1、为什么使用redis
主要是从两个角度去考虑:性能和并发。
一、性能
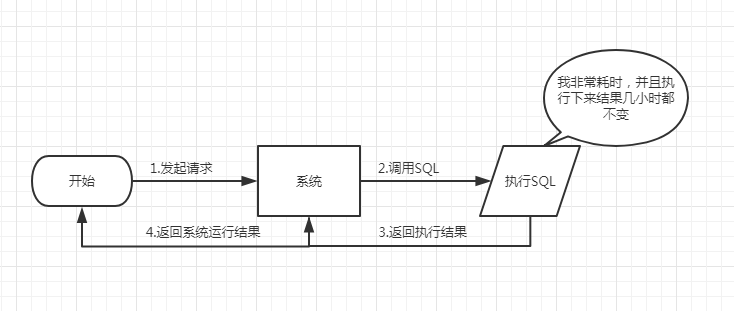
如下图所示,我们在碰到需要执行耗时特别久,且结果不频繁变动的SQL,特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求迅速响应。
二、并发
如上图所示,在大并发的情况下,所有的请求都直接访问数据库,数据库会出现超时或者连接异常。这个时候,需要redis做一个缓冲操作,让请求先访问redis,而不是直接访问数据库。
2、redis数据结构
redis是一种高级的key:value 存储系统,其中value支持五种数据类型:
1.字符串(string)
2.字符串列表(lists)
3.字符串集合(sets)
4.有序字符串集合(sorted sets)
5.哈希(hashes)
key:
1.key不要太长,尽量不要超过1024字节,这不仅消耗内存,而且会降低查找的效率。
2.key也不要太短,太短可读性太低。
3.在一个项目中,key最好使用统一的命名模式,例如:10000:password。
3、Hash存储数据结构
其中一种常用存储数据:使用一个key获取对象,必须使用反序列化。