一:源数据data文件夹。
进入data 目录,一共有以下几个文件:
ctb_dev.jsonl:开发集
ctb_test.jsonl:测试文件,存放用于测试用的句子,存放格式如下所示:该句子对应的动作序列+该句子的分词结果+该句子的词性标签 共1910句
ctb_train.jsonl:训练文件,存放用于训练模型参数的句子,存放格式和测试文件一样,以句子为单位:该句子对应的动作序列+该句子的分词结果+该句子的词性标签 共16091句
data_pro_ctb5.py:暂时没看懂这个Python文件的作用。。
generate_trainData.py:起转换文件格式的作用,真正的语料是ctb的树库语料,要将其转换为ctb_test.jsonl的格式,也就是下图转换为该句子对应的 动作序列+该句子的分词结果+该句子的词性标签:

二:结果数据results文件夹:
进入results文件夹一共有以下几个文件
vector_cache文件夹里存放的input_vector.pt:生成的词向量文件
glove.840B.300d.pt:运行程序生成的词向量文件(为什么是乱码)
glove.840B.300d.txt:事先训练好放进去的词向量文件,大约有10万个词向量。(如果替换语料的话,需要将这个文件注释或者替换为相应语言的词向量)
三:torchtext文件夹:东西太多,暂时略过
四:最后home目录下只剩下一大堆Python文件

------------------------------------------------------------------------------------------阅读ctbtrain文件的源代码-----------------------------------------------------------------------------------
ctbtrain是训练模型参数文件
开始阅读ctbtrain.py文件代码:
1. inputs transitions pos分别代表输入训练文件中的词,操作序列,词性标签。
运行程序打印输出三者的内容:
inputs:<torchtext.datasets.ctb.TextField object at 0x7f87ce600310>
transitions:<torchtext.data.Field object at 0x7f87ce5af110>
inputs.vocab.itos代表什么意思啊???代表的是几个转移动作的标签。
2.设置词向量的维度,但是不知道具体对应什么样的维度?
config = args(很重要的一个model)args就是一个parser模型,PyTorch/torchtext SNLI example
config.n_embed = len(inputs.vocab)
config.d_out = len(transitions.vocab)
config.n_cells = config.n_layers
3.build_vocab函数指的是构建词典,输入均是训练语料。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
evalue是测试文件,主要是评估函数my_evalue( )的实现过程,实现对测试集和开发集的评测,输出的是precision 和 Parser_precision的值。
spinn函数:定义分类器模型和tree模型。
util是模型参数的设置文件,打开如下所示
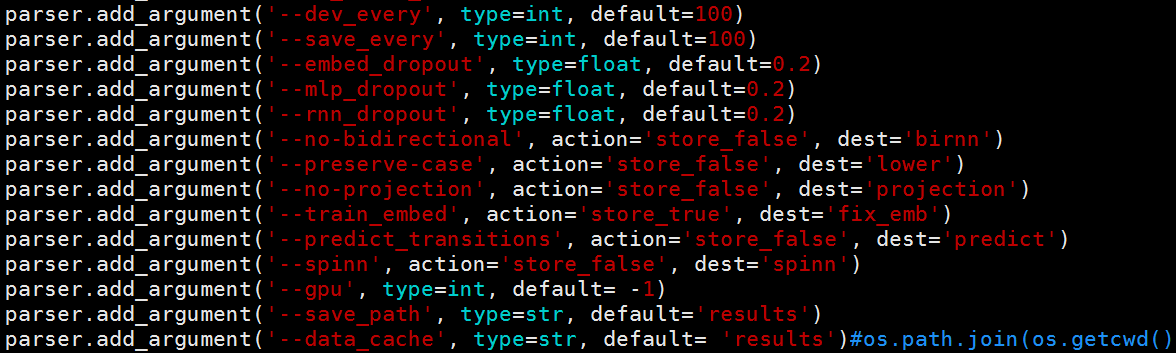
诸如迭代次数,是否使用GPU等。params.pkl 是什么鬼 打开是乱码
testlog_lstm_wbud和trainlog_lstm_wbud分别是日志记录文件,记录测试和训练过程中的准确率。不太明白的是这个准确率和evalue函数输出的准备率有啥区别。
-------------------------------------------------------------------------------model文件---------------------------------------------------------------------------------------------------------------------------
定义了class SNLIClassifier:
-----------------------------------------------------------------------程序包分析暂时结束,先执行下程序------------------------------------------------------------
源程序是进行中文的依存分析 我重新训练,打算用英文来知行:
一:输入训练文件格式如下(为了短期内看到效果,也就是让程序在5小时内完成,我选择语料的规模是500句。):

二:语料预处理(有个地方没想明白,但从树库语料,如何可以预测出shift-reduce转移动作)
1.调用generate函数,生成测试文件格式的语料:生成的测试文件语料格式为 原句子的词组+动作序列+词性词组序列(和原来中文的语料不太一样)
三:训练模型
1.在训练模型的时候会看到以下文件
![]()
分别为开发集 测试集 训练集 切割文件函数 生成测试集函数
执行ctbtrain.py会自动调用data文件夹下的训练集 也就是ctb_train.jsonl。
训练模型需要很久的时间,现在先看一下训练模型的ctbtrain.py文件源代码:(。。。。。。。。。。。。。)
执行结果:
前几次执行一直报错(报以下的错)一直不知道什么原因,后来才发现是更改语料后,不能再使用原来预先训练好的词向量。

最后训练集的规模有500句,开发和测试集各为100,执行了三个小时(中文),实验结果如下所示:
evalue_test_data:parser_pre: 73.8814317673
evalue_dev_data:parser_pre: 79.2047531993
替换为英文语料:500句 执行了六个小时。实验结果如下,和中文一样,迭代了49次
测试集:parser_pre: 90.2559867878
开发集:parser_pre: 90.2559867878这里测试集合开发集都一样。