day14
1. Set集合
1.1 Set集合概述
- Set集合是Collection的一个子接口,来自于java.util包
- Set集合特点:
1) 元素存取不能保证有序
2) 没有索引
3) 不存储重复元素
- Set接口, 不能实例化对象, 需要实现类, HashSet哈希表实现结构
代码
|
package com.ujiuye.set; import java.util.HashSet; import java.util.Set; public class Demo01_Set存储元素不重复 { public static void main(String[] args) { Set<Integer> set = new HashSet<>(); set.add(99); set.add(1); set.add(15); set.add(99); set.add(1);
System.out.println(set);// [1, 99, 15]
Set<String> set1 = new HashSet<>(); set1.add("99"); set1.add("1"); set1.add("15"); set1.add("99"); set1.add("1");
System.out.println(set1);// [99, 1, 15] } } |
1.2 Set集合的遍历
Set集合中没有特殊方法, 直接使用从Collection父接口重写的方法
- toArray() : 将Set集合中的元素赋值到一个Object[] 数组中,通过遍历数组相当于遍历Set集合中的元素(集合转数组)
- toArray(T[] a) : 将集合中的元素赋值到参数T[] 数组中, T类型与集合中的泛型保持一致,
1) 数组a长度大于等于集合中元素的个数, 集合元素直接复制到T[]中, 返回T[]数组
2) 数组a长度集合中元素的个数, 方法中会自动创建出一个新的T[]数组, 用于复制数据, 将新的T[]进行返回(集合转数组)
- 迭代器
- 增强for(forEach) : 也是循环
1) 增强for循环语法结构:
for(集合或数组中的元素数据类型 变量名 : 需要遍历的集合或者数组){
}
2) 变量名 : 用于表示集合或者数组中的每一个元素
3) 增强for底层实现原理是迭代器, 因此增强for遍历集合同时,如果对于集合进行修改, 也是会报出: 并发修改异常
注意 : 迭代器和增强for都无法获取到元素的索引,因此无法通过索引操作数组或者集合中的元素
遍历1
|
package com.ujiuye.set; import java.util.HashSet; import java.util.Set; public class Demo02_Set遍历1 { public static void main(String[] args) { Set<Integer> set = new HashSet<>(); set.add(99); set.add(1); set.add(15); set.add(99); set.add(1);
// 1. 将set集合转换成Object[]数组 Object[] objArr = set.toArray(); // 2. 遍历objArr数组 for(int index = 0; index < objArr.length; index++) { Object obj= objArr[index]; Integer i = (Integer)obj; System.out.println(i); } } } |
遍历2
|
package com.ujiuye.set; import java.util.HashSet; import java.util.Set; public class Demo03_Set遍历2 { public static void main(String[] args) { Set<Integer> set = new HashSet<>(); set.add(99); set.add(1); set.add(15);
// 1. 创建出一个与set集合泛型一致的数组 Integer[] arr = new Integer[set.size()]; set.toArray(arr);
for(int index = 0; index < arr.length; index++) { Integer i = arr[index]; System.out.println(i); } } } |
遍历3
|
package com.ujiuye.set; import java.util.HashSet; import java.util.Iterator; import java.util.Set; public class Demo04_Set遍历3 { public static void main(String[] args) { Set<Integer> set = new HashSet<>(); set.add(99); set.add(1); set.add(15);
Iterator<Integer> it = set.iterator(); while(it.hasNext()) { Integer i = it.next(); System.out.println(i); } } } |
遍历4
|
package com.ujiuye.set; import java.util.HashSet; import java.util.Set; public class Demo05_Set遍历4 { public static void main(String[] args) { Set<String> set = new HashSet<>(); set.add("hello"); set.add("a"); set.add("world");
// 1. 使用增强for进行set集合遍历 for(String s : set) { System.out.println(s); } } } |
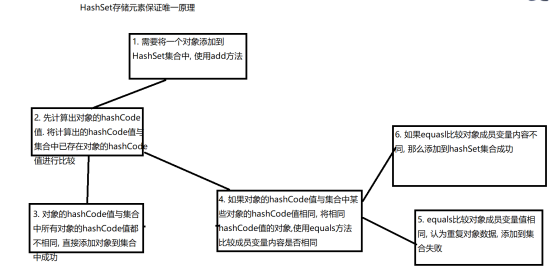
1.3 HashSet保证元素唯一原理
1.3.1 HashSet存储JDK提供类型
HashSet集合存储数据类型是JDK提供类型, 举例 : Integer, String,Double... , 存储在HashSet集合中, 能保证元素唯一
1.3.2 HashSet存储自定义数据类型
- 自定义出一个Person类型, 设计出两个属性 name , age
- 将几个Person对象存储在HashSet集合中, 要求: 如果Person对象中的name和age的值都相同, 认为Person类型数据重复, HashSet不存储重复元素;
- 存储相同成员变量值的Person对象后, HashSet没有去重复
- 查看HashSet中add方法功能 : 发现先调用了对象hashCode方法, 后调用equals方法
- 推断, 现在需要将Person中hashCode和equals方法重写, 使用alt + shift + s, 自动生成hashCode和equals方法重写, 重写后Person类型可以根据成员变量的值进行唯一存储机制
代码
|
package com.ujiuye.set; public class Person { private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public Person(String name, int age) { super(); this.name = name; this.age = age; } public Person() { super(); } @Override public String toString() { return "Person [name=" + name + ", age=" + age + "]"; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + age; result = prime * result + ((name == null) ? 0 : name.hashCode()); return result; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Person other = (Person) obj; if (age != other.age) return false; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; return true; } } |
|
package com.ujiuye.set; import java.util.HashSet; public class Demo06_HashSet存储定义类型唯一 { public static void main(String[] args) { HashSet<Person> set = new HashSet<>(); set.add(new Person("张三",20)); set.add(new Person("李四",20)); set.add(new Person("张三",20)); set.add(new Person("王五",19));
System.out.println(set); } } |
1.3.3 hashCode和equals方法
1. hashCode() : 方法从父类Object继承而来, 功能就是获取到对象的哈希码值. 哈希码值是一个整数结果(int)
a : Object源代码中 : 将一个对象的内存地址转换成一个整数,不同的对象返回不同的整数; 根据对象返回整数值结果是否一致,判断是否是同一个对象
b : 子类重写hashCode方法, 重写的过程,是将一个对象的成员变量对应的hashCode值计算出来
总结 : hashCode方法就是通过算法比较是否是同一个对象
- equals() : 方法从父类Object继承而来
a : Object源代码中, 比较的是两个对象内存地址是否相等
b : 重写equals方法, 比较就是两个对象成员变量值是否相等
1.3.4 HashSet保证唯一的原理
1.4 LinkedHashSet
1. LinkedHashSet类型是HashSet的子类, 底层维护了双向链表, 元素存入集合的顺序与从集合中取出元素的顺序能保证一致
2. 除了元素存储有序之外, 其他的所有功能包括保证元素唯一的原理,都与HashSet一致
代码
|
package com.ujiuye.set; import java.util.HashSet; import java.util.LinkedHashSet; public class Demo08_LinkedHashSet { public static void main(String[] args) { HashSet<String> set = new HashSet<>(); set.add("He"); set.add("she"); set.add("it"); set.add("she"); set.add("a");
System.out.println(set);// [she, it, He]
LinkedHashSet<String> set1 = new LinkedHashSet<>(); set1.add("He"); set1.add("she"); set1.add("it"); set1.add("she"); set1.add("a");
System.out.println(set1);// [He, she, it] } } |
3. Map集合
3.1 Map集合的概述
- Map集合 : 双列集合顶层父接口
- map : 英文中表示地图, 地图上的每一个点, 对应现实生活中一个地理位置, 因此地图是表示一对一的关系, Map集合也是数据一对一的关系
- Map<K,V> :
K---Key, 键
V---Value , 值
因此将Map中的成对的元素称为键值对映射关系, 一对一的关系, 一个Key的值对应一个Value的值
- Map集合存储K和V特点:
1) Map集合没有索引, 元素存储无序
2) Map集合中, Key的值是唯一的(不重复), Value值可以重复; 通常使用唯一的Key值操作对应的value值
3.2 Map集合中的常用方法
Map集合是接口, 接口不能实例化对象, 需要实现类, HashMap, 底层哈希表实现结构
- put(K key, V value) :
a : 如果存入的key的值在Map集合中不存在, 于是put方法表示向Map集合中添加数据
b : 如果存入的key的值在Map集合中已经存在, put方法相当于修改功能, 存入的value值替换掉原有的value值
- remove(Object key) : 通过Map中唯一key的值, 将key和对应的value,键值对映射关系从Map集合中删除, 方法返回被删除的value值
- clear() : 表示将Map集合中的所有键值对映射关系删除掉, Map集合本身还存在
- isEmpty() : 如果Map集合中没有任何键值对元素, isEmpty结果为true, 否则false
- size() : 获取Map集合中的键值对数量, 求集合长度
- containsKey(Object key) : 验证Map集合的键值中,是否包含参数key, 包含返回true, 不包含返回false
- containsValue(Object value) : 验证Map集合的Value值中,是否包含参数value, 包含返回true, 不包含返回false
- get(Object key) : 通过参数给出的key值,获取到对应的value值, 返回值类型为对应V
代码
|
package com.ujiuye.map; import java.util.HashMap; import java.util.Map; public class Demo01_Map常用方法 { public static void main(String[] args) { // Map集合没有索引, Key值不重复, 存储元素无序 Map<Integer, String> map = new HashMap<>(); // 1. put map.put(2, "b"); map.put(1, "a"); map.put(11, "c");
// 2. put map.put(11, "end"); System.out.println(map.size());// 3 // 6. containsKey System.out.println(map.containsKey(19) + "-----");// false System.out.println(map.containsKey(11));// true // 7. 补充containsValue // 8. get(Object key) String value11 = map.get(16); System.out.println(value11 + "++++++");// null
String value22 = map.get(2); System.out.println(value22 + "?????");// b
System.out.println(map);//{1=a, 2=b, 11=end}
// 3. remove String value = map.remove(1); System.out.println(value);// a
System.out.println(map);// {2=b, 11=end}
// 4. clear map.clear(); System.out.println(map);// {}
// 5. isEmpty boolean boo = map.isEmpty(); System.out.println(boo);// true
System.out.println(map.size()); //0 } } |
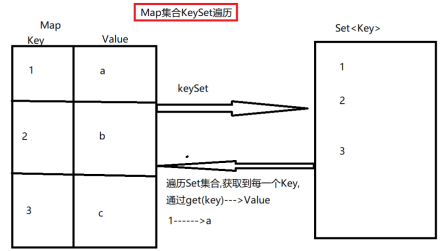
3.3 Map集合的第一种遍历方式
- Map<K,V>集合中有一个方法功能:
keySet() : 表示将Map集合中的所有的Key的值放置到一个Set<K>集合中
- 遍历Set<K>集合, 获取到每一个Key的值, 通过get(Key)获取到对应的value值
代码
|
package com.ujiuye.map; import java.util.HashMap; import java.util.Map; import java.util.Set; public class Demo02_Map第一种遍历KeySet { public static void main(String[] args) { Map<Integer, String> map = new HashMap<>(); map.put(2, "b"); map.put(1, "a"); map.put(11, "c");
// 1. 获取到map中的所有key Set<Integer> set = map.keySet(); // 2. 遍历set集合, 获取到每一个key值 for(Integer key : set) { // 3. 通过get(Key)获取到对应的value值 String value = map.get(key); System.out.println(key + "---->" + value); } } } |
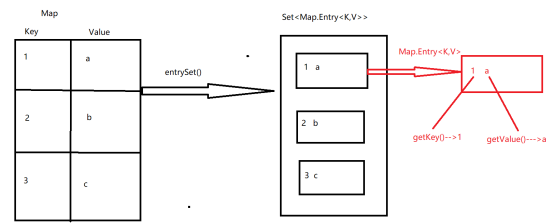
3.4 Map集合的第二种遍历方式
- Map集合中有方法功能 :
1) entrySet() : 表示将Map集合中的所有的键值对映射关系放置到一个Set集合中, 返回值类型Set<Map.Entry<K,V>>
2) Entry : 是Map接口中的内部接口, Entry<K,V> 类型表示Map集合中的每一对元素
3) 因为Entry存在于Map类型内部, 调用方式 Map.Entry<K,V>
4) 遍历Set<Map.Entry<K,V>>, 获取出每一对元素关系, Map.Entry<K,V>
5) Entry类型中, 有方法功能
a : getKey() : 获取到键值对关系中的key值
b : getValue() : 获取到键值对关系中的value值
代码
|
package com.ujiuye.map; import java.util.HashMap; import java.util.Map; import java.util.Set; public class Demo03_Map第二种遍历EntrySet { public static void main(String[] args) { Map<Integer, String> map = new HashMap<>(); map.put(2, "b"); map.put(1, "a"); map.put(11, "c");
// 1. 获取到map集合中所有键值对关系 Set<Map.Entry<Integer, String>> set = map.entrySet(); // 2. 遍历set集合, 获取到每一对映射关系 for(Map.Entry<Integer, String> entry : set) { // 3. 将每一对元素中的key和value分别获取到 Integer key= entry.getKey(); String value = entry.getValue(); System.out.println(key + "---" + value); } } } |
3.5 HashMap
- HashMap是Map接口的实现类, 底层基于哈希表实现
- HashMap集合中的key的值不重复, 联想到HashSet中的元素也不重复, 因为HashSet保证元素唯一的实现过程就是依靠HashMap中的key值的唯一的实现过程
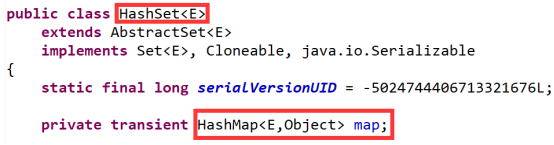

- 如果HashMap集合中, key值存储自定义类型, 通过类型中成员变量区分元素的重复与否,需要在自定义类型中重写hashCode和equals两个方法功能(alt + shift + s)
- 哈希表结构:

3.6 LinkedHashMap
- LinkedHashMap 是HashMap的子类, 与HashMap功能一致, 因为底层维护了双向链表结构,因此可以实现元素的存取和取出的顺序保持一致
代码
|
package com.ujiuye.map; import java.util.HashMap; import java.util.LinkedHashMap; import com.ujiuye.set.Person; public class Demo04_HashMap存储自定义类型 { public static void main(String[] args) { HashMap<Person, String> map = new HashMap<>(); map.put(new Person("张三",20), "新加坡"); map.put(new Person("李四",20), "北京"); map.put(new Person("张三",20), "香港"); map.put(new Person("王五",20), "东北");
System.out.println(map);
LinkedHashMap<Person, String> map1 = new LinkedHashMap<>(); map1.put(new Person("张三",20), "新加坡"); map1.put(new Person("李四",20), "北京"); map1.put(new Person("张三",20), "香港"); map1.put(new Person("王五",20), "东北");
System.out.println(map1); } } |
4.抽象类与接口的使用场景(扩展)
