一.scrapy架构介绍
1.结构简图:
主要组成部分:Spider(产出request,处理response),Pipeline,Downloader,Scheduler,Scrapy Engine
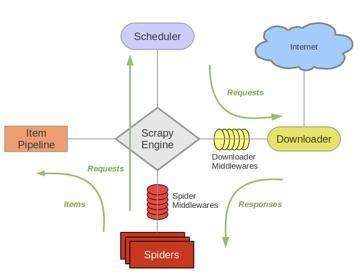
2.结构详细图:
主要步骤(往复循环):
1.Spiders(自己书写的爬虫逻辑,处理url及网页等【spider genspider -t 指定模板 爬虫文件名 域名】),返回Requests给engine——>
2.engine拿到requests返回给scheduler(什么也没做)——>
3.然后scheduler会生成一个requests交给engine(url调度器)——>
4.engine通过downloader的middleware一层一层过滤然后将requests交给downloader——>
5.downloader下载完成后又通过middleware过滤将response返回给engine——>
6.engine拿到response之后将response通过spiders的middleware过滤后返回给spider,然后spider做一些处理(如返回items或requests)——>
7.spiders将处理后得到的一些items和requests通过中间件过滤返回给engine——>
8.engine判断返回的是items或requests,如果是items就直接返回给item pipelines,如果是requests就将requests返回给scheduler(和第二步一样)

源码简介:
源码核心的东西
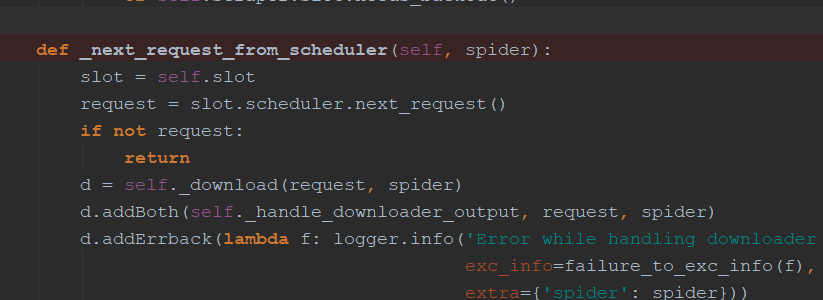
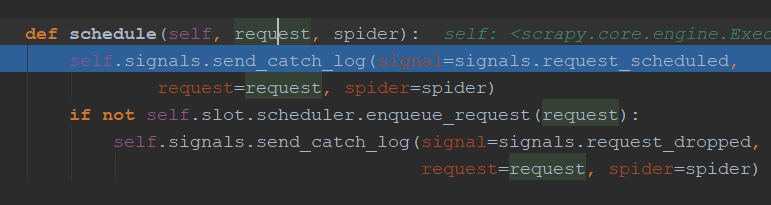
engine.py中介绍:通过_next_request_from_scheduler判断是否有requests(request返回给engine直接返回给scheduler【第一步】),request会首先调用schedule()函数发送给schedule(第二步),然后返回给engine
downloader简介:

可以处理很多类型的下载
Request和Response简介:
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None):
......
官网介绍(具体官网网址:https://doc.scrapy.org/en/latest/topics/request-response.html):
| 参 数: |
- url(字符串) - 此请求的URL
- callback(callable) - 将使用此请求的响应(一旦下载)调用的函数作为其第一个参数。有关更多信息,请参阅下面将其他数据传递给回调函数。如果请求未指定回调,则将使用spider的
parse()方法。请注意,如果在处理期间引发异常,则会调用errback。
- method(string) - 此请求的HTTP方法。默认为
'GET'。
- meta(dict) -
Request.meta属性的初始值。如果给定,则此参数中传递的dict将被浅层复制。
- body(str 或unicode) - 请求体。如果a
unicode被传递,则str使用传递的编码(默认为utf-8)对其 进行编码。如果 body未给出,则存储空字符串。无论此参数的类型如何,存储的最终值都是str(从不 unicode或None)。
- headers(dict) - 此请求的标头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)。如果
None作为值传递,则根本不会发送HTTP标头。
- cookies(字典或清单) -
请求cookie。这些可以以两种形式发送。
- 使用词典:
request_with_cookies = Request(url="http://www.example.com",
cookies={'currency': 'USD', 'country': 'UY'})
- 使用dicts列表:
request_with_cookies = Request(url="http://www.example.com",
cookies=[{'name': 'currency',
'value': 'USD',
'domain': 'example.com',
'path': '/currency'}])
后一种形式允许自定义 cookie的属性domain和path属性。这仅在保存cookie以供以后请求时才有用。
当某个站点返回cookie(在响应中)时,这些cookie存储在该域的cookie中,并将在将来的请求中再次发送。这是任何常规Web浏览器的典型行为。但是,如果由于某种原因,您希望避免与现有Cookie合并,则可以通过将dont_merge_cookies密钥设置为True 来指示Scrapy执行此操作 Request.meta。
不合并cookie的请求示例:
request_with_cookies = Request(url="http://www.example.com",
cookies={'currency': 'USD', 'country': 'UY'},
meta={'dont_merge_cookies': True})
- encoding(字符串) - 此请求的编码(默认为
'utf-8')。此编码将用于对URL进行百分比编码并将正文转换为str(如果给定unicode)。
- priority(int) - 此请求的优先级(默认为
0)。调度程序使用优先级来定义用于处理请求的顺序。具有更高优先级值的请求将更早执行。允许使用负值以指示相对较低的优先级。
- dont_filter(boolean) - 表示调度程序不应过滤此请求。当您想要多次执行相同的请求时,可以使用此选项来忽略重复过滤器。小心使用它,否则您将进入爬行循环。默认为
False。
- errback(callable) - 在处理请求时引发任何异常时将调用的函数。这包括因404 HTTP错误而失败的页面等。它接收Twisted Failure实例作为第一个参数。有关更多信息,请参阅下面的使用errbacks捕获请求处理中的异常。
- flags(list) - 发送给请求的标志,可用于日志记录或类似目的。
|
|---|
class Response(object_ref):
def __init__(self, url, status=200, headers=None, body=b'', flags=None, request=None):
self.headers = Headers(headers or {})
self.status = int(status)
self._set_body(body)
self._set_url(url)
self.request = request
self.flags = [] if flags is None else list(flags)
......
| 参数: |
- url(字符串) - 此响应的URL
- status(整数) - 响应的HTTP状态。默认为
200。
- headers(dict) - 此响应的标头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)。
- body(字节) - 响应主体。要将解码后的文本作为str(Python 2中的unicode)访问,您可以使用
response.text来自编码感知的 Response子类,例如TextResponse。
- flags(列表) - 是包含
Response.flags属性初始值的列表 。如果给定,列表将被浅层复制。
- request(
Requestobject) - Response.request属性的初始值。这表示Request生成此响应的内容。
|
|---|