rio:
rio是一个结构体,rio结构体的作用是提供一个自己设置的IO缓冲区,从sockfd表示的文件中的接收缓冲区中读取数据到rio中,rio相当于一个中转站,获得对端写到sockfd中的数据时,首先将数据读取到rio维护的缓冲区中,然后再从rio维护的缓冲区读取到用户空间指定的区域中。
这个过程中有三个存放数据的区域:
1.sockfd维护的缓冲区:就是read读取数据的来源。这个接收缓冲区接收从对端发送的数据。
2.rio结构体维护的缓冲区:相当于一个中转站,sockfd中的数据首先转移到这里来,再从这转移到用户指定的区域中。
3.用户指定的区域:用户用于处理数据的区域,由自己指定。
rio维护四个成员变量:
1.int rio_fd.这个变量指向要读取的文件的文件描述符,通过这个将一个rio和某个文件绑定在一起。
2.int rio_cnt.这个变量表示rio中尚未转移到用户指定区域的字节数。因为rio从rio_fd指定的文件中读取数据到rio中,rio中存放的数据都是需要转移到用户指定区域的,用rio_cnt表示存在在rio中但尚未转移到用户指定区域的字节数。
3.char* rio_bufptr.这个指针用于指向rio缓冲区中未转移到用户指定区域的数据的起始处。因为rio中的缓冲区是自己设置的,不像sockfd会自己维护一个属于本文件的指针(read每次调用都会调整sockfd中的该指针),因此这个缓冲区需要自己维护,每次读取n个字节后该指针都要后移,保持在未读区域的第一个字节。
4.char rio_buf[MAXLINE].rio维护的缓冲区,用于存放从rio_fd绑定的文件中读取的数据。
rio_read:
read的包裹函数,简易的封装了下read函数。
为什么封装read为rio_read:
封装后,每次rio维护的缓冲区没有数据时,都会一下读入MAXLINE个数据到rio_buf中。然后如果要读取n个字节到用户指定区域,则采用memcpy直接在rio_buf与用户空间间进行拷贝。实际上调用read只是在每次rio_buf无数据,也就是未读数据rio_cnt为0时。
如果不封装,则每次读n个字节都要调用一次read,这样要频繁在用户态和内核态间切换。
read_requestthdrs:
这个函数用于处理头部信息,但因为很简陋,对头部信息没有什么处理的地方。
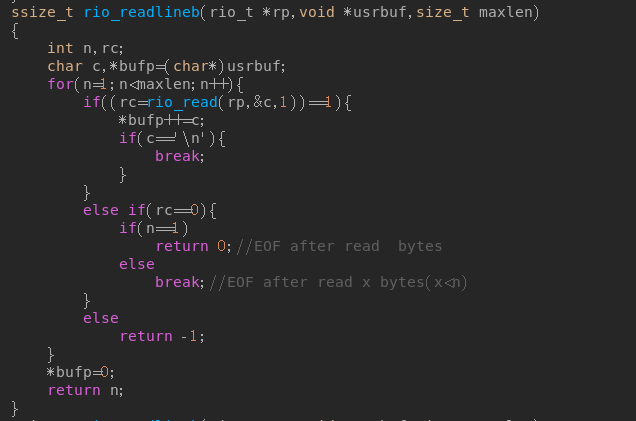
注意,每次Rio_readlineb(rp, buf, MAXLINE);实际上是使用memcpy拷贝的,而memcpy是直接覆盖掉,比如buf之前是"i'm a sb",而Rio_readlineb调用之后,直接从buf头开始覆盖,即使这次覆盖的字符比较少,如"aa",则拷成了"aa� a sb"。
这样只要最后一个请求头" "出现,即使buf拷贝后为" � a sb",strcmp也会判定与" "相等,因为到�实际上就比对结束了。
2019.7.13:http的包内是不含有�的,因此如果要以strcmp的方式来与'
'作对比,在每次rio_readlineb后,必须在
后面补一个�,这样读到
后会补上�,才能变为“
� a sb”.
注意下面图的&bufp=0就是在 后补�。
整个流程实际上是:
首先处理请求行:请求行有method uri version三个信息。method为qingqiu方法,这个版本只能处理GET方法。uri为要请求的资源。version为请求的方法的版本。
然后处理请求头部:包含了客户端的一些信息,如支持的编码,是否保持连接,期望的语言类型。。。
为请求的结尾。读取到 说明这一段的请求解析到此。计网Page271:CRLF作为报文的请求行或head的结尾.CR表示回车,LF表示换行,即 .
parse_uri:
解析URL:
目前只考虑静态文档,因此cgiargs(CGI args)是不必要的(是这样的吗???),因此stcpy给cgiargs一个"",即一个�。
然后将工作目录名传递给文件名filename,因为URI中传递的是相对URL(省略了主机的域名,见计网Page272),因此需要首先加入工作目录名才能定位到请求的文件。
然后将uri中的相对URL加入到filename中,这样就能定位到具体的文件了。
下面的这个if判断的作用是对于URL:http://www.hao123.com/
www.hao123.com为域名,真正传递的相对URL只有"/",除了这种情况,其他任何情况下uri[strlen[uri]-1]都不可能是'/'。这种情况应该跳转到主页,所以在filename后面加入的是home_page。
动态文档先跳过。
serve_static:
用于处理静态页面的函数。
其中调用了get_filetype。get_filetype写来用于获得发送过去的文件的文件类型,通过get_filetype获取得到返回文件的文件类型,将它写入filetype中,filetype是用于响应报文的首部行中。
serve_static实际上是构造回复的头部,打开文件与发送文件。
sprintf(buf, "HTTP/1.0 200 OK ");用于在buf中写入状态行。
//--------------------------------------
get_filetype(filename, filetype);
sprintf(buf, "%sServer: Tiny Web Server ", buf);//这里的用法:Server:....的内容相当于附加到原来的buf上,很巧妙。
sprintf(buf, "%sContent-length: %d ", buf, filesize);
sprintf(buf, "%sContent-type: %s ", buf, filetype);
这四行用于构造响应报文的首部行,并将首部行写入buf中。
//--------------------------------------
Rio_writen(fd, buf, strlen(buf));
将构造的状态行和首部行写入文件fd
//--------------------------------------
srcfd = Open(filename, O_RDONLY, 0);
打开要发送过去的文件,srcfd绑定在该文件上。
srcp = (char *)Mmap(0, filesize, PROT_READ, MAP_PRIVATE, srcfd, 0);
用mmap的方式在srcfd与fd间进行数据的传输。
mmap的用法:
APUE Page 422
Mmap为mmap的简单封装。
mmap原型:void* mmap(void* addr,size_t len,int prot,int flag,int fd,off_t off);
返回值void*表示返回一个指针,该指针指向从fd所映射到的内存区域的起始地址。
addr一般设置为0,这个参数用于选择映射区域的起始地址,设为0由系统选取。
len为要映射文件内容的大小。
prot为映射区域的保护性要求:
PROT_READ 映射区可读
PROT_WRITE 映射区可写
PROT_EXEC 映射区可执行
PROT_NONE 映射区不可访问
flag为映射区属性:设置为MAP_SHARED代表修改映射区也会修改fd指向的文件;设置为MAP_PRIVATE则映射区为一个副本,不用担心对文件造成影响。
off为要映射的内容在文件的起始偏移(如果从开开始则设为0就可以)。
如果从srcfd中读取内容,在写入dstfd中的话,首先要从srcfd中read到内存,然后再从内存write到dstfd。
而引入mmap后,不需要read和write,srcfd与dstfd直接通过内存相互联系。
//----------------------------------------
Rio_writen(fd, srcp, filesize);
将映射到内存srcp处的文件内容写入fd.
//----------------------------------------
Munmap(srcp, filesize);
Munmap为munmap的简单封装。
munmap与mmap成套使用,map<-------------->unmap.
munmap用于解除srcp处的映射,解除后再访问则会发生段错误。
serve_dynamic:
处理动态页面的函数,因为目前只处理静态页面,因此在函数中,在构造完响应报文的状态行和首部行后,直接return而不处理要发送过去的数据内容。
另外这里面一个地方:
Rio_writen(fd,(void*)" ",2);
这里Rio_writen将第二个参数指向的地址中,写入第三个参数指定的字节数到第一个参数指定的文件中,即从写入 到fd绑定改的文件中。" "实际上是位于常量区的,用void*取得它的地址,然后由第三个参数知道要写2字节到fd中。
另外c++中,cout对<<进行了重载,在很多情况下,如char* p="i'm a sb",cout<<p因为对char*进行了重载的缘故而输出的是char*指向区域的内容,如果要看p指向区域的地址,则强制转换成void*就好了,如cout<<(void*)p。
return之后:
其实这部分内容无意义。
首先Fork()创建子进程。
首先是子进程:
子进程用setenv设置环境变量"QUERY_STRING"为CGI参数cgiargs。
然后用Dup2将fd(这个fd为套接字的文件描述符)复制到标准输出栏。这样的目的,因为原本子进程是用于execve一个新程序,这样将标准输出替换为fd后,则新程序中,原本要输出到标准输出的数据,现在全部往fd,也就是套接字中输出了。
然后子进程用Execve开始执行新程序。
关于Execve:
原型为:int execve(const char *filename, char *const argv[ ], char *const envp[ ]);
filename为新程序文件所处的位置,根据filename来定位并执行它。
因为execve相当于替换原子进程,即从新执行一个程序,从int main开始执行,第二个参数argv[]就是相当于这个新程序的main所需要的参数,这里argv是个数组,数组内存放着char* const型的常指针(不可更改指向)。
第三个参数为传递给新程序的环境变量数组。
对于父进程:
等待子进程终止。wait()的参数int* status指针用于存放子进程的终止状态,如果不关心则设置为NULL。
