倒排索引
1.了解概念
"倒排索引"是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(Inverted Index)。
2.实例描述
通常情况下,倒排索引由一个单词(或词组)以及相关的文档列表组成,文档列表中的文档或者是标识文档的ID号,或者是指文档所在位置的URL。在实际应用中,还需要给每个文档添加一个权值,用来指出每个文档与搜索内容的相关度
3.样例输入输出

4.算法思想
1)map过程
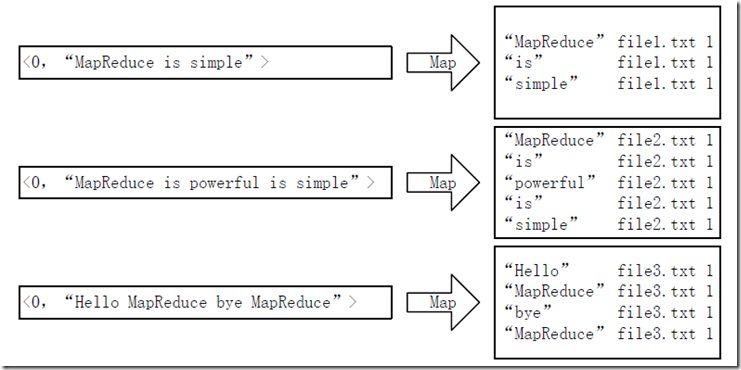
为统计每个单词出现在每个文件中的次数,将单词word作为map阶段的key值,“filename:1”作为value值。可以得到上图的结果。传到combine的格式为:MapReduce:file1.txt
这样做的好处是:可以利用MapReduce框架自带的Map端排序,将同一文档的相同单词的词频组成列表,传递给Combine过程,实现类似于WordCount的功能。
2)combine阶段
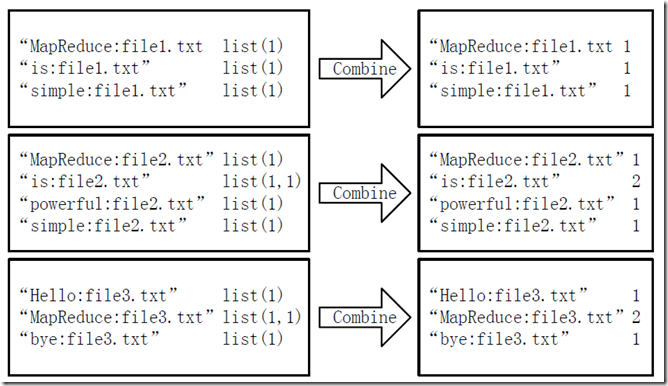
经过map方法处理后,Combine过程将key值相同的value值累加,得到一个单词在每个文档中出现的次数,如果直接将图所示的输出作为Reduce过程的输入,在Shuffle过程时将面临一个问题:所有具有相同单词的记录(由word、filename和次数组成)应该交由同一个Reducer处理,但当前的key值无法保证这一点,所以必须修改key值和value值。这次将单词作为key值,filename和词频组成value值(如"file1.txt:1")。
3)reduce过程
reduce过程只需将相同key值的value值组合成倒排索引文件所需的格式即可,剩下的事情就可以直接交给MapReduce框架进行处理了。
5.代码实现
public class InvertedIndex {
static String INPUT_PATH="hdfs://master:9000/index";
static String OUTPUT_PATH="hdfs://master:9000/output/index";
static class MyMapper extends Mapper<Object,Object,Text,Text>{
private Text output_key=new Text();
private Text output_value=new Text();
String fileName=new String();
protected void setup(Context context)throws java.io.IOException,java.lang.InterruptedException{
FileSplit fs=(FileSplit)context.getInputSplit(); //得到文件的名字filename
fileName=fs.getPath().getName();
System.out.println(fileName);
}
protected void map(Object key, Object value, Context context) throws IOException, InterruptedException{
String[] tokens=value.toString().split(" "); //以空格为分隔
if(tokens!=null){
for(int i=0;i<tokens.length;i++){
output_key.set(tokens[i]+":"+fileName); //设置 key---word:filename
output_value.set("1"); //每出现一次+1
context.write(output_key, output_value);
System.out.print("1=="+output_key);
System.out.println("1=="+output_value); //1==simple:a02.txt 1== 1
}
}
}
}
static class Mycombine extends Reducer<Text,Text,Text,Text>{
Text output_key=new Text();
Text output_value=new Text();
protected void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
String[] tokens=key.toString().split(":"); //将word和filename以:分隔开
int sum=0;
for(Text val:values){
sum+=Integer.parseInt(val.toString()); //将单词相同的1相加
}
output_key.set(tokens[0]);
output_value.set(tokens[1]+":"+sum);
context.write(output_key, output_value); //2==mapreduce 2==a01.txt:1
System.out.print("2=="+output_key);
System.out.println("2=="+output_value);
}
}
static class MyReduce extends Reducer<Text,Text,Text,Text>{
private Text result = new Text();
protected void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
String fileList = new String();
for (Text value : values){ //连接filename和出现的次数
fileList += value.toString() + ";" ;
}
result.set(fileList);
context.write(key,result);
System.out.println("3=="+key);
}
}
public static void main(String[] args) throws Exception{
Path outputpath=new Path(OUTPUT_PATH);
Configuration conf=new Configuration();
FileSystem file = outputpath.getFileSystem(conf);
if(file.exists(outputpath)){
file.delete(outputpath,true);
}
Job job=Job.getInstance(conf);
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job,outputpath);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setCombinerClass(Mycombine.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.waitForCompletion(true);
}
}