一. collections中的abc
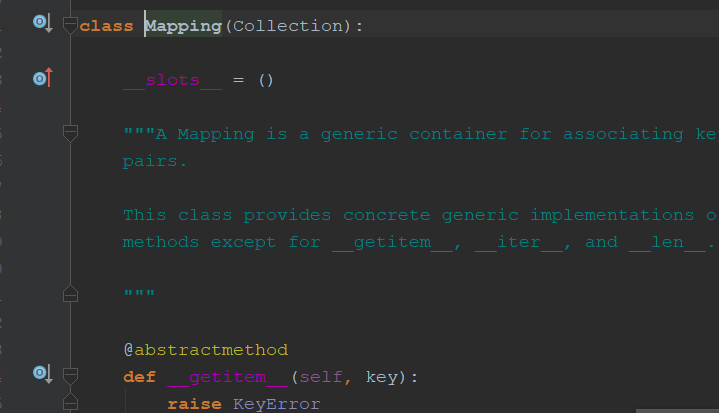
和list(Sequence)相似,都继承于Collection,添加了一些方法
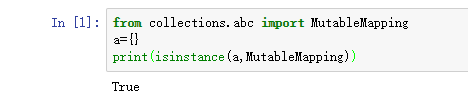
二. dict的常见用法
(setdefault,defaultdict,__missing__方法)
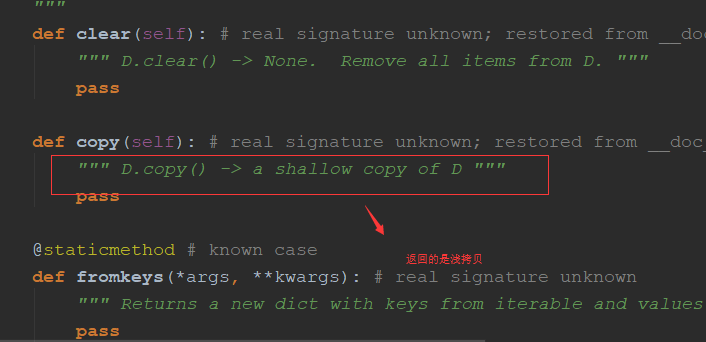
1.copy():
from collections.abc import MutableMapping a = {'LYQ1':{'SWPU':'软件工程'}, 'LYQ2':{'SWPU2':'软件工程2'}} #这是浅拷贝,指向的是同一值,修改一个,另一个也会修改 b=a.copy() b['LYQ1']['SWPU']='我是浅拷贝' print(b) print(a)

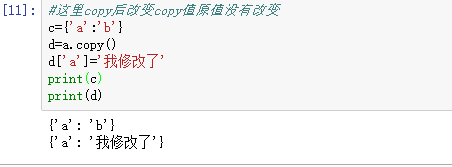
注:copy方法是浅拷贝:深拷贝父对象(一级目录),子对象(二级目录)不拷贝,还是引用
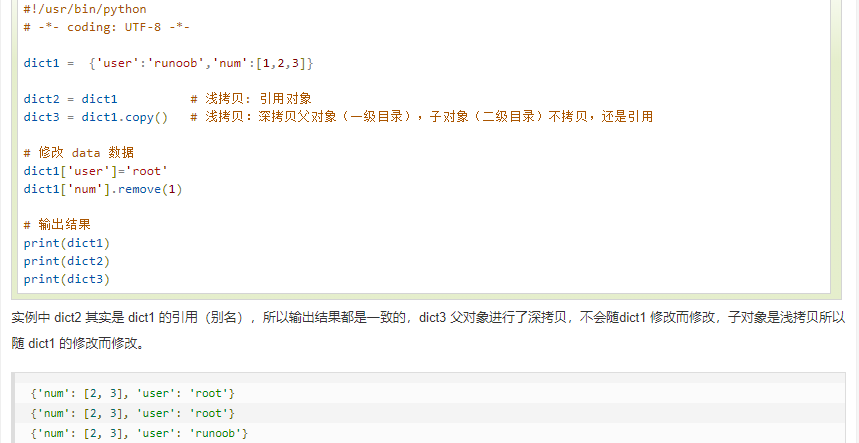
a = {'LYQ1':{'SWPU':'软件工程'},
'LYQ2':{'SWPU2':'软件工程2'}}
import copy
#深拷贝,指向不同的对象
deep_b=copy.deepcopy(a)
deep_b['LYQ1']['SWPU']='我是深拷贝'
print(deep_b)
print(a)

2.fromkeys():
#把一个可迭代对象转换为dict,{'SWPU':'软件工程'}为默认值 my_list=['Stu1','Stu2'] my_dict=dict.fromkeys(my_list,{'SWPU':'软件工程'}) print(my_dict)

3.get():为了预防keyerror
4.items():循环,返回key,value
5.setdefault():将值设置进去,并获取该值返回
my_list=['Stu1','Stu2'] my_dict=dict.fromkeys(my_list,{'SWPU':'软件工程'}) #将值设置进去,并获取该值返回 re_value=my_dict.setdefault('Stu3','HAHA') print(re_value) print(my_dict)

6.update():添加键值对或更新键值对:
a = {'LYQ1':{'SWPU':'软件工程'},
'LYQ2':{'SWPU2':'软件工程2'}}
#添加新键值对(即合并两个字典)
a.update({'LYQ3':'NEW'})
#第二种方式
a.update(LYQ4='NEW2',LYQ5='NEW3')
#第三种方式,list里面放tuple,tuple里面放tuple等(可迭代就行)
a.update([('LYQ6','NEW6')])
print(a)
#修改键值对
a.update({'LYQ1':'我修改了'})
print(a)

三. dict的子类
defaultdict
Counter
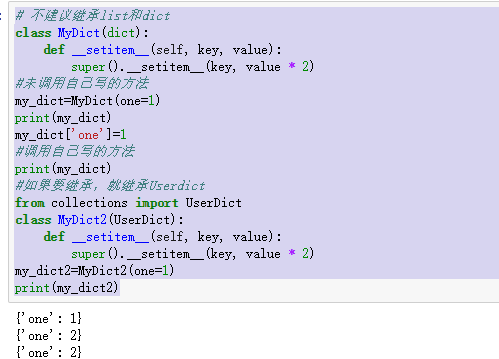
不要去继承内置类型, 有可能会失败比如update方法
# 不建议继承list和dict class MyDict(dict): def __setitem__(self, key, value): super().__setitem__(key, value * 2) #未调用自己写的方法 my_dict=MyDict(one=1) print(my_dict) my_dict['one']=1 #调用自己写的方法 print(my_dict) #如果要继承,就继承Userdict from collections import UserDict class MyDict2(UserDict): def __setitem__(self, key, value): super().__setitem__(key, value * 2) my_dict2=MyDict2(one=1) print(my_dict2)
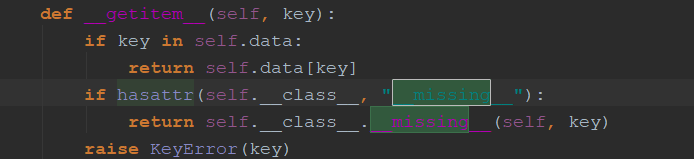
Userdict源码:当取不到某个key时,就会调用__missing__方法(如果有__missing__)获取默认值
2.defaultdict:
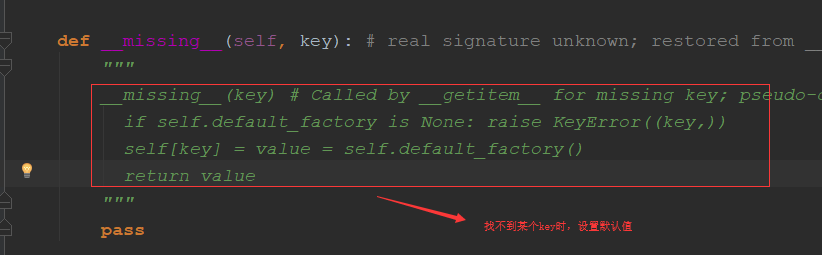
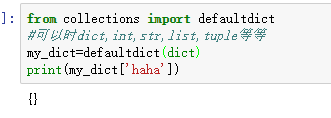
from collections import defaultdict #可以时dict,int,str,list,tuple等等 my_dict=defaultdict(dict)
#找不到key,实际调用的时__missing__方法 print(my_dict['haha'])
四. set和frozenset
1.set:无序,不重复(性能很高)

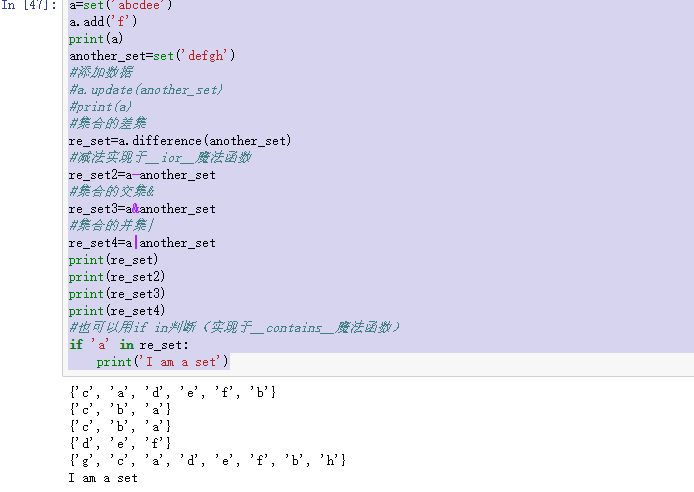
a=set('abcdee') a.add('f') print(a) another_set=set('defgh') #添加数据 #a.update(another_set) #print(a) #集合的差集 re_set=a.difference(another_set) #减法实现于__ior__魔法函数 re_set2=a-another_set #集合的交集& re_set3=a&another_set #集合的并集| re_set4=a|another_set print(re_set) print(re_set2) print(re_set3) print(re_set4) #也可以用if in判断(实现于__contains__魔法函数) if 'a' in re_set: print('I am a set')
2.frozenset:不可变的集合(无序,不重复)
五.dict和set实现原理
1.测试结论:
1.1dict查找的性能远远高于list;
1.2在list中随着list数据的增大,查找时间会增大;
1.3在dict中查找元素不会随着dict的增大而增大
2.dict基于hash表(set也是,所占空间比dict小):
注:1.dict的key或者set的值,都必须是可以hash的(不可变对象都是可以hash的,如str,frozenset,tuple,自己实现的类【实现__hash__魔法函数】);
2.dict内存花销大,但是查询速度快,自定义的对象或者python内置的对象都是用dict包装的;
3.dict的存储顺序与元素添加顺序有关;
4.添加数据有可能改变已有数据的顺序;
5.取数据的时间复杂度为O(1)

通过hash函数计算key(有很多的算法),这里是通过hash函数计算然后与7进行与运算,在计算过程中有可能冲突,得到同样的位置(有很多的解决方法),如’abc‘取一位'c'加一位随机数,如果冲突,就向前多取一位在计算...(还有先声明一个很小的内存空间,可能存在一些空白,计算空白,如果小于1/3,然后声明一个更大的空间,拷贝过去,减少冲突)
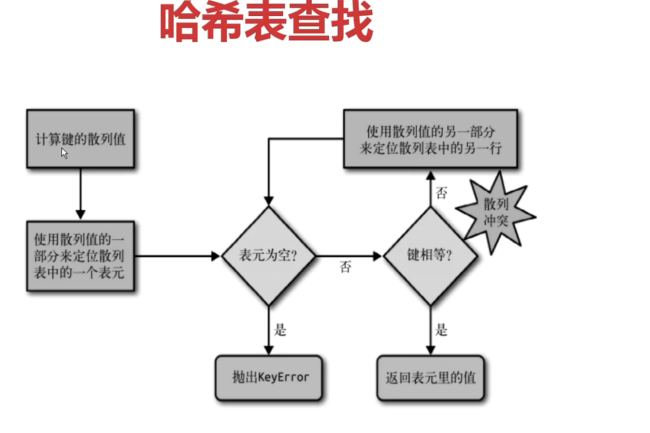
查找数据,先计算hash值定位,查找是否为空,为空就抛出错误,如果不为空查看是否相等,如果被其他占领就不相等,然后又进行冲突解决