继承 表示的是 什么是什么的关系 例如 狗是动物
继承的好处:
b:提高了代码的维护性
c:让类与类之间产生了关系,是多态的前提
面向对象的三大特征: 继承 多态 封装
继承
class Animal:
breath="呼吸"
def _ _init_ _(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
def eat(self):
print(666)
class Person( Animal ):
pass
p1=Person("haha","女",18)
初识继承 : 子类 以及子类 实例化对象, 可以访问父类的 任何方法 或变量
类名可以访问父类中的所有内容
print( Person.braeth ) ===> 呼吸
Person . eat (111) ===> 666
子类实例化的对象 也可以访问 父类中的 所有内容
print( p1.breath )====> 呼吸
p1.eat() =====> 666
只执行父类的方法 : 子类中不要定义与父类同名的方法
只执行子类的方法 : 在子类中创建这个方法
若 既要执行子类中的方法 又要执行父类中的方法 有两种方法解决
class Animal:
def _ _init_ _( self , name , sex, age ) :
self.name=name
self.sex=sex
self.age=age
def eat(self):
print( "呵呵" )
class Bird(Animal):
def _ _init_ _(self,skin)
self.skin=skin
def eat( self ):
方法一 Aimal . eat(self) # 调用父类中的方法
方法二 super().eat(name,sex,age) #
print( "哈哈" )
b1=Bird("小小鸟", "公", "1" ,"彩色")
b1.eat()====> 呵呵 哈哈
类名 + 方法(所需要的参数) # 放置到子类方法中 既可以调用 父类中的 eat()方法, 又可以调用 自己类中的eat()方法
必须将所有参数传进来, 若要调用 _ _init_ _方法则将 (self, name, sex ,age) 都要传进去
super().方法名( 除了self , 所有参数) # 相当于super(本类类名+self), 会自动执行_ _init_ _并将 self 传进来,父类所需要的 参数也要自己输入传进来
class Animal:
def _ _init_ _( self , name , sex, age ) :
self.name=name
self.sex=sex
self.age=age
def eat(self):
print( "呵呵" )
class Bird(Animal):
def _ _init_ _(self, name , sex, age ,skin)
方法一 Aimal . _ _init_ _(self,name,sex,age) # 调用父类中的方法
方法二 super()._ _init_ _(name,sex,age) # 调用父类中的
print('111')
self.skin=skin
def eat( self ):
print( "哈哈" )
b1=Bird("小小鸟", "公", "1" ,"彩色")
b1.eat()====> 111 { name: 小小鸟 , sex : 公 , age: 7 , haha: 彩色 }
继承的进阶
继承: 单继承 多继承
类: 经典类 新式类
新式类: 凡是 继承 object 类的 都是新式类
python 3x 中所有的类都是新式类 ,因为 其中 的类都默认继承 object
经典类 : 不继承 object 类的 都是 经典类
在 python 2 中 所有的类 都 默认 不继承 object , 因此所有的都是 经典类 ,
但是 , 我们 在它终极父类中,让他继承 父类(object) 就变为了 新式类
单继承 , 经典类 类的继承顺序是一样的
现在自身 类中找 如果没有去父类中找,再没有再去父类中找
在任何类中调用的方法, 都要仔细分辨一下 这个self 到底是谁的对象
多继承
新式类 继承顺序 : 遵循 广度优先 ( 每个节点 只走一次 , 当走到一个节点是 倒数第二级 的时候
判断 其他路线 是否可以到达终极父类,
若可以就不走, 从头开始 ,走另一条大路...)
在新式类中 super().func()遵循mro算法 在类的内部不用传子类名和self
因此 super()执行顺序也是 按照 mro算法的顺序来执行的 ,
若每个类中都有super()则先确定好函数的mro 算法,然后按照 mro 顺序执行
经典类 继承顺序 : 遵循 深度优先 ( 一条路 走到头 , 再从头开始 走另一条大路 )
在经典类中 super( 子类名,self ).func(除了self 的参数) 子类名和self 必须手动传
python 2 中没有mro 算法
对于 新式类 来说 直接 print( 类名 . mro ( ) ) 可以直接 查看 类的继承顺序
e.g
class A:
def func(self): 新式类 继承顺序:
print(" A ") A
5
class B(A):
def func(self): B(A) C(A)
print(" B") 3 4
2
class C(A): D(B) E(C)
def func(self):
print(" C ") 1
F(D,E)
class D(B):
def func(self): 先执行F(D,E) ,若没有找 D
print(" D ") 执行 D(B), 若没有找 B
class E(C): 执行 B(A) , A 是终极父类 , 看其他有没有到 A的 如果有 pass 从头开始
def func(self): F(D,F), D走过了, 找E
print(" E ") E(C) , 若找不到 找C
class F(D,E): C(A) , 若找不到 找A
def func(self):
print(" F ")
f1=F()
f1.func()
class A:
def func(self): 经典类 继承顺序:
print(" A ") A
3
class B(A):
def func(self): B(A) C(A)
print(" B") 5
2
class C(A): D(B) E(C)
def func(self):
print(" C ") 1 4
F(D,E)
class D(B):
def func(self): 先执行F(D,E) ,若没有找 D
print(" D ") 执行 D(B), 若没有找 B
class E(C): 执行 B(A) , 若没有找A
def func(self): A若没有 F(D,F), D走过了, 找E
print(" E ") E(C) , 若找不到 找C
class F(D,E):
def func(self):
print(" F ")
f1=F()
f1.func()
多继承 继承顺序 C3算法原理
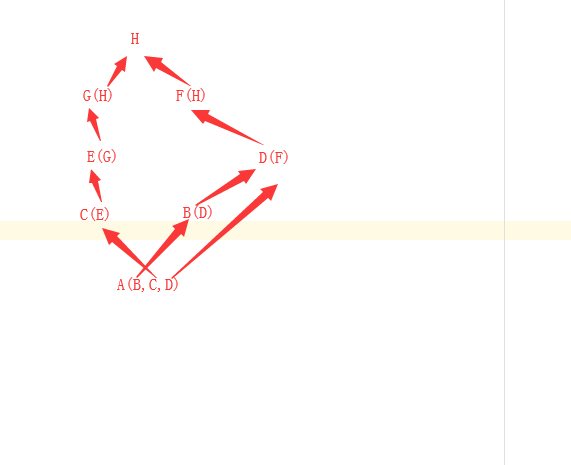
L[B] = [B,D,F,H] #B往上面的继承顺序
L[C] = [C,E,G,H] #C往上面的继承顺序
L[D] = [D,F,H] #D往上面的继承顺序
L[A] = [B,C,D]
这个类名,如果没有,提取出来放到一个列表中,如果有,找下一个列表的头部,循环下去
只要提取来一个,我们就从第一个列表的头部接着重复上面的操作.
1 [B,D,F,H] [C,E,G,H] [D,F,H] [B,C,D]
2 [D,F,H] [C,E,G,H] [D,F,H] [C,D] #提取了头部的B,然后将其他列表头部的B删除,并将B放到list中
3 [D,F,H] [E,G,H] [D,F,H] [D] #因为第一个列表的D在其他列表的尾部存在,所以跳过D,然后找第二个列表的头部C,提取了头部的C,然后将其他列表头部的B删除,并将B放到list中
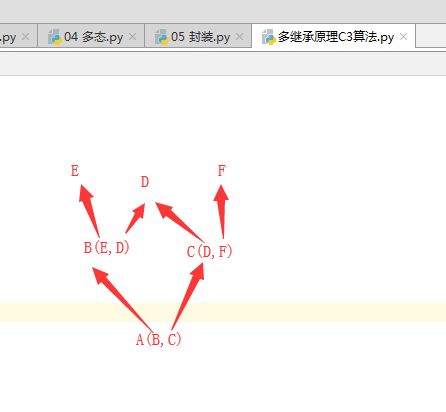
#最高树杈的mro继承顺序
2 [] [E] [D] [E,D]
3 [] [] [D] [D]
list_B = [B,E,D]
2 [] [D] [F] [D,F]
3 [] [] [F] [F]
list_C = [C,D,F]
2 [] [B,E,D] [C,D,F] [B,C]
3 [] [E,D] [C,D,F] [C]
4 [] [D] [C,D,F] [C]
5 [] [D] [D,F] []
6 [] [] [F] []
6 [] [] [] []
list_A [A,B,E,C,D,F]