缓存数据一致性一般是两种解决方案
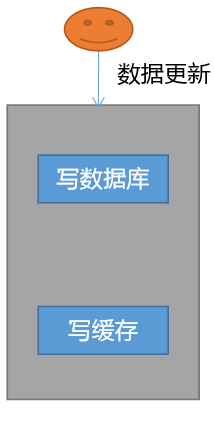
双写模式
做法顺序:先写数据库,再写缓存
并发性的问题:
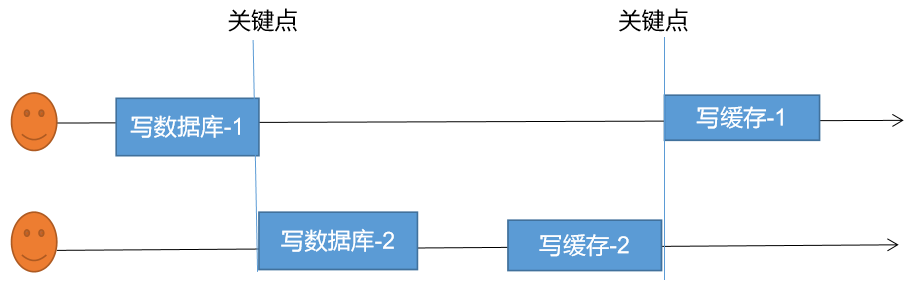
由于卡顿等原因,导致写缓存2在最前,写缓存1在后面就出现了不一致
脏数据问题:
这是暂时性的脏数据问题,但是在数据稳定,缓存过期以后,又能得到最新的正确数据
读到的最新数据有延迟:最终一致性
失效模式
做法顺序:先写数据库,在删除缓存

并发下的问题:

由于网络或者i/o问题导致第三个请求拿到了数据库中数据:db-1,此时第二个请求数据库写更新db-1->db-2已完成,立刻删除缓存,第三个请求又将缓存刷新成第一个请求时的数据
还是会出现脏数据问题:最终不一致性
解决方案:
无论是双写模式还是失效模式,都会导致缓存的不一致问题。即多个实例同时更新会出事。怎么办?
- 如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加 上过期时间,每隔一段时间触发读的主动更新即可
- 如果是菜单,商品介绍等基础数据,也可以去使用canal订阅binlog的方式(比较优秀)。
- 缓存数据+过期时间也足够解决大部分业务对于缓存的要求。
- 通过加锁保证并发读写,写写的时候按顺序排好队。读读无所谓。所以适合使用读写锁。(业务不关心 脏数据,允许临时脏数据可忽略);
总结:
- 我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,保 证每天拿到当前最新数据即可。
- 我们不应该过度设计,增加系统的复杂性 。
- 遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。