开源工具
TensorFlow:谷歌,C++、Python,Linux、Windows、Mac OS X、Andriod、iOS
Caffe:加州大学,C++、Python、Matlab,Linux、Windows、Mac OS X
PaddlePaddle:百度
TensorFlow安装(Python)
pip install tensorflow(cpu版)
官网:https://www.tensorflow.org/
推荐图书:
《深度学习》https://item.jd.com/14454752659.html
《TensorFlow实战google深度学习框架》https://item.jd.com/12125572.html
TensorFlow入门
计算模型:计算图
数据模型:张量(tensor)
运行模型:会话(session)
TensorFlow程序的两个阶段
定义计算(在计算图中)
执行计算(在会话中)
Tensor:张量(数据类型)
类比多维数组(numpy中的ndarray)
类型:标量、向量、矩阵、数组等
作用:对计算结果的引用、获得计算结果
Flow:流
通过计算图的形式表达计算的编程系统
计算图(可默认生成):节点/操作(op)
a = tf.constant([1.0,2.0],name='a')
b = tf.constant([2.0,3.0],name='b')
result = a+b
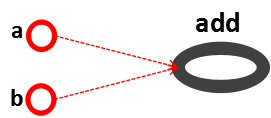
注意:此过程只生成计算图,并不执行计算
必须知道:
使用图(graph)来表示计算任务
在被称之为会话(Session)的上下文(context)中执行图
使用tensor表示数据
通过变量(variable)维护状态
使用feed和fetch可以为任意的操作(operation)赋值或者从其中获取数据
# -*- coding:utf-8 -*- import tensorflow as tf #定义计算 a = tf.constant([1.5, 3.0], dtype=tf.float64) #constant常量构造函数 指定类型dtype=tf.float64 b = tf.constant([0., 1], name = 'b') #构造的常量区别名为b res = a + b #注意TensorFlow里面数据类型要一致 # print(res, b) 这时返回的是并不是我们想看到的直观的结果 #Tensor("add:0", shape=(2,), dtype=float32) Tensor("b:0", shape=(2,), dtype=float32) #执行计算 sess = tf.Session() #构建会话 res,b = sess.run([res, b])#执行 sess.close() #关闭会话 #使用with语句 等价于上面三条语句 # with tf.Session() as sess: # sess.run(res) print(res, b)
案例
任务1:拟合三维平面
通过
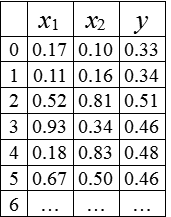
![]()
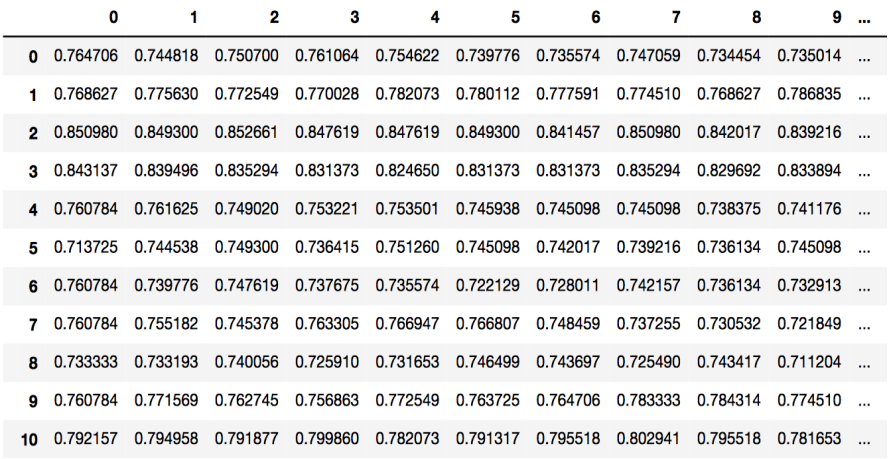
生成了100个样本点,如表所示
现假设函数关系未知,请根据这100个样本数据找出合适的a,b,c
使得

求解步骤:
利用Numpy生成100个样本点
构造一个线性模型
最小化方差
初始化变量
启动图
拟合平面(开始训练)
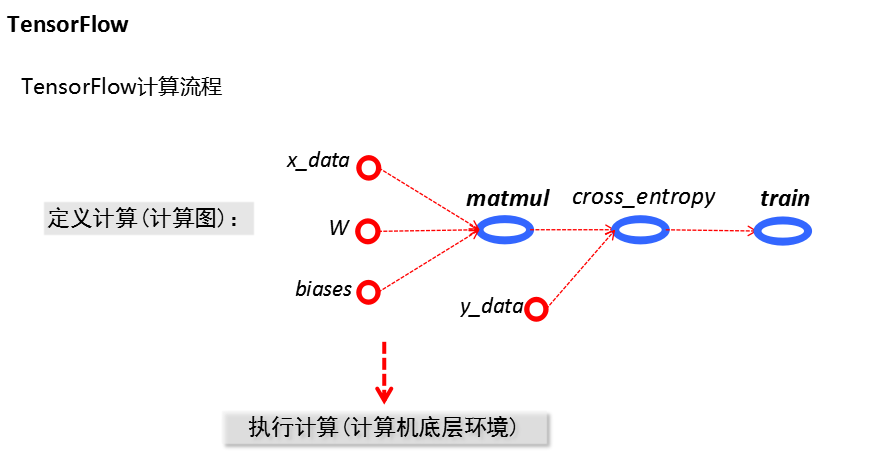

TensorFlow计算方法:
为了在Python中进行高效的数值计算,将一些耗时操作放在Python环境的外部来计算(Numpy);
每一个操作切换回Python环境时仍需要不小的开销,这一开销主要用来进行数据迁移;
TensorFlow将计算过程完全运行在Python外部;
Tensorflow依赖于一个高效的C++后端来进行计算,并通过session连接。先创建一个图,然后在session中启动它。
任务1代码:
# -*- coding:utf-8 -*- import tensorflow as tf import numpy as np #生成100个点 numpy默认生成64位 x_data = np.float32(np.random.rand(2, 100)) y_data = np.float32(np.dot([0.1, 0.2], x_data) + 0.3) #矩阵乘法.dot 实际y值 #定义 w = tf.Variable(tf.zeros([1, 2])) bias = tf.Variable(tf.zeros([1])) y = tf.matmul(w, x_data) + bias #构建线性方程 matmul矩阵乘法 #损失函数 (目标函数) loss = tf.reduce_mean(tf.square(y - y_data)) #优化器 optimizer = tf.train.GradientDescentOptimizer(0.5) #梯度下降法 0.5 学习率 train = optimizer.minimize(loss) init = tf.global_variables_initializer() #全局变量初始化 #构建会话 sess = tf.Session() sess.run(init)#变量初始化 for i in range(100): w1, b1 = sess.run([w, bias]) print(w1, b1) sess.run(train) #模型训练 sess.close()
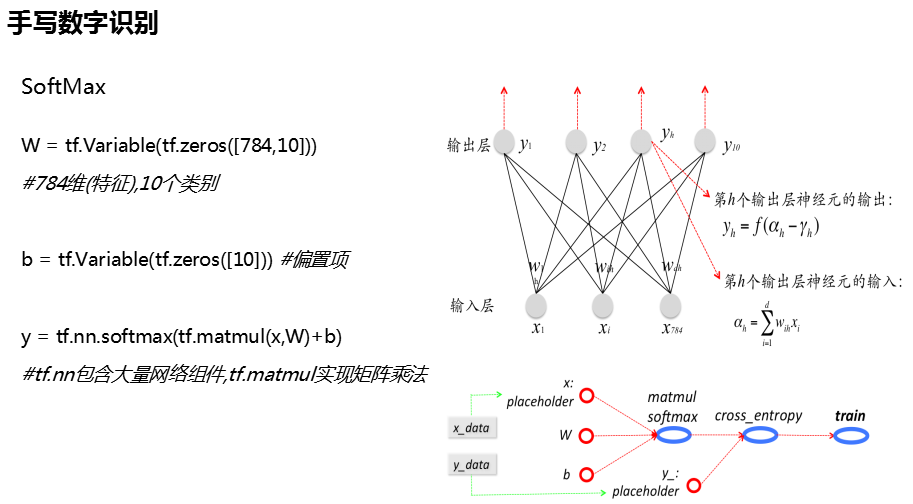
任务二:SoftMax函数Mnist手写数字识别

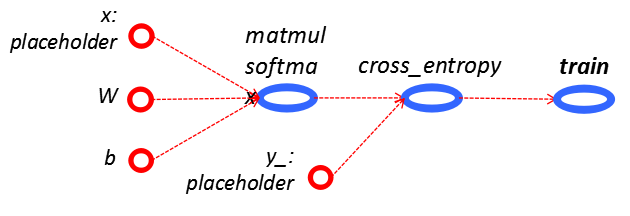
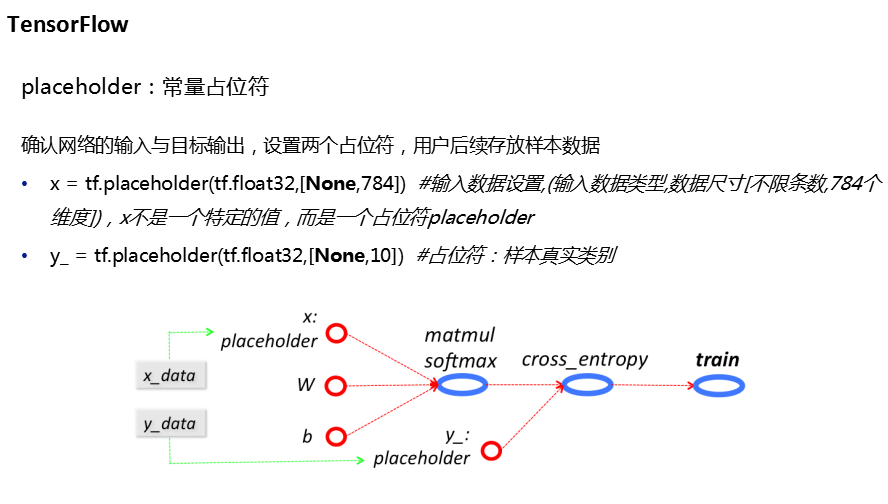
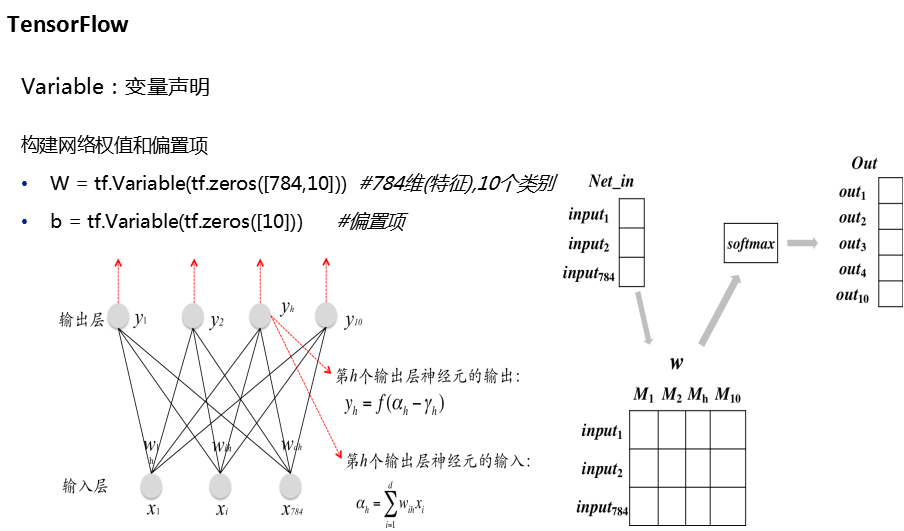
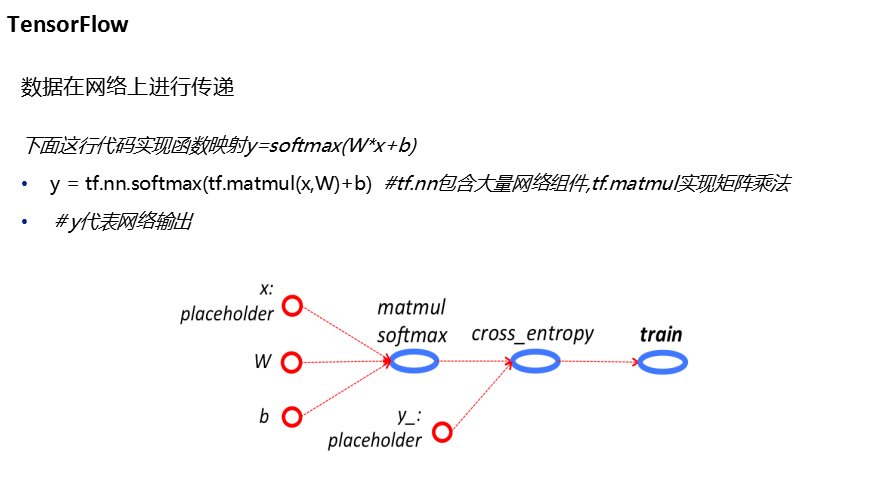


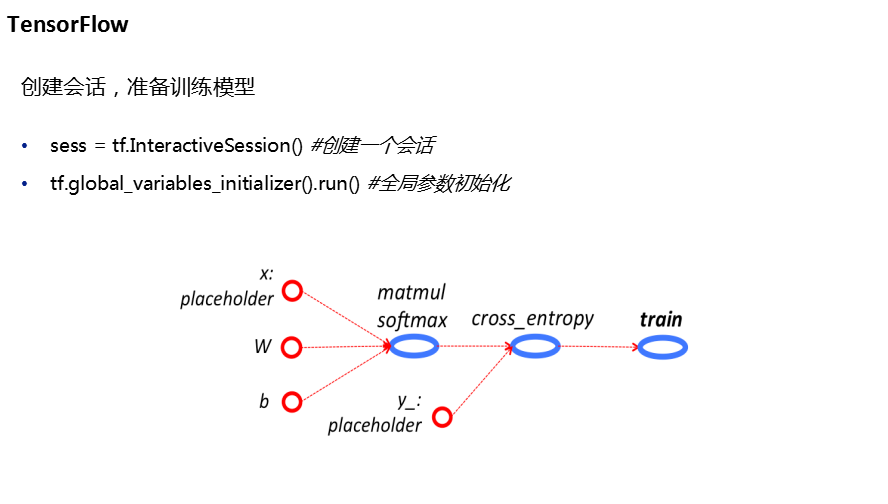


任务2代码:
# -*- coding:utf-8 -*- import tensorflow as tf import numpy as np from tensorflow.examples.tutorials.mnist import input_data #当前项目工作路径下有数据就直接加载,没有就下载 mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) #独热编码表示类别标签 w = tf.Variable(tf.zeros([784,10])) #偏置值 bias = tf.Variable(tf.zeros([10])) #训练集 x_data = tf.placeholder(tf.float32, [None, 784]) #标签 y_data = tf.placeholder(tf.float32, [None, 10]) #激活函数 y = tf.nn.softmax(tf.matmul(x_data, w) + bias) #计算预测结果与实际的偏差 交叉熵 cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_data * tf.log(y), axis=1)) #优化算法 optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(cross_entropy) #初始化变量 init = tf.global_variables_initializer() #构建会话 with tf.Session() as sess: sess.run(init) for i in range(1000): if i%50 == 0: #每训练50轮打印一次验证集样本的预测精度 # 判断模型预测值 与实际值是否相等 pre = tf.equal(tf.argmax(y, axis=1), tf.argmax(y_data, axis=1)) # 每行最大值 acc = sess.run(pre, feed_dict={x_data: mnist.validation.images, y_data: mnist.validation.labels}) # 验证集 做验证 print(i + 'acc:' + sum(acc) / len(acc))#打印精度 #随机选取100个样本(包含标签) x_s, y_s = mnist.train.next_batch() sess.run(train, feed_dict={x_data:x_s, y_data:y_s})#一次训练
任务3:手写数字识别
自己在A4纸上手写数字并裁剪编号


处理流程:



解决方案:
1、SoftMax
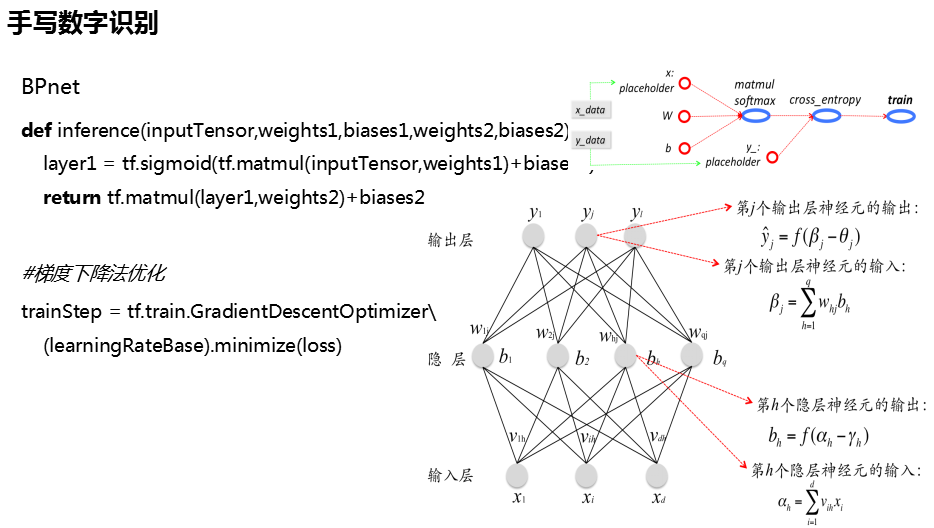
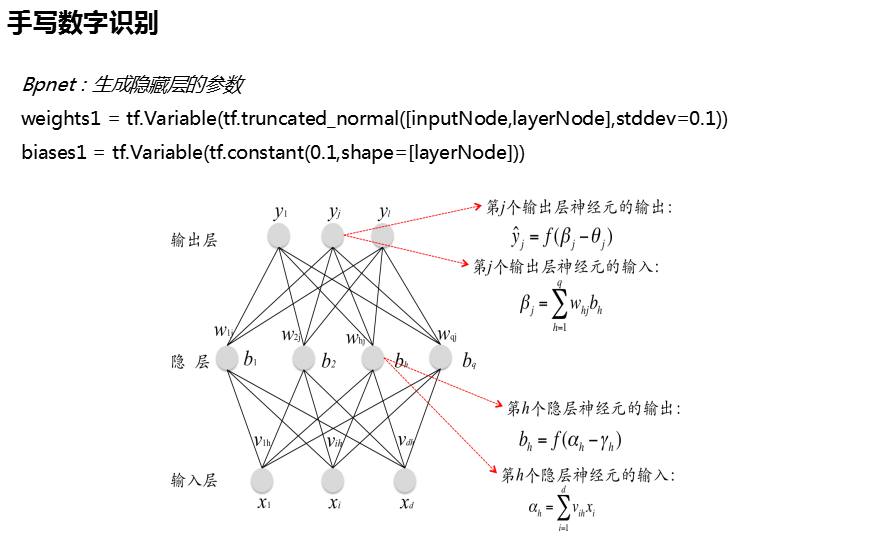
2、BP
3、CNN
SoftMax解决方案代码
数据预处理
import cv2 import re,os import numpy as np class ImgTrans: def __init__(self,path='./images/trainImages/'): self.path = path def getimgnames(self): filenames = os.listdir(self.path) imgnames = [] for i in filenames: if re.findall('^d_d+.png$',i)!=[]: imgnames.append(i) return imgnames def getimgdata(self,shape=(28,28)): imgnames = self.getimgnames() n = len(imgnames) M,N = shape data = np.zeros([n,M*N],dtype='float32') labels = np.zeros([n],dtype='float32') for i in range(n): img = cv2.imread(self.path+imgnames[i]) da_new = cv2.resize(img,shape) da_new = da_new[:,:,0]/255 data[i,:] = np.reshape(da_new,[M*N]) labels[i] = imgnames[i][0] return data,labels # imgtrans = ImgTrans(path='./images/trainImages/') # data,labels = imgtrans.getimgdata() # print(data.shape)
模型构建
# -*- coding:utf-8 -*- import tensorflow as tf from imgtrans import ImgTrans path_tr = './images/trainimages/' path_te = './images/testimages/' #训练集 测试集数据与类标签 data_tr,labels_tr = ImgTrans(path = path_tr).getimgdata() data_te,labels_te = ImgTrans(path = path_te).getimgdata()#shape=(64,64) #类标签转化为独热编码 labels_tr,labels_te = tf.one_hot(labels_tr,10), tf.one_hot(labels_te,10) w = tf.Variable(tf.zeros([784,10])) bias = tf.Variable(tf.zeros([10])) #偏置值 y = tf.nn.softmax(tf.matmul(data_tr, w) + bias) #激活函数 预测结果 cross_enttropy = tf.reduce_mean(-tf.reduce_sum(labels_tr*tf.log(y), axis=1)) #交叉熵 optimizer = tf.train.GradientDescentOptimizer(0.08) #梯度下降法优化器 train = optimizer.minimize(cross_enttropy) #利用优化器对交叉熵进行优化 init = tf.global_variables_initializer() #全局变量初始化 #构建会话 with tf.Session() as sess: sess.run(init) labels_tr,labels_te = sess.run([labels_tr, labels_te]) for i in range(1000): if i%50 == 0: #没训练50 轮打印一次训练集样本的训练精度 pre = tf.equal(tf.argmax(y, axis=1), tf.argmax(labels_tr, axis=1)) acc = sess.run(pre) print(i,'acc:',sum(acc)/len(acc)) sess.run(train) #观察在测试集上的泛化能力 y = tf.nn.softmax(tf.matmul(data_te,w) + bias) pre_te = tf.equal(tf.argmax(y, axis=1), tf.argmax(labels_te, axis=1)) acc = sess.run(pre_te) print('Test acc:', sum(acc) / len(acc))