Mysql数据库基础学习笔记
1.mysql查看当前登录的账户名以及数据库

一、单表查询
1、创建数据库yuzly,创建表fruits
创建表
CREATE TABLE fruits(f_id CHAR(10) NOT NULL,s_id INT NOT NULL,f_name char(255) NOT NULL,f_price DECIMAL(8,2) NOT NULL,PRIMARY KEY(f_id));
插入内容
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('a1',101,'apple',5.2); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('b1',101,'blackberry',10.2); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('bs1',102,'orange',11.2); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('bs2',105,'melon',8.2); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('t1',102,'banana',10.3); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('t2',102,'grape', 5.3); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('o2',103,'coconut',9.2); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('c0',101,'cherry',3.2); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('a2',103,'apricot',2.2); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('l2',104,'lemon',6.4); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('b2',104,'berry',7.6); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('m1',106,'mango',15.6); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('m2',105,'xbabay',2.6); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('t4',107,'xbababa',3.6); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('m3',105,'xxtt',11.6); INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('b5',107,'xxxx',3.6 );
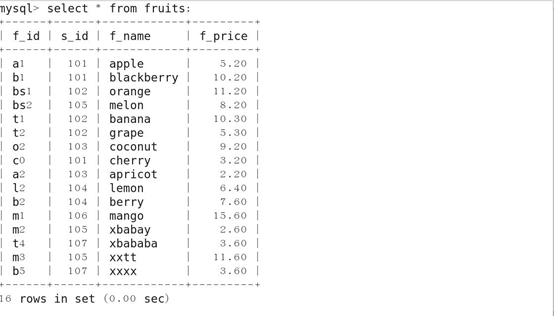
2、查询所有字段
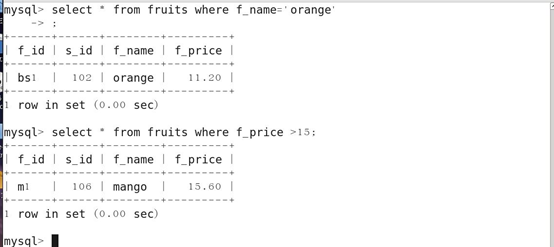
3.查询指定字段
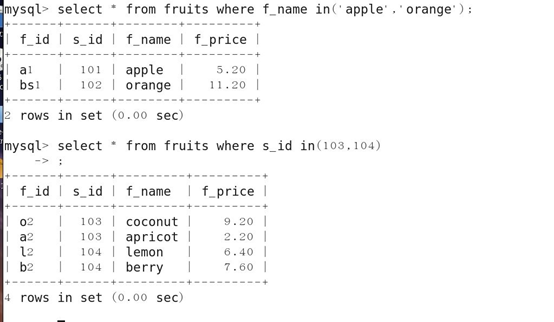
4.带IN关键字的查询
IN关键字:IN(xx,yy,...) 满足条件范围内的一个值即为匹配项
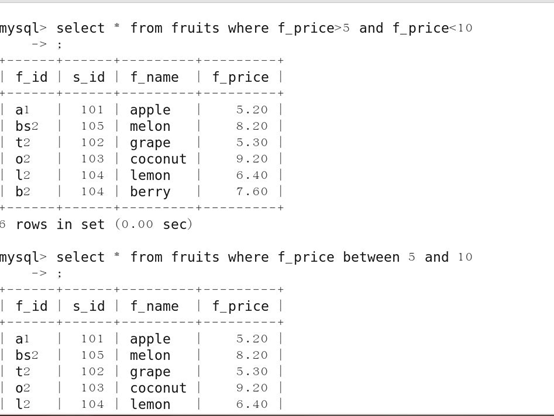
5.带BETWEEN AND的范围查询
BETWEEN ... AND ... : 在...到...范围内的值即为匹配项
6.带LIKE的字符匹配查询
LIKE: 相当于模糊查询,和LIKE一起使用的通配符有 "%"、"_"
"%":作用是能匹配任意长度的字符。
"_":只能匹配任意一个字符

7.查询空值
空值不是指为空字符串""或者0,一般表示数据未知或者在以后在添加数据,也就是在添加数据时,其字段上默认为NULL,也就是说,如果该字段上不插入任何值,就为NULL。此时就可以查询出来。
SELECT * FROM 表名 WHERE 字段名 IS NULL; //查询字段名是NULL的记录
SELECT * FROM 表名 WHERE 字段名 IS NOT NULL; //查询字段名不是NULL的记录
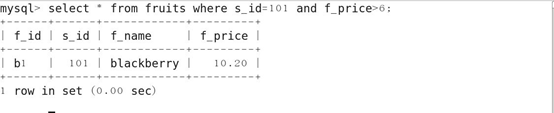
8.带AND的多条件查询
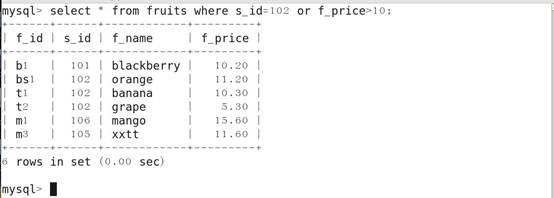
9.带OR的多条件查询
10.关键字DISTINCT(查询结果不重复)

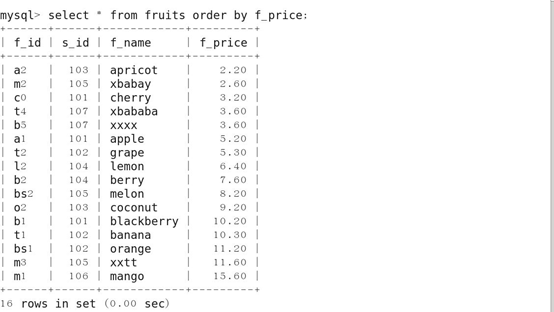
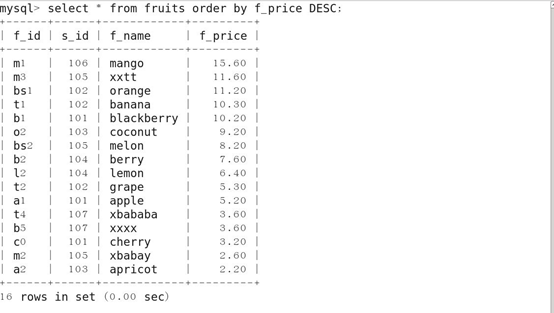
11.对查询结果排序(ORDER BY)
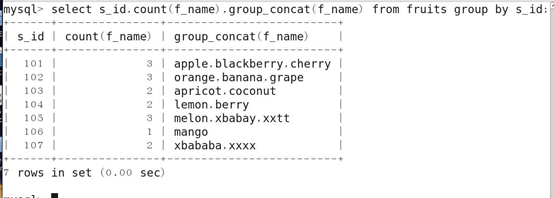
12.分组查询(GROUP BY)
分组之后还可以进行条件过滤,将不想要的分组丢弃,使用关键字 HAVING
HAVING和WHERE都是进行条件过滤的,区别就在于 WHERE 是在分组之前进行过滤,而HAVING是在分组之后进行条件过滤。

13.使用LIMIT限制查询结果的数量
14.COUNT()函数
COUNT(*):计算表中的总的行数,不管某列有数值或者为空值,因为*就是代表查询表中所有的数据行。
COUNT(字段名):计算该字段名下总的行数,计算时会忽略空值的行,也就是NULL值的行。

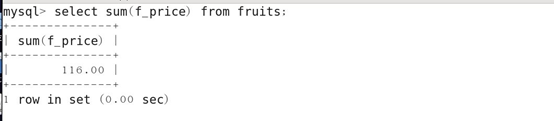
15.SUM()函数
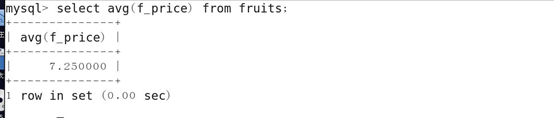
16.AVG()函数
17.MAX()函数、MIN()函数

二、多表查询
1.创建表,插入数据
CREATE TABLE suppliers(s_id INT NOT NULL,s_name CHAR(50) NOT NULL,s_city CHAR(50) NULL,s_zip CHAR(10) NULL,s_call CHAR(50) NOT NULL,PRIMARY KEY(s_id)); INSERT INTO suppliers VALUES(101,'Supplies A','Tianjin','400000','18075'); INSERT INTO suppliers VALUES(102,'Supplies B','Chongqing','400000','44333'); INSERT INTO suppliers VALUES(103,'Supplies C','Shanghai','400000','90046'); INSERT INTO suppliers VALUES(104,'Supplies D','Zhongshan','400000','11111'); INSERT INTO suppliers VALUES(105,'Supplies E','Taiyuang','400000','22222'); INSERT INTO suppliers VALUES(106,'Supplies F','Beijing','400000','45678'); INSERT INTO suppliers VALUES(107,'Supplies G','Zhengzhou','400000','33332'); INSERT INTO suppliers VALUES(108,'Supplies H','Xiaan','400000','44442'); INSERT INTO suppliers VALUES(109,'Supplies I','Fuzhou','400000','55552'); INSERT INTO suppliers VALUES(110,'Supplies J','Xiamen','400000','66662');
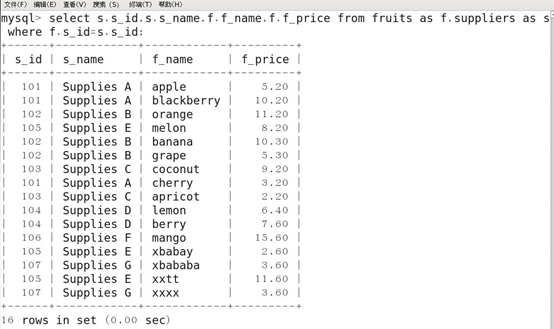
2.普通双表连接查询
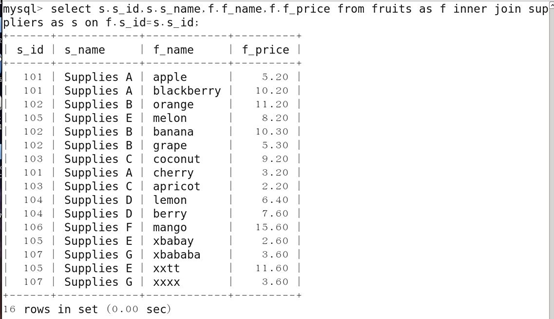
3.内连接查询
格式:表名 INNER JOIN 表名 ON 连接条件
4.外连接查询
内连接是将符合查询条件(符合连接条件)的行返回,也就是相关联的行就返回。
外连接除了返回相关联的行之外,将没有关联的行也会显示出来。
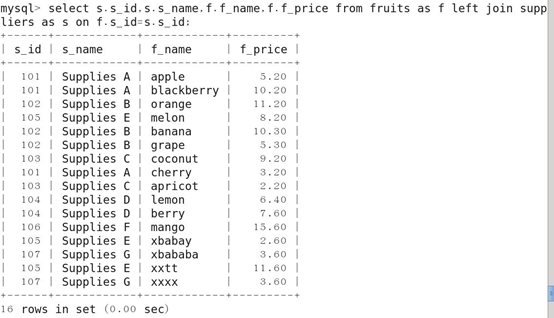
左外连接查询
格式: 表名 LEFT JOIN 表名 ON 条件;
返回包括左表中的所有记录和右表中连接字段相等的记录,通俗点讲,就是除了显示相关联的行,还会将左表中的所有记录行都显示出来。
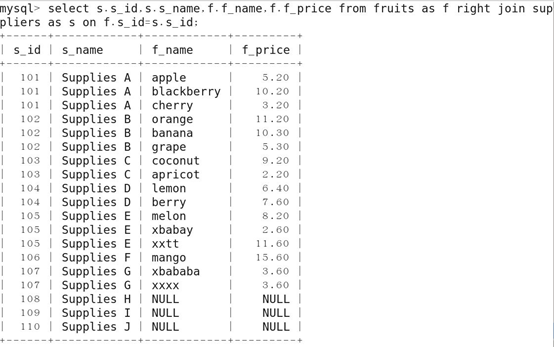
5.右外连接查询
格式: 表名 RIGHT JOIN 表名 ON 条件
返回包括右表中的所有记录和右表中连接字段相等的记录
6.复合条件连接查询

7.使用INNER JOIN语法进行内连接查询,并对查询结果进行排序
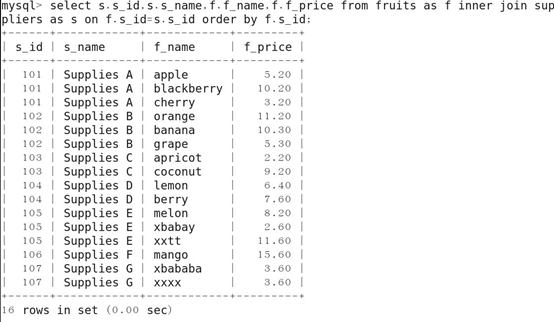
8.子查询
将查询一张表得到的结果来充当另一个查询的条件,这样嵌套的查询就称为子查询。
搭建环境

9.带ANY、SOME关键字的子查询
ANY关键字接在一个比较操作符的后面,表示若与子查询返回的任何值比较为TRUE,则返回TRUE,通俗点讲,只要满足任意一个条件,就返回TRUE。

10.带ALL关键字的子查询
使用ALL时表示需要同时满足所有条件。

11.带EXISTS关键字的子查询
EXISTS关键字后面的参数是任意一个子查询,如果子查询有返回记录行,则为TRUE,外层查询语句将会进行查询,如果子查询没有返回任何记录行,则为FALSE,外层查询语句将不会进行查询。

12.带IN关键字的子查询

13.合并结果查询
利用UNION关键字,可以将查询出的结果合并到一张结果集中,也就是通过UNION关键字将多条SELECT语句连接起来,注意,合并结果集,只是增加了表中的记录,并不是将表中的字段增加,仅仅是将记录行合并到一起。其显示的字段应该是相同的,不然不能合并。
UNION:执行的时候会删除重复的记录,所有返回的行度是唯一的,
UNION ALL:不删除重复航也不对结果进行自动排序。
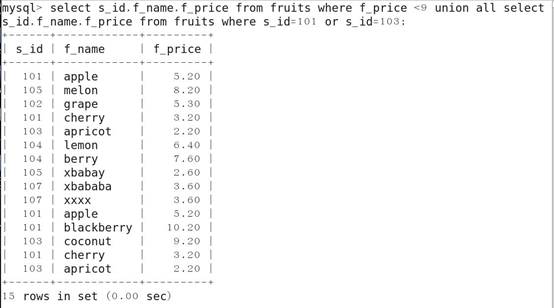
14.使用UNION,而不用UNION ALL的话,重复的记录就会被删除掉。
