参考:https://mp.weixin.qq.com/s/zSJXdaj5pLw_1I8lUPiKEA
关键理解:正则表达式是匹配模式,要么匹配字符,要么匹配位置
一、正则表达式中 匹配的位置:
如下图箭头所指,位置可以理解为相邻字符之间的位置。
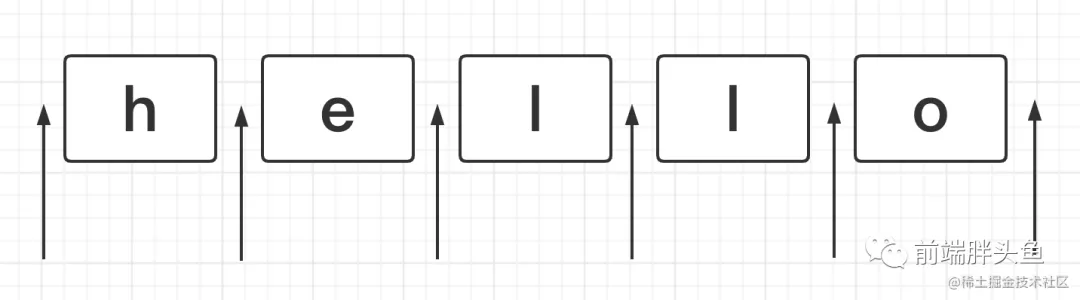
1、正则中常用来表示位置的符号主要有:
^、$、\b、\B、(?=p)、(?!p)、(?<=p)、(?<!p)
-
- ^、$ :匹配行的开头 和 结尾
- \b、\B:单词的边界、非单词的边界。具体说明是单词的边界可以看上面的参考文档
'xxx_love_study_1.mp4'.replace(/\b/g, '❤️') // ❤️xxx_love_study_1❤️.❤️mp4❤️ '[[xxx_love_study_1.mp4]]'.replace(/\B/g, '❤️') // ❤️[❤️[x❤️x❤️x❤️_❤️l❤️o❤️v❤️e❤️_❤️s❤️t❤️u❤️d❤️y❤️_❤️1.m❤️p❤️4]❤️]❤️
- (?=p) :符合p子模式前面的那个位置(也叫 正向前瞻 或 正向先行断言)。【注意,前瞻都是在括号里,即是一个分组】
'xxx_love_study_1.mp4'.replace(/(?=xxx)/g, '❤️') // ❤️xxx_love_study_1.mp4
- (?!p) :(?=p)反过来的意思,可以理解为(?=p)匹配到的位置之外的位置都是属于(?!p)的。(也叫 负向前瞻 或 负向先行断言)
'xxx_love_study_1.mp4'.replace(/(?!xxx)/g, '❤️') // x❤️x❤️x❤️_❤️l❤️o❤️v❤️e❤️_❤️s❤️t❤️u❤️d❤️y❤️_❤️1❤️.❤️m❤️p❤️4❤️
- (?<=p) : 符合p子模式后面 (注意(?=p)表示的是前面) 的那个位置。【也叫 正向后顾,ES9(2018)开始支持】
'xxx_love_study_1.mp4'.replace(/(?<=xxx)/g, '❤️') //xxx❤️_love_study_1.mp4
- (?<!p) : (?<=p)反过来的意思,可以理解为(?<=p)匹配到的位置之外的位置都是属于(?<!p)的。【也叫 负向后顾,ES9(2018)开始支持】
'xxx_love_study_1.mp4'.replace(/(?<!xxx)/g, '❤️') // ❤️x❤️x❤️x_❤️l❤️o❤️v❤️e❤️_❤️s❤️t❤️u❤️d❤️y❤️_❤️1❤️.❤️m❤️p❤️4❤️
二、匹配字符
1、两种模糊匹配:
正则如果只有精确匹配,那么便完全没有了意义
- 横向:一个正则可匹配的字符串的长度不是固定的,可以是多种情况,通过量词+、*、?、{m,n},可实现横向匹配。
let reg = /ab{2,5}c/ let str = 'abc abbc abbbc abbbbc abbbbbc abbbbbbc' str.match(reg) // [ 'abbc', 'abbbc', 'abbbbc', 'abbbbbc' ] - 纵向:一个正则匹配的字符串,具体到某一位字符时,可以不是某个确定的字符串,可以有多种可能,实现方式是范围类( 其实多选分支|也可以实现 )。
let reg = /a[123]c/ let str = 'a0b a1b a2b a3b a4b' str.match(reg) // [ 'a1b', 'a2b', 'a3b' ]
2、范围类: 一类字符中 可能性 的一个字符。
- 范围表示法:
[123456abcdefABCDEF] => [1-6a-fA-F]
- 排除字符组
[^abc]
- 常见简写形式
3、量词:
- 量词 & 简写
1. {m,} // 至少出现m次 2. {m} // 出现m次 3. ? // 出现0次或者1次,等价于{0,1} 4. + // 至少出现1次,等价于{1,} 5. * // 出现人一次,等价于{0,} - 贪婪匹配 VS 惰性匹配: 正则本身是贪婪的,会尽可能的多匹配符合模式的字符
- 贪婪匹配
let regex = /\d{2,5}/g let string = '123 1234 12345 123456' // 贪婪匹配 // string.match(regex) // [ 123, 1234, 12345, 12345 ] // 惰性匹配 let regex2 = /\d{2,5}?/g // string.match(regex) // [ 12, 12, 34, 12, 34, 12, 34, 56 ] // 说明:贪婪模式是针对 量词使用最小量词还是尽可能大的量词。如{2,5},是2作为量词,还是尽可能多的靠近5的数字作为量词 - 惰性匹配:量词后面加一个?,即变成了惰性匹配。
贪婪量词 惰性量词 {m,n} {m,n}? {m,} {m,}? ? ?? + +? * *?
- 贪婪匹配
- 多选分支:多选分支可以支持多个子模式任选其一,形式是(p1|p2|p3)。【分支结构在分组和全局上都可用,全局上就是把整个正则分份了】
let regex = /good|nice/ let string = 'good idea, nice try.' // string.match(regex) // [ 'good', 'nice' ] // 注意,用/good|goodbye/去匹配'goodbye' 匹配到的是good // 因为分支结构是惰性的,前面的匹配上了,后面的就不再尝试了
三、括号的神奇作用:
括号在正则表达式中就是分组的作用,但是有些正则的方法 里,基于分组的括号会又一些特殊的作用。
【括号的神奇作用,关键是分组具有捕获功能,会把每个分组里匹配的值保存起来。也叫捕获性分组,默认就是捕获性分组】
- 提取数据:match 方法 或 全局的 RegExp.$1-$9
/* 提取年月日 2021-08-14 */ let reg = /(\d{4})-(\d{2})-(\d{2})/ console.log('2021-08-14'.match(reg)) // ["2021-08-14", "2021", "08", "14", index: 0, input: "2021-08-14", groups: undefined] // 第二种解法,通过全局的$1...$9读取 引用的括号数据 let reg = /(\d{4})-(\d{2})-(\d{2})/ let string = '2021-08-14' reg.test(string) console.log(RegExp.$1) // 2021 console.log(RegExp.$2) // 08 console.log(RegExp.$3) // 14
- 数据替换:replace 方法
/* 将以下格式替换为mm/dd/yyy 2021-08-14 */ // 第一种解法 let reg = /(\d{4})-(\d{2})-(\d{2})/ let string = '2021-08-14' // 第一种写法 let result1 = string.replace(reg, '$2/$3/$1') console.log(result1) // 08/14/2021 // 第二种写法 let result2 = string.replace(reg, () => { return RegExp.$2 + '/' + RegExp.$3 + '/' + RegExp.$1 }) console.log(result2) // 08/14/2021 // 第三种写法 let result3 = string.replace(reg, ($0, $1, $2, $3) => { return $2 + '/' + $3 + '/' + $1 }) console.log(result3) // 08/14/2021
- 反向引用(很重要): 除了通过js引用分组的内容,也可以通过正则来引用分组内容。
/* 写一个正则支持以下三种格式 2016-06-12 2016/06/12 2016.06-12 */ let regex = /(\d{4})([-/.])\d{2}\2\d{2}/ // 这里的 \2 就是在正则中 引用分组内容 var string1 = "2017-06-12"; var string2 = "2017/06/12"; var string3 = "2017.06.12"; var string4 = "2016-06/12"; console.log( regex.test(string1) ); // true console.log( regex.test(string2) ); // true console.log( regex.test(string3) ); // true console.log( regex.test(string4) ); // false
- 正则中 引用分组内容,通过 \1-\9来引用。
- 引用不存在的分组会怎样: 即匹配的就是\1 \2本身
- 分组后面有量词会怎样:分组后面如果有量词,分组最终(注意是分组,不是说整体)捕获的数据是最后一次的匹配。
'12345'.match(/(\d)+/) // ["12345", "5", index: 0, input: "12345", groups: undefined] /(\d)+ \1/.test('12345 1') // false /(\d)+ \1/.test('12345 5') // true
- 非捕获性括号:如果想要括号最原始的功能,但不会引用它,也就是既不会出现在API引用里,也不会出现在正则引用里,可以使用 非捕获性括号(?:p)
// 非捕获型引用 let reg = /(?:ab)+/g console.log('ababa abbb ababab'.match(reg)) // ["abab", "ab", "ababab"] // 注意这里,因为是非捕获型分组,所以使用match方法时,不会出现在数组的1位置了 let reg = /(?:ab)+/ console.log('ababa abbb ababab'.match(reg)) // ["abab", index: 0, input: "ababa abbb ababab", groups: undefined] let reg = /(ab)+/ console.log('ababa abbb ababab'.match(reg)) // ["abab", "ab", index: 0, input: "ababa abbb ababab", groups: undefined]
说明:非捕获性分组,只是针对当前括号的功能,其它括号的分组还是会有捕获功能的。
四、正则表达式中的单元结构 (这个是自己定义的名称)
- 单个字符
/f/g
- 范围类:【范围中的某一个类】
/[abc]/ // a,b,c 这个范围中的一个 /[0-9]/ // a-9 这个范围中的一个
- 组:以字符串为一个整体,而不是单个字符。
五、RegExp.$1-$9 说明
1、$1, ..., $9 属性是静态的, 他不是独立的的正则表达式属性. 所以, 我们总是像这样子使用他们RegExp.$1, ..., RegExp.$9
2、正则表达式的 括号匹配项是无限的, 但是RegExp对象能捕获的只有九个。
3、属性的值是只读的而且只有在正确匹配的情况下才会改变。
能使RegExp.$1-$9 改变的API有,test()、exec()、以及String的正则方式。我们一般使用test比较好,不会改变字符串。
var str = 'hello world'; var pattern = /([a-z]+)\s([a-z]+)/; pattern.test(str); //这个地方必须运行正则匹配一次,方式不限,可以是test()、exec()、以及String的正则方式 console.log(RegExp.$1) //'hello' 第一个分组([a-z]+)的值 console.log(RegExp.$2) //'world' 第二个分组([a-z]+)的值 var n_str = RegExp.$2+' '+RegExp.$1; console.log(n_str) //world hello
如果不通过RegExp.$1-$9获取分组内容,不需要单独调用一次匹配接口。无论是js来引用分组内容,还是 通过正则来引用分组内容。
调用正则的API都可以直接使用 捕获分组内容。如:
// js来引用分组内容 let reg = /(\d{4})-(\d{2})-(\d{2})/ let string = '2021-08-14' let result1 = string.replace(reg, '$2/$3/$1') // 操作正则的API中直接可以使用 捕获的值 console.log(result1) // 08/14/2021 // 或 通过正则来引用分组内容 let regex = /(\d{4})([-/.])\d{2}\1\d{2}/ // 这里的 \1 就是 通过正则来引用分组内容。 操作正则时,用到正则相关的 匹配接口,自然就会更新$1-$9的内容,使用正则上可以直接使用 var string1 = "2017-06-12"; console.log( regex.test(string1) ); // true
六、