1. 笨办法
pandas Dataframe 可以很容易做时序数据的 resample,按照一定的frequency 聚合数据. 但是spark 中因为没有顺序的概念就不太好做,下面是怎么在spark中做resample 的例子.
def resample(column, agg_interval=900, time_format='yyyy-MM-dd HH:mm:ss'): if type(column)==str: column = F.col(column) # Convert the timestamp to unix timestamp format. # Unix timestamp = number of seconds since 00:00:00 UTC, 1 January 1970. col_ut = F.unix_timestamp(column, format=time_format) # Divide the time into dicrete intervals, by rounding. col_ut_agg = F.floor(col_ut / agg_interval) * agg_interval # Convert to and return a human readable timestamp return F.from_unixtime(col_ut_agg) df = df.withColumn('dt_resampled', resample(df.dt, agg_interval=3600)) # 1h resample df.show()
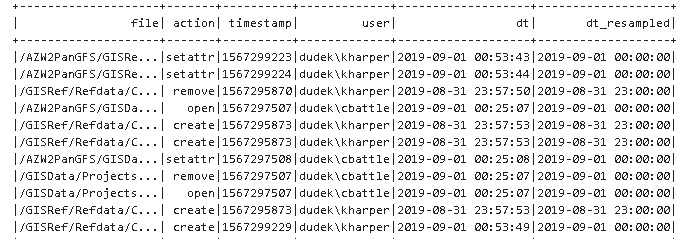
2. 新办法
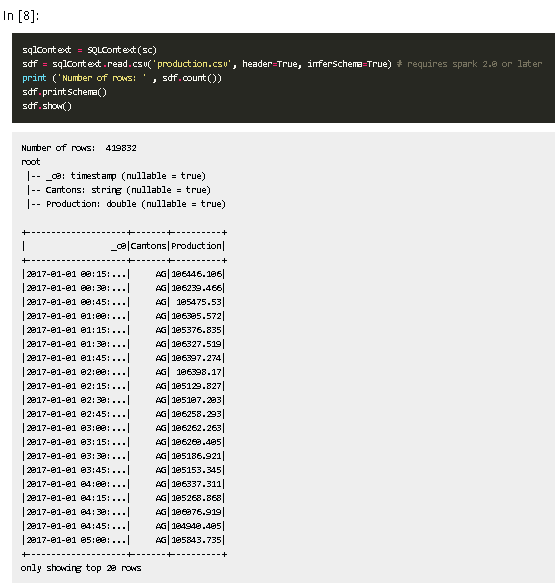
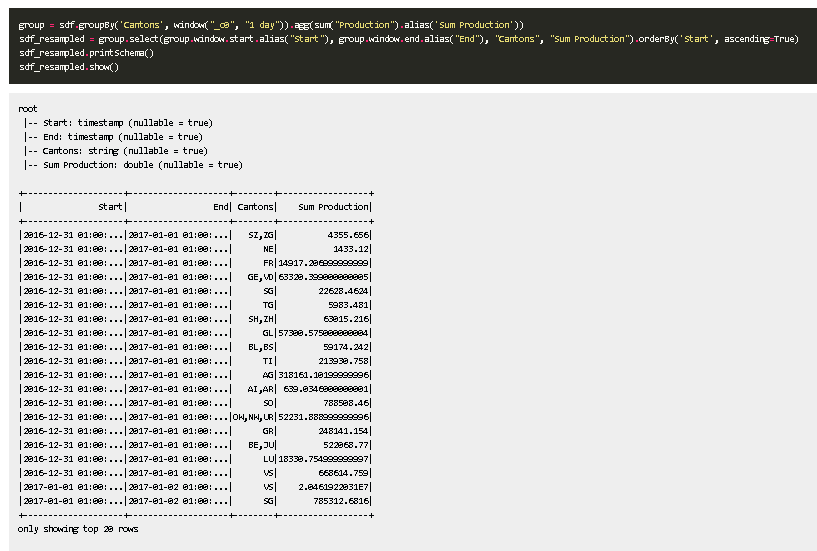
使用 groupby + window
Ref:
https://mihevc.org/2016/09/28/spark-resampling.html 笨办法但是容易理解
https://rsandstroem.github.io/sparkdataframes.html#Resampling-time-series-with-Spark 新办法