指数分布族 The exponential family
因为广义线性模型是围绕指数分布族的。大多数常用分布都属于指数分布族,服从指数分布族的条件是概率分布可以写成如下形式:![]()
η 被称作自然参数(natural parameter),或正则参数canonical parameter),它是指数分布族唯一的参数
T(y) 被称作充分统计量(sufficient statistic),很多情况下T(y)=y log
a(η) 是log partition function
e-a(η)是一个规范化常数,使得分布p(y; η)的和为1p(;η)
对于给定的一组a,b,T,都会得到对应的指数分布族。改变参数η的取值会影响该指数族的分布。
伯努利分布(Bernoulli)的指数分布族
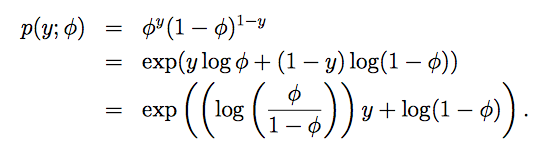
对应关系如下:
η 为标量,转置等于其本身。所以:

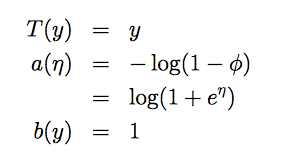
高斯分布(Gaussian)的指数分布族
正态分布(正态分布有两个参数均值 μ 与 标准差σ,在做线性回归的时候,我们关心的是均值而标准差不影模型的学习与参数θ的选择,因此这里将 σ2设为1便于计算)
对应关系如下:
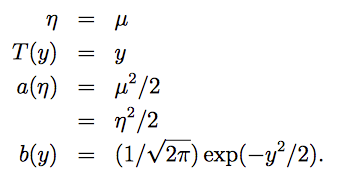
以下分布也都属于指数分布族
Bernoulli 伯努利分布
Gaussian 高斯分布
multinomial 多项式分布
Poisson 泊松分布(用于计数的建模)
gamma 伽马分布、exponential 指数分布(用于对正数建模,多用于间隔问题)
β 分布,Dirichlet 分布(用于对小数建模)
广义线性模型 Greneralized Linear Models
广义线性模型(Generalized Linear Models)
使用GLMs来解决问题,基于三个设计假设:
- y|x;θ∼ExponentialFamily(η)。输出变量基于输入变量的条件概率分布服从指数分布族
- 我们的目标是通过给定x,来预测T(y)期望 E[T(y) | x]。对于给定的输入变量x,学习的目标是预测T(y)的期望值,T(y)经常就是y,因此假设函数需要满足h(x)=E[y|x](这个假设对logistic回归和线性回归都成立)。
- 自然函数 η 与输入特征 x 的关系是线性的,η=θTx(如果自然参数是向量,ηi=θTix)。
如果问题满足这三个假设,就可以构造广义线性模型来解决。这三个假设指明了如何从输入变量映射到输出变量与概率模型。
最小二乘法
在线性回归的最小平方问题中,目标变量 y 是连续的(在GLM的术语中也称作响应变量(response variable))。
已知给定x,y符合高斯分布,均值为 μ。线性回归目标是预测T(y)的期望(期望也就是均值 μ)。又根据上面对于高斯分布指数分布族的推导,得知T(y)=y,μ=η。由GLMs 假设3得知 η=θTx。
最终得到线性回归的假设函数:
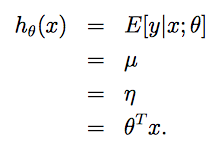
Logistic回归
在二元分类问题中,给定x,y服从伯努利分布,均值为ϕ。由伯努利分布的 η ,可以反推出 φ

利用广义线性模型的假设 3 可知同时有 η=θTx。因此可以得到logistic回归的假设函数(sigmoid 函数):
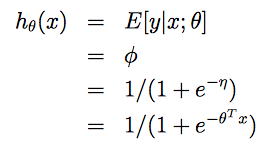
canonical response function:g(η) = E[T(y); η],给定正则参数 η,求分布的平均值
canonical link function:g−1,canonical response function的逆,即根据g(η)求 η
Softmax回归
Logistic 分布解决二分类问题,Softmax用于解决多分类问题。

符合多项式分布multinomial distribution。下面开始构建模型,使其符合指数分布。
如果有k个类型 y∈{1,2,...,k}。则可以用 φ1,φ2,...,φk−1,φk 一共k个变量来表示 y属于每种类型的概率。但因为所有概率之和为1,如果已知前 k-1个概率的值,第k个概率就确定了,这将违反独立同分布的原则。
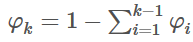
因此我们用前面 k-1 个变量替代第 k 个变量,设置参数:φ1,φ2,...,φk−1。其中 φi = p(y=i; φ)。
【注:虽然有时公式中会将φk写出来,但要记住它是一个由k-1项决定的表达式,不是一个变量】
引入T(y):

注意,这里就和前面的 T(y) = y 不同,这里的 T(y)是一个向量,所以用 T(y)i 表示 T(y) 的第i个元素。
引出 indicator function 指示函数 的定义:1{True}=1,1{False}=0。
由于当 i = 1 时T(1)为1。当 i = 2 时T(2)为1。即当且仅当 y = i 时,T(y)i =1。则T(y)与y的关系可以写成:

有 T(y)i 的期望等于 “y属于类型 i 的概率φi ”:
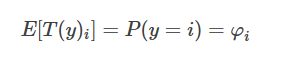
现在可以证明多项式分布符合指数分布族:
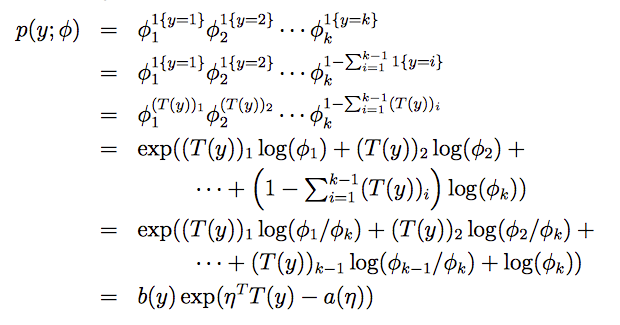
公式 第4步到第5步,是将最后一个乘积的和分配到前面每一项上做减法。且 log(a)-log(b) = log(a/b)。
对应关系:
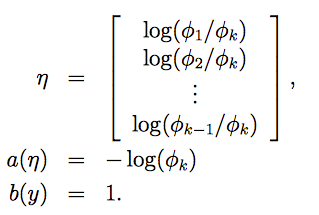
link函数为:

为了方便,定义 ηk = log(φk/φk) = 0。通过上式反推 φ:

公式两边 k 项求和:
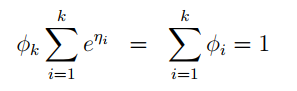
移项:
![]()
再带回 (7)式中替换φk。移项得到从η到φ’s的映射,称作softmax函数:
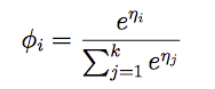
根据假设3,并令
![]()
得到softmax regression,它是logistic regression的推广。根据机器学习三要素,其
(1)模型

其中 eμk = e0 = 1。
最终,假设函数为:

(2)策略
依然可以使用极大似然估计的方法来学习θ,似然函数 L(θ) 为m个概率 p(y(i)|x(i); θ) 的乘积。其对数 l(θ)为: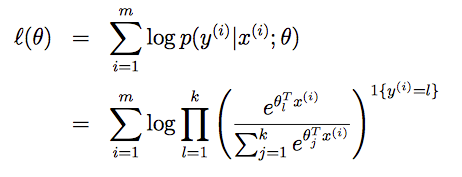
(3)算法
可以通过梯度上升或牛顿方法来求出合适的参数 θ。这里μ是上面的指示函数1{}
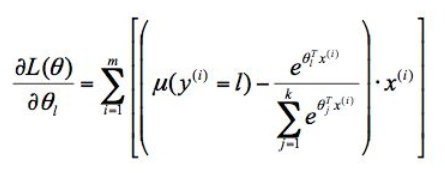
梯度上升:

Softmax 回归和 Logistic回归的关系


