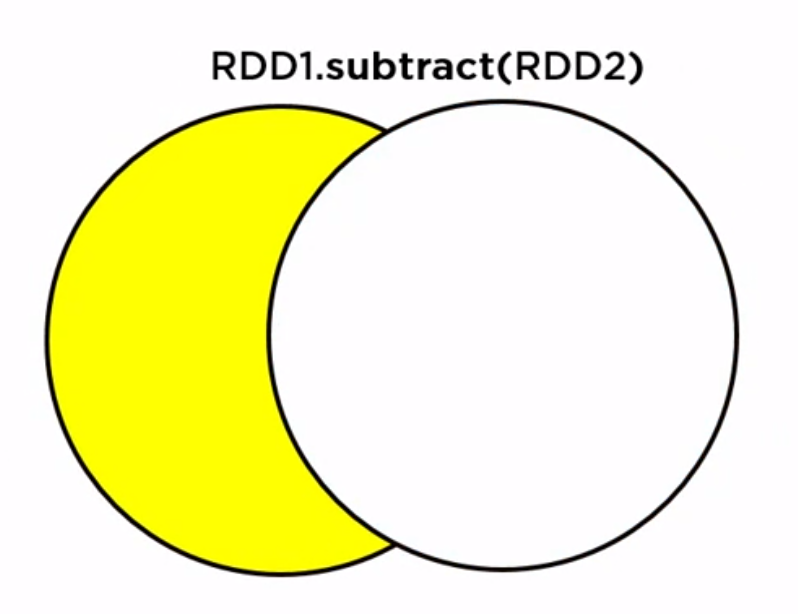
rdd1.subtract(rdd2): pick the one left has only, like left join
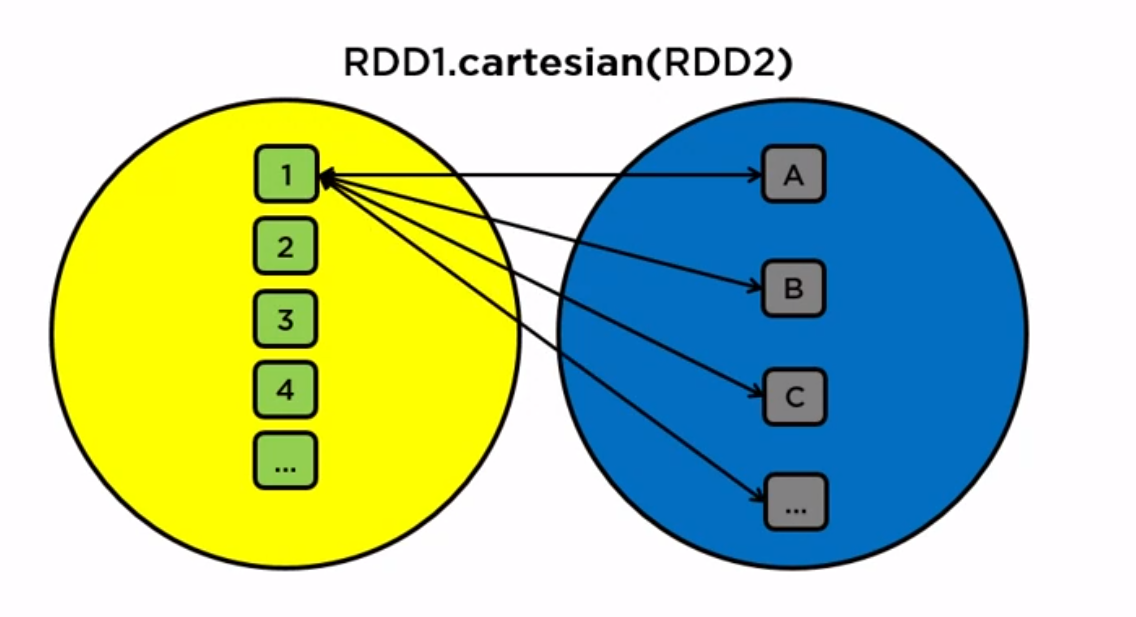
rdd1.cartesian(rdd2): double for loop
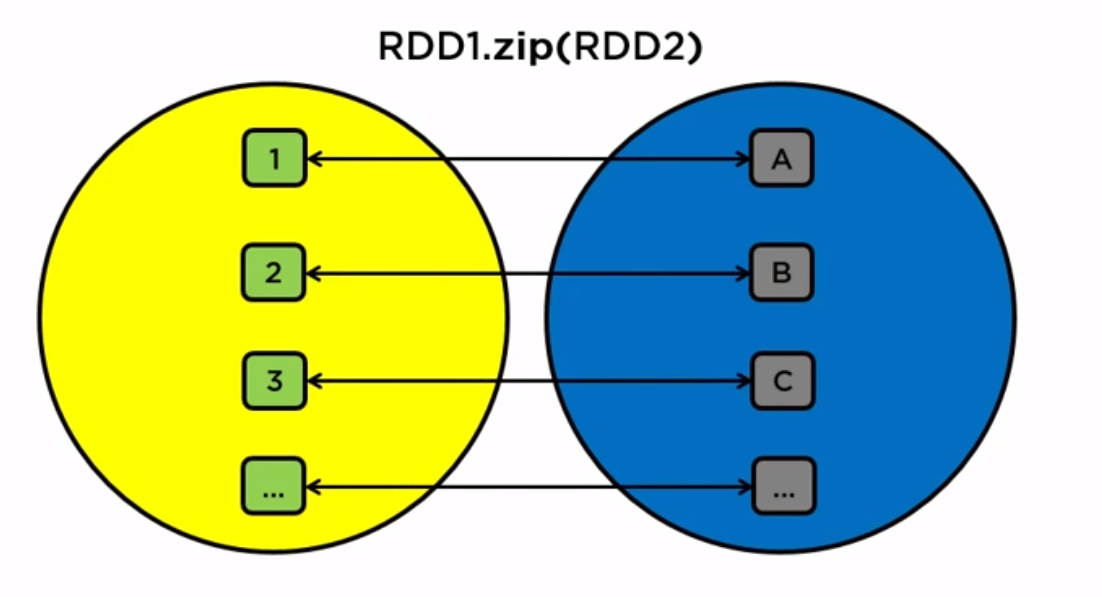
rdd1.zip(rdd2): two rdds must have same structure, match one with another
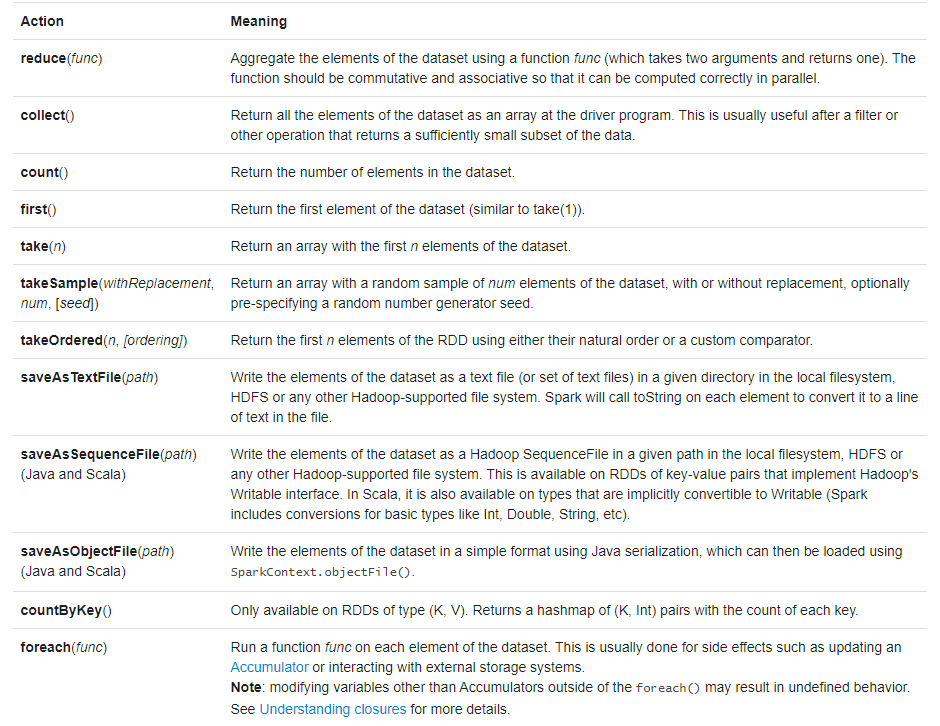
Action
Understanding Function / Lambda
Spark编程中,使用了大量的函数式编程,一般可以分为两种:
- Anonymous function syntax (Lambda)
val lineLengths = lines.map(s => s.length)
这样写,有两个好处:
- 一是简洁。
- 另外,保证都是局部变量而不是全局变量,可以减小开销,且并行计算不容易出错。
- Static methods in a global singleton object
object MyFunctions {
def func1(s: String): String = { ... }
}
myRdd.map(MyFunctions.func1)
Understanding Suffle
Spark的运算是先transformation/map,然后action/reduce。对于action,一般来说是把每个node的结果拿来做aggregation,比如求和。但是有的操作,需要遍历所有node的所有key,比如排序。这时,就需要用到suffle。
It must read from all partitions to find all the values for all keys, and then bring together values across partitions to compute the final result for each key - this is called the shuffle.
会trigger suffle的操作有以下几类:
- repartition:
repartitionandcoalesce - ByKey operations (except for counting):
groupByKeyandreduceByKey - join operations:
cogroupandjoin
需要注意的是,shuffle是非常expensive的操作,因为它involves disk I/O, data serialization, and network I/O。