深度学习和PyTorch
1.1机器学习
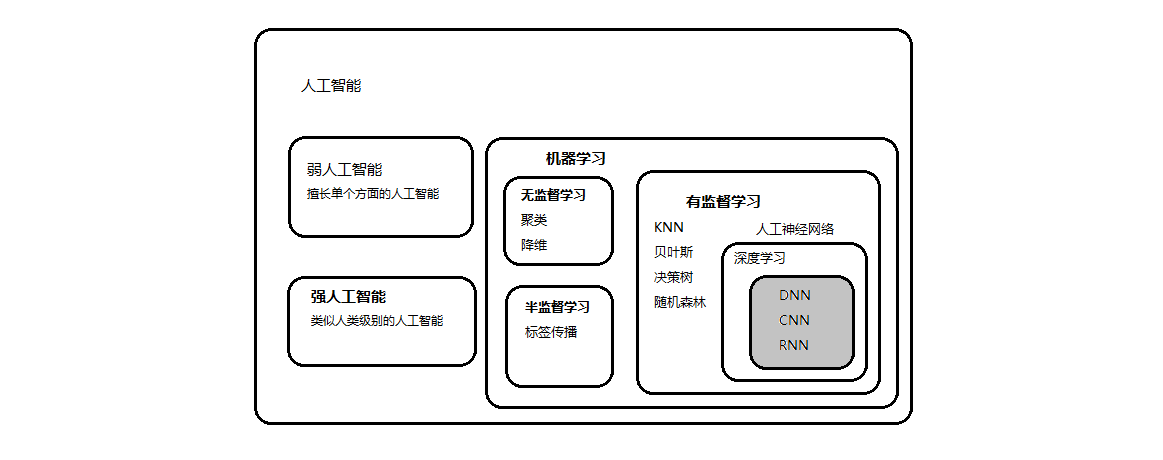
在人工智能领域,机器学习是人工智能的一个分支,也是目前人工智能领域发展最快的一个分支。简单的说,机器学习就是计算机程序如何随着经验的积累而自动的提高性能,使系统自我完善的过程。机器学习在近30多年的发展已经发展为多领域交叉的学科,设计概率论,逼近论,统计学,凸分析,计算复杂性理论等,而且其应用非常广泛,包括自然语言处理,计算机视觉,欺诈检测,人脸识别,垃圾邮件过滤,以及医学诊断等。根据机器学习的应用场景和学习方式不同,可以简单的分为三类,无监督学习,半监督学习和有监督学习。
-
无监督学习
无监督学习和其他两种监督学习的主要区别在于,无监督学习不需要提前知道数据集的类别标签,无监督学习使用的应用场景通常为聚类和降维,如使用k-均值聚类,系统聚类,密度聚类等进行数据聚类,使用主成分分析,流行降维等算法减少数据的特征数量。
-
半监督学习
半监督学习是一种介于无监督学习和有监督学习之间的一种学习算法,半监督学习就是利用极少的有标签数据和大量的无标签数据进行学习,通过学习得到的经验从而对无标签的测试数据进行预测。
-
有监督学习
有监督学习的主要特性是利用大量的有标签的训练数据来建立模型,以预测新的未知标签数据,用来指导模型建立的标签可以是类别数据、连续数据等。相应的,如果标签是可以进行分类的数据,如0-9手写数字识别,判断是否为垃圾邮件,则称这样的有监督学习为分类,如果标签是连续的数据,如身高、年龄、商品的价格等,则称为回归。
传统的机器学习算法主要有K-近邻(KNN)算法,它的思想就是根据邻居的数据类别来决定自己的类别。朴素贝叶斯是一种通过先验经验和样本信息来确定样本类别的算法。决策树是利用规则进行学习的算法。随机森林,梯度提升机则是利用集成的思想进行预测。支持向量机是借助核函数将数据映射到高维空间,寻找最大切分超平面的算法。人工神经网络是深度学习的基础,主要是卷积神经网络和循环神经网络等,大部分基于人工神经网络的深度学习算法属于有监督学习。
1.2深度学习
深度学习是机器学习的一种方法,和传统的机器学习一样,都可以根据输入的数据进行分类或者回归,但随着数据量的增加,传统的机器学习表现得不尽人意,而此时利用更深的网络挖掘数据信息的方法-----深度学习则表现出了优异的性能,迅速受到学术界和工业界的关注。尤其是在2010之后,各种的深度学习的框架的开源和发布,更进一步的促进了深度学习算法的发展
深度学习算法并非横空出世,而是有着几十年的历史积累。现在流行的深度神经网络最早可以追溯到20世纪40年代,但是由于当时计算能力有限,最早的神经网络结构非常简单,并没有得到成功的实际应用。
在20世纪60-70年代,神经生理科学家们发现,在猫的视觉皮层中有两种细胞,一种是简单细胞,它对图像中的细节信息更加敏感,如图像的边缘、角点等;另一种细胞是复杂细胞,对图像的空间具有不变性,可以处理旋转、放缩、远近等情况的图像。学者根据这一发现提出了卷积神经网络。
深度学习框架,尤其是基于人工神经网络的框架,可以追溯到1980年福岛邦彦 提出的新认知机。在1989年,Yann LeCun等人,开始将1974年提出的标准反向传播算法应用于深度神经网络,这-网络被用于手写邮政编码识别。尽管算法可以成功执行,但计算代价非常巨大,神经网络的训练时间达到了3天,而且只能根据经验设置参数,受到种种因素的限制,最终没有投入实际使用。而1995年最受欢迎的机器学习算法支持向量机被提出,逐渐成为当时的主流算法,所以基于深度卷积神经网络的算法并没有引起人们的重视。而且当时针对梯度消失的问题并没有被解决,这一现象同时在深度前馈神经网络和递归神经网络中出现,在深度学习网络的分层训练过程中,本应用于修正模型参数的误差随着层数的增加指数递减,这导致了模型训练的效率低下。
尽管深度学习算法在2000年之前就已经被应用,并受到了支持向量机算法的压制,但是其发展并没有停止。如1992年多层级网络被提出,其利用无监督学习训练深度神经网络的每一层,再使用反向传播算法进行调优。在这一模型中, 神经网络 中的每一层都代表观测变量的一种压缩表示,这一 表示也被传递到下一层网络。而 且最大值池化技术也被引人卷积神经网络中,进一步提升了卷积神经网络的性能。在卷积神经网络发展的同时,循环神经网络也得到了很大的发展,其中具有里程碑 意义的是长短期记忆( LSTM )网络。其通过在神经单元中引人输入门、遗忘门、输出门等门的概念,来选择对长期信息和短期信息的提取,提升网络的记忆能力。进人21世纪之后,随着数据量的积累和计算机性能的提升,神经网络算法和深度学习网络也得到了迅速的发展。在2006年后,出现了基于GPU的卷积神经网络,
1.3人工智能、机器学习、深度学习之间的关系
人工智能是什么:就是想电影中终结者,像阿尔法狗这类的具有一定的和人类智慧同样本质的一类智能的物体。
人工智能和机器学习的关系:机器学习是实现人工智能的方法。
机器学习和深度学习的关系:深度学习是机器学习算法中的一种算法,一种实现机器学习的技术和学习方法。
1.4深度学习的框架有哪些
随着深度学习的大发展,各种深度学习框架也在快速被高校和研究公司发布和 开源。尤其近两年,很多科技公司如Coogle、Facebook、 Microsoft等都开源了 自己的深度学习框架,供使用者进行学习研究。
目前虽然已经提出了各种各样的深度学习框架,但是它们的流行程度和易用性都不相同,在下图中给出了几种常用的深度学习框架,简单的介绍。

1.4.1 Theano
Theano是由蒙特利尔大学在2007年开发的深度学习框架,也是最古老的目前仍然有显著影响力的Python深度学习框架。
Theano是一 个Python库,使用者可以定义、优化、评价其数学表达式,尤其是多维数组( numpy.ndarray )。在处理数据巨大时,使用Theano库编程可以与C程序的计算速度相媲美,尤其是利用CPU加速后,甚至可以比基于CPU计算的C程序的速度快好几个数量级。Theano 主要是通过直接描述数学表达式,所以执行的是解析式求导,而非数值求导。Theano结合了计算机代数系统( Computer Algebra System,CAS)和优化编译器,从而在计算需要被重复评价的复杂数学表达式时,能够加快评价速度。当然其也有一些 缺点,如Theano定 义function时缺乏灵活的多态机制,scan中传递参数的机制非常难用,并且程序调试困难。
Theano是由研究机构开发的,主要服务于研究人员,具有浓厚的学术气息,所以在工程设计上还有一些缺陷。其优点主要是使用图结构下的符号计算架构,并且对RNN支持很友好,所以在自然语言处理领域应用得较多。其缺点主要是相较于其他框架更偏向于底层,从而调试困难、编译时间长,而且在计算机视觉领域,没有预训练好的模型可以使用。
2017年11月,在Theano 1.0正式版本发布之后,Theano已 经决定不再提供更新,表示Theano将退出历史舞台,但是其作为第一个Python的深度学习框架,已经很好地完成了自己的使命,对早期的深度学习研究人员提供了很大的帮助,同时影响了后来出现的深度学习框架的设计。基于Theano目前已经停止开发的现状,作为深度学习人门的初学者,不建议将其作为研究工具继续学习。
1.4.2 TensorFlow
TensorFlow是由Google发布的深度学习框架,其前身Google内部使用工具DistBelied, 经过改进后在2015年11 月宣布面向大众使用并开源。TensorFlow主要应用于机器学习和深度学习的研究,除了提供了矩阵运算和深度学习相关的函数外,还提供了众多图像处理相关的函数。由于TensorFlow非常灵活,通过众多函数的组合就能实现所需要的算法,属于一个非常基础的系统,因此应用于多个领域,受到Google在深度学习领域的巨大影响和其强力的推广,TensorFlow 一经推出,就受到了学术界和工程界的关注,并且迅速成为目前用户最多的深度学习框架,TensorFlow的基本思路是使用有向图来表示计算任务,有向图由多节点和边构成,节点代表符号变量或者操作,所有的操作都放到会话(session)中进行。TensorFlow在最新发布的2.0版本中,引人了动态图的计算方式,所以现在的TensorFlow属于动态图和静态图两种计算方式并存。TensorFlow的核心部分用C++来编写,所以计算时非常高效,并且提供了Python和C+ +接口。
TensorFlow作为目前最流行的深度学习框架,在取得如此巨大成功的同时,也 见受到了使用者的大量吐槽, 总结起来主要有以下几点:
-
(1)接口频繁变动。TensorFlow的接口处于快速的迭代之中,而且没有很好地考虑版本前后相互兼容的问题,这就导致了很多已经投入使用的旧版本代码,不敢轻易升级到更高的新版本。
-
(2)接口设计复杂不容易理解。TensorFlow提出 了图、会话、命名空间、PlaceHolder等多种抽象的概念,提高了用户理解门槛,尤其对初学者非常不友好
-
(3)文档混乱。虽然TensorFlow的文档教程很多,但是针对不同的版本管理混乱,缺乏条理,在学习时没有清晰的学习路径,让很多初学者产生学习瓶颈,无法真正在应用时得心应手。所以,尽管TensorFlow是目前最流行的深度学习框架,但对于初学者并不是昌好的选择。
1.4.3 Keras
Keras是-一个用Python编写的开源神经网络库,是基于TensoFlow、CNKT或者Thean作为后端的高层神经网络API。Keras旨在快速实现深度神经网络,专注于用户友好、模块化和可扩展性,主要作者和维护者是Google工程师弗朗索瓦.肖莱。准确地说,Keras并不能称为深度学习框架,因为它更像一个深度学习接口,建立在第三方深度学习框架之上,但是keras在使用时非常方便,非常适合初学者。 2017年,Google的TensorFlow团队决定在TensorFlow核心库中支持keras,CNTK V2.0开始,微软也向Keras添加了CNTK后端。
Keras由于其高度的封装,也带来了很多缺点,如使用时非常不灵活,同时当用户想要做些底层操作时,就会非常困难,而且高度的封装会让Keras的计算速度变得缓慢,从而在模型测试时需要花费更多的时间。
Keras虽然非常容易使用,但是很快就会遇到学习瓶颈,而且高度封装,使用户很多操作都在调用高级的API,这对深度学习算法和应用细节的学习理解非常不利,不能真正地深入学习、深度学习。虽然Keras可以作为学习深度学习的敲门砖,但是不能作为最终的生产工具。
1.4.4 MXNet
MXNet ( Apache MXNet )是一个开源的深度学习软件框架,用于训练及部署深度神经网络。MXNet具有可扩展性,允许快速模型训练,并支持灵活的编程模型和多种编程语言(包括C++、Python、 Julia、 Matlab、JavaScript、 Go、R、Scala、PerI和Wolfram语言)。MXNet库可以扩展到多GPU和多台机器,具有可移植性。在2014年,陈天奇和李沐组建了DMLC [ Distributed (Deep) Machine Learning Community],号召大家起来开发MXNeto ,但是由于其是由学生开发,所以并不注重在商业上的推广,限制了MXNet在商业上的应用。2016年11月亚马逊把MXNet选为AWS的首选深度学习框架。2017年 1月MXNet项目进入Apache基金会,成为其孵化项目。
虽然MXNet接口很多,而且有很多支持者,但是由于其快速的更新迭代,导致很多文档长时间没有更新,增加了新手掌握MXNet的难度,所以其使用者并不是很多。
1.4.5 CNTK
CNTK是一个由微软研究院开发的深度学习框架,于2016年1月在微软公司Github仓库正式开源。根据开发者的描述,CNTK的计算性能比Caffe、Theano、ThensorFlow等主流的深度学习框架都强,并且支持CPU和GPU的计算。CNTK同样将深度学习网络看作一一个计算图, 叶子节点代表网络的输人或者参数,其他节点则代表计算步骤。因为CNTK-开始只在微软内部使用开发,所以并没有Python接口,而且微软并没有对其进行大力推广,所以使用者非常少,社区并不活跃,对初学者也不友好。
1.4.6 Caffe
Caffe (Convolutional Architecture for Fast Feature Embedding,快速特征嵌入的卷积结构)是一个深度学习框架, 最初是贾扬清在加州大学伯克利分校攻读博士期间创建Caf项目,项目现在托管到GitHub,拥有众多贡献者。Cffe使用C++ 编写,并提供有Python接口。Caffe 支持多种类型的深度学习架构,在面向图像分类和图像分割领域时表现突出,还支持CN、RNN、LSTM和全连接神经网络设计。Caffe同时支持基于GPU和CPU的加速计算。
Calf5借其易用性和出色的性能,获得了很多用户的支持,曾经占据深度学习的半璧江山,但是随着深度学习新时代的到来,已经逐渐没落。在贾扬浩从加州大学伯克利分校毕业后加人Google再到加人Facebook人工智能研究院(FAIR)后,又开发了Caffe2,Caffe2比Caffe的性能更加突出,而且速度更快,但是并没有特别流行,而且相关文档也不是非常完善。
1.4.7 PyTorch
PyTorch是基于动态图计算的深度学习框架,也是非常年轻的深度学习框架之一,在2017年1月18日,PyTorch由Facebook发布,并且在2018年12月份发布了稳定的1.0版本。
PyTorch是基于动态图计算的深度学习框架,而大多数的深度学习框架都是基于静态图计算的。静态图计算均是先先定义然后再运行,一次定义好计算网络图后,可以多次运行,这样就带来了些问题, 因为静态图一旦定义后,是不能修改的可.造成了静态图过于庞大,占据很高的内存。而动态计算图则没有这样的问题,因为动态图计算是在运行的过程中被定义的,从而可以多次计算多次运行,方便使用者对网络的修改,PyTorch是典型的基于静态图计算的深度学习框架,在PyTorch取得巨大成功后,TenorFlow在新的更新中也开始拥抱基于动态图计算图的使用。PyTorch会在每一次运行程序过程中,创建一幅新的计算图。
PyTorch的前身Torch可追溯到2002年,其诞生于纽约大学。刚开始,PyTorch使用了一种不是很大众的语言Lua作为接口。虽然Lua简洁高效,但由于其过于小众,所以使用者不是很多。考虑到Python在计算科学领域的领先地位,以及其生态完整性和接口易用性,几乎任何框架都提供了Python接口。终于在2017年,Torch的幕后团队推出了PyTorch,对Tensor之上的所有模块进行了重构,并新增了最先进的自动求导系统,提供新的Python接口,成为当下最流行的动态图框架。在2018年 12月发布的PyTorch 1.0 版本中,Facebook将Caffe2 并入PyTorch,更让PyTorch如虎添冀。
PyTorch主要有两大特点: 一是可以无缝地使用NumPy,而且可以使用CPU加速;二是使用动态图计算使网络更加灵活,并且可以构建基于自动微分系统的深度神经网络。下表中列出了几种流行的深度学习框架的比较。
| 名称 | 使用语言 | 硬件支持 | 开发者 | 发布时间 |
|---|---|---|---|---|
| Theano | Python | CPU、GPU | 蒙特利尔大学 | 2010 |
| TensorFlow | C++、Python | CPU、GPU | 2015 | |
| Keras | Python | CPU、GPU | 弗朗索瓦.肖莱 | 2015 |
| MXNet | C++、Python | CPU、GPU | 李沐等 | 2014 |
| CNTK | C++、Python | CPU、GPU | 微软 | 2016 |
| Caffe | C++、Python | CPU、GPU | 贾扬清 | 2013 |
| PyTorch | Lua、Python | CPU、GPU | 2017 |
1.5关于深度学习常用到的一些python的库
-
(1)文件管理的相关库
OS:该模块为操作系统接口模块,提供了一些方便使用操作系统的相关功能函数,在读写文件时比较方便。
-
(2)时间和日期
time:该模块为时间的访问和转换模块,提供了各种时间相关的函数,方便时间的获取和操作。
-
(3)文本处理
re: 该库为正则表达式操作库,提供了与Perl语言类似的正则表达式匹配操作,方便对字符串的操作。
string:该库为常用的字符串操作库,提供了对字符串操作的方便用法。
requests: requests是 一个Python HTTP库,方便对网页链接进行一系列操作,包含很多字符串处理的操作。
-
(4)科学计算和数据分析类
NumPy: NumPy是使用Python进行科学计算的基础库,包括丰富的数组计算功能,并且PyTorch中的张量和NumPy中的数组相互转化时非常方便。
Pandas:该库提供了很多高性能、易用的数据结构和数据分析及可视化工具。
statsmodels:该库常用于统计建模和计量经济学,如回归分析、时间序列建模等。
-
(5)机器学习类
sklearn:该库是常用的机器学习库,包含多种主流机器学习算法。
sklearn.datasets: sklearn中的datasets模块提供了一些已经准备好的数据集,方便建模和分析。
sklearn.preprocessing:sklearn中的preprocessing模块提供了多种对数据集的预处理操作,如数据标准化等。
sklearn.metrics: sklearn中的metrics模块提供了对聚类、分类及回归效果的相关评价方法,如计算预测精度等。
sklearn.model selection: sklearn中的model selection模块提供了方便对模型进行选择的相关操作。
copy:提供复制对象的相关功能,可以用于复制模型的参数。
-
(6)数据可视化类
matplotib: Python中最常用的数据可视化库,可以绘制多种简单和复杂的数据可视化图像,如散点图、折线图、直方图等。
sebon: seaborn是一个基 于Python中matplotib的可视化库。它提供了一个个更高层次的绘图方法,可以使用更少的程序绘制有吸引力的统计图形。
hiddenlayer: 可用于可视化基于PyTorch、TensorFlow和Keras的网络结松内及深了度学习网络的训练过程。
PyTorchWViz: 通常用于可视化PyTorch建立的深度学习网络结构。
tensorboardX:可以通过该库将PyTorch的训练过程等事件与入TensorBoard. 买样就可以方便地利用Tensor Board来可视化深度学习 的训练过程和相关的中间结果战
wordcloud:通过词频来可视化词云的库,方便对文本的分析。
-
(7)自然语言处理
nltk: NLTK是Python的自然语言处理工具包,是NLP领域中最常使用的一个Python库, 而且背后有非常强大的社区支持。
jieba: jieba是针对中文分词最常用的分词工具,其提供了多种编程语言的接 口,包括Python。 可以使 用该库对中文进行分词等一系列的 预处理操作。
-
(8)图像操作
pillow: Pillow是一个对PIL友好的分支,是Python中 常用的图像处理库,PyTorch的相关图像操作也是基于Pillow库。
cv2: OpenCV是一个C++库, 用于实时处理计算机视觉方面的问题,涵盖了很 多计算机视觉领域的模块,cv2是其中的一个Python接 口。
skimage:用于图像处理的算法集合,提供了很多方便对图像进行处理的方法。
小结
在本小结内容中,主要介绍了机器学习与深度学习之间的差异和相关应用场景,以及常用的深度学习框架,并对这些框架进行了对比,着重介绍了PyTorch在深度学习中的优势。在小结的最后介绍了PTorch在进行深度学习时,需要用到的其他Python库。