1、
运行start-dfs.sh启动HDFS守护进程,start-yarn.sh面向YARN的资源器和节点管理器,资源管理器web地址是http://localhost:8080/。输入stop.dfs.sh,stop-yarn.sh终止守护进程。
以上是打开hadoop服务的两种方法,每次使用hadoop之前都需要使用这条命令打开hadoop,接着使用jps查看服务是否已经启动,在浏览器中http://localhost:50070查看hadoop相关情况
2、
运行 ps -e | grep ssh,查看是否有sshd进程ss
如果没有,说明server没启动(谷总说ssh是自动启动的)
3、
网络配置过程中,以sudo的方式修改/etc/hosts文件(否则提示文件是只读的)过程,ip地址是虚拟机里网卡的ip地址,使用ifconfig察看ip(hadoop装在虚拟机里的情况下),修改完成之后使用source /etc/hosts(source命令也称为“点命令”,也就是一个点符号(.)。source命令通常用于重新执行刚修改的初始化文件,使之立即生效,而不必注销并重新登录。用法: source filename 或 . filename)。另外,虚拟机的网路配置选项选择桥接,这样就可以实行物理机与虚拟机、Master与Slave之间的通信(可以ping通,两台主机之间可以ping通前提是两台主机在同一个网段之内,同一个网段就是网络标识相同,网络标识的计算方法就是ip地址和掩码进行与运算。想在同一网段,必需做到网络标识相同,那网络标识怎么算呢?各类IP的网络标识算法都是不一样的。A类的,只算第一段。B类,只算第一、二段。C类,算第一、二、三段。)
将hadoop文件通过ssh从Master发给Slave之后,需要在Slave机器上使用chown命令修改hadoop文件的所有者以及所属的群组(http://www.cnblogs.com/lz3018/p/4871391.html)
4、
由于多次格式化hdfs,导致格式化hdfs的时候失败(提示Reformat Y or N,输入了Y也不能格式化成功),可能会导致namenode无法启动,所以如果要重新格式化,需要按如下步骤进行:在进行一切实验之前,我们首先清空/usr/local/hadoop/tmp以及logs文件夹(其实就是情况hadoop.tmp.dir配置项路径下的tmp和logs文件夹即可,不用下面那么麻烦)。
1、查看hdfs-ste.xml:
- <property>
- <name>dfs.name.dir</name>
- <value>/home/hadoop/hdfs/name</value>
- <description>namenode上存储hdfs名字空间元数据</description>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>/home/hadoop/hdsf/data</value>
- <description>datanode上数据块的物理存储位置</description>
- </property>
将 dfs.name.dir所指定的目录删除、dfs.data.dir所指定的目录删除
2、查看core-site.xml:
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/home/hadoop/hadooptmp</value>
- <description>namenode上本地的hadoop临时文件夹</description>
- </property>
将hadoop.tmp.dir所指定的目录删除。
3)重新执行命令:bin/hdfs namenode -format
格式化完毕。
注意:原来的数据全部被清空了。产生了一个新的hdfs。
5、运行bin/hdfs dfsadmin -report,结果显示
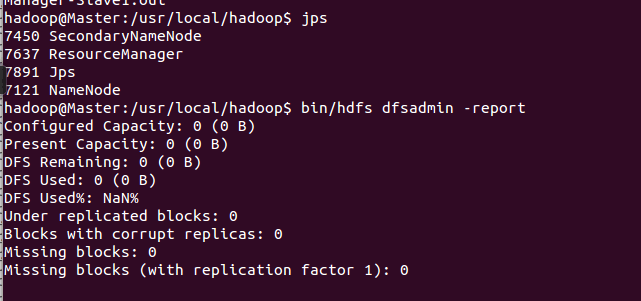
结果都是0,说明datanode有问题,进去Slave1查看hadoop-hadoop-datanode-Slave1.log文件,就是datanode的日志文件,提示信息如下:
Retrying connect to server: localhost/127.0.0.1:9000. Already tried 5 time。。。。。
这说明datanode连接不到Master,到server的链路不通,最后发现Slave1端的core-site.xml文件有一个配置项并没有改过来(Master上改过来了)
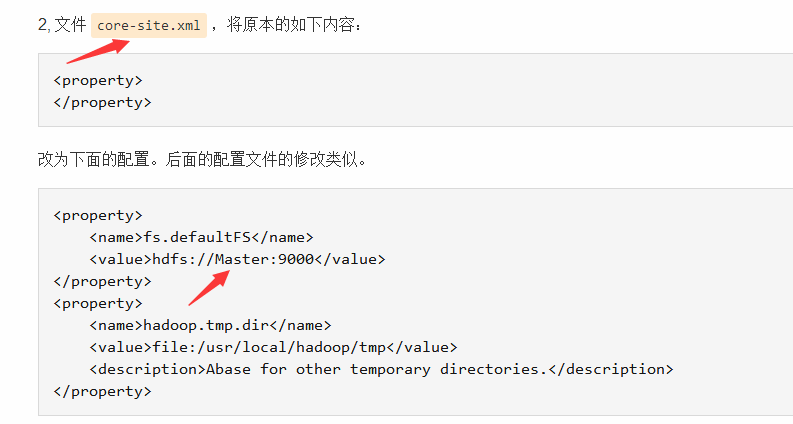
原先是localhost:9000,改为Master:9000,成功。localhost:9000也对应了 Retrying connect to server: localhost/127.0.0.1:9000. Already tried 5 time。。。。。
6、
执行mapreduce作业的时候会job会卡在那里,一直卡着,发现原因是mapred-site.xml和yarn-site.xml的配置问题,正确配置如下:
mapred-site.xml
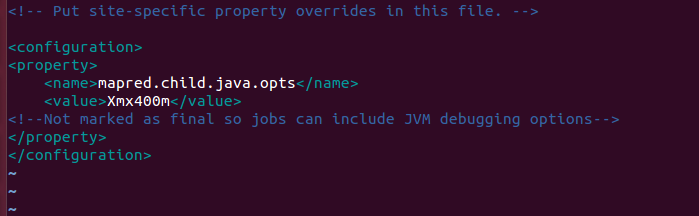
另外使用
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar grep input output 'dfs[a-z.]+' 运行实例时正确写法是
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep input/hadoop output 'dfs[a-z.]+'
Hadoop运行程序时,默认输出目录不能存在,因此再次运行需要执行如下命令删除 output文件夹:
bin/hdfs dfs -rm -r /user/hadoop/output # 删除 output 文件夹
使用命令 bin/hadoop fs -ls /usr/hadoop 查看hdfs中/usr/hadoop有哪些文件
最后使用
bin/hdfs dfs -cat output/* 查看mapreduce运算结果,如下图所示:
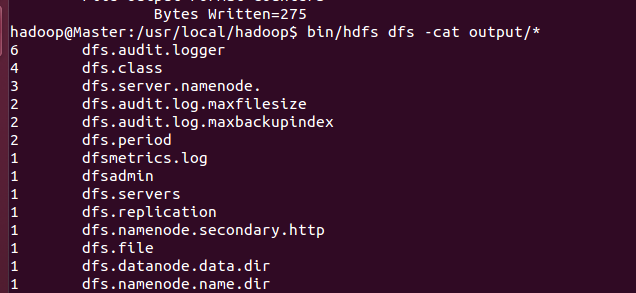
7、
NodeManager没有启动原因之一:
就是yarn-site.xml中
<property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
属性yarn.nodemanager.aux-services的值应为mapreduce_shuffle,而不是mapreduce.shuffle(Hadoop权威指南第三版上348页配置yarn-site.xm这样配置)
8、补充两个hadoop的下载地址:
http://mirrors.cnnic.cn/apache/hadoop/common/
http://mirror.bit.edu.cn/apache/hadoop/common/
参考:
http://www.powerxing.com/install-hadoop/