一、一堆废话
研一刚开学,选了导师以后开始定方向,本来是想去做mhy那个动作生成的岗位,然后去给导师说做姿态识别,老师给我表示支持以后叫我开始看双流法啥的,后来想了想,发现应该是学GAN才对
给导师说了以后,导师还是给了支持并且告诉我大致方向(呜呜呜王老师太好了,又负责又包容),所以导师给了推荐就是李宏毅老师的GAN教学视频,用了快不到两个星期刷了前面(后面的各类gan我还没看,只想赶紧做点东西出来)然后就看见有个hw是动漫头像的生成
二、真正的CV工程师!(ctrl+c&ctrl+v)
我自己总结了一下gan的大致内容准备开始凭着自己的理解写代码,最后倒是写完了,但是生成的全是黑的图片,问题应该是我最后生成的像素的值由于归一化或者sigmoid函数之类的东西把我最后输出来的像素值全部只有0到1的大小
接着去网上扒了别人的代码,是csdn一个叫张先生您好的博主,里面说的很明白了,我这里把我自己总结出来的流程大概写一下
从知乎一个叫一个完整的Pytorch深度学习项目代码,项目结构是怎样的?这个问题里有回答总结了流程
- 模型定义
- 数据处理和加载
- 训练模型(Train and Validate)
- 测试模型
- 训练过程可视化(可选)
但是在GAN里好像没有测试模型这一步(目前我不知道,知道以后会回来补充的),毕竟也不像分类问题那样可以测试,所以我总结的是
- 各项参数定义
- 模型定义
- 训练模型(数据处理和加载也包含在内)
- 输出生成器的生成结果
整个项目文件已经上传到我的gitee了,没有包含数据集(反正也是写给自己看的),要数据集的话搜一下也能找到
其中运行"main.py"就可以跑起来整个代码


1 import train 2 import generate 3 4 def main(): 5 # 训练模型 6 #train.train() 7 # 生成图片 8 generate.generate() 9 10 11 if __name__ == '__main__': 12 main()
main方法中明确了主要就是训练和输出整个训练结束的效果
所以我会依照上面的步骤贴上每个代码
三、具体步骤
1、各项参数定义
1 class Config(object): 2 """ 3 定义一个配置类 4 """ 5 # 0.参数调整 6 data_path = '/extra_data' 7 virs = "result" 8 num_workers = 4 # 多线程 9 img_size = 64 # 剪切图片的像素大小 10 batch_size = 256 # 批处理数量 11 max_epoch = 400 # 最大轮次 12 lr1 = 2e-4 # 生成器学习率 13 lr2 = 2e-4 # 判别器学习率 14 beta1 = 0.5 # 正则化系数,Adam优化器参数 15 gpu = True # 是否使用GPU运算(建议使用) 16 nz = 100 # 噪声维度 17 ngf = 64 # 生成器的卷积核个数 18 ndf = 64 # 判别器的卷积核个数 19 20 # 1.模型保存路径 21 save_path = 'save_img/' # opt.netg_path生成图片的保存路径 22 # 判别模型的更新频率要高于生成模型 23 d_every = 1 # 每一个batch 训练一次判别器 24 g_every = 5 # 每1个batch训练一次生成模型 25 save_every = 5 # 每save_every次保存一次模型 26 netd_path = None 27 netg_path = None 28 29 # 测试数据 30 gen_img = "result1.png" 31 # 选择保存的照片 32 # 一次生成保存64张图片 33 gen_num = 64 34 gen_search_num = 512 35 gen_mean = 0 # 生成模型的噪声均值 36 gen_std = 1
2、模型定义
这里用的是最基础的GAN,所以就是vector→生成器→图片→判别器→打分这样的结构,没有其他的网络了
所以定义的就是两个模型Generation和Discrimination
Generation
1 import torch.nn as nn 2 3 class Generation(nn.Module): 4 def __init__(self, opt): 5 super(Generation, self).__init__() 6 self.ngf = opt.ngf 7 self.Gene = nn.Sequential( 8 nn.ConvTranspose2d(in_channels=opt.nz, out_channels=self.ngf * 8, kernel_size=4, stride=1, padding=0, 9 bias=False), 10 nn.BatchNorm2d(self.ngf * 8), 11 nn.ReLU(inplace=True), 12 13 # 输入一个4*4*ngf*8 14 nn.ConvTranspose2d(in_channels=self.ngf * 8, out_channels=self.ngf * 4, kernel_size=4, stride=2, padding=1, 15 bias=False), 16 nn.BatchNorm2d(self.ngf * 4), 17 nn.ReLU(inplace=True), 18 19 # 输入一个8*8*ngf*4 20 nn.ConvTranspose2d(in_channels=self.ngf * 4, out_channels=self.ngf * 2, kernel_size=4, stride=2, padding=1, 21 bias=False), 22 nn.BatchNorm2d(self.ngf * 2), 23 nn.ReLU(inplace=True), 24 25 # 输入一个16*16*ngf*2 26 nn.ConvTranspose2d(in_channels=self.ngf * 2, out_channels=self.ngf, kernel_size=4, stride=2, padding=1, 27 bias=False), 28 nn.BatchNorm2d(self.ngf), 29 nn.ReLU(inplace=True), 30 31 # 输入一张32*32*ngf 32 nn.ConvTranspose2d(in_channels=self.ngf, out_channels=3, kernel_size=5, stride=3, padding=1, bias=False), 33 34 # Tanh收敛速度快于sigmoid,远慢于relu,输出范围为[-1,1],输出均值为0 35 nn.Tanh(), 36 37 ) # 输出一张96*96*3 38 39 def forward(self, x): 40 return self.Gene(x)
用convtranspose2d反卷积做上采样
批标准化层的作用,使得每一层的输出都尽力较为分散的落在数轴的两端,尽量使得数据处于梯度的敏感区域,加速梯度下降的过程如下

这里的relu函数里有一个inplace参数,这个参数作用为
产生的计算结果不会有影响。利用in-place计算可以节省内(显)存,同时还可以省去反复申请和释放内存的时间。但是会对原变量覆盖,所以只要不带来错误就用。
Discrimination
1 import torch.nn as nn 2 3 class Discrimination(nn.Module): 4 def __init__(self, opt): 5 super(Discrimination, self).__init__() 6 self.ndf = opt.ndf 7 self.Discrim = nn.Sequential( 8 nn.Conv2d(in_channels=3, out_channels=self.ndf, kernel_size=5, stride=3, padding=1, bias=False), 9 nn.LeakyReLU(negative_slope=0.2, inplace=True), 10 11 nn.Conv2d(in_channels=self.ndf, out_channels=self.ndf * 2, kernel_size=4, stride=2, padding=1, bias=False), 12 nn.BatchNorm2d(self.ndf * 2), 13 nn.LeakyReLU(0.2, True), 14 15 nn.Conv2d(in_channels=self.ndf * 2, out_channels=self.ndf * 4, kernel_size=4, stride=2, padding=1, 16 bias=False), 17 nn.BatchNorm2d(self.ndf * 4), 18 nn.LeakyReLU(0.2, True), 19 20 nn.Conv2d(in_channels=self.ndf * 4, out_channels=self.ndf * 8, kernel_size=4, stride=2, padding=1, 21 bias=False), 22 nn.BatchNorm2d(self.ndf * 8), 23 nn.LeakyReLU(0.2, True), 24 25 26 nn.Conv2d(in_channels=self.ndf * 8, out_channels=1, kernel_size=4, stride=1, padding=0, bias=True), 27 28 nn.Sigmoid() 29 ) 30 31 def forward(self, x): 32 # 展平后返回 33 return self.Discrim(x).view(-1)
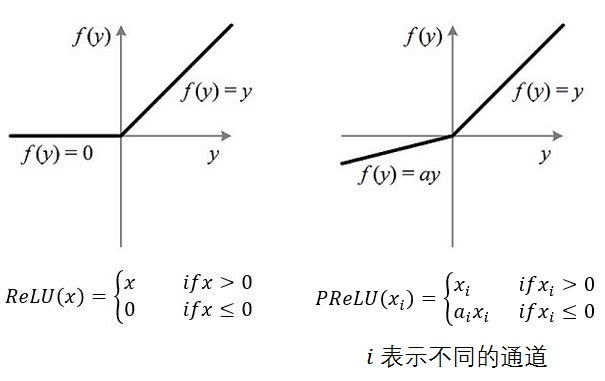
这里用了leakyrelu(也就是PRelu,parameter relu)的激活函数,GAN的创始人Ian Goodfellow说过(知乎看到的,但是我没找到出处): Leaky relu helps to make sure the gradient can flow through the entire architecture. That's an important consideration for any machine learning model, but even more important for GAN's.
leakyrelu防止了relu由于输出为负时,反向传播梯度为零导致神经元死亡
relu和leakyrelu函数图如下
3、训练模型(数据处理和加载也包含在内)
因为图像全部都在一个文件夹里,所以这里没有重写dataset来做数据集而用的是imagefolder,以后做音乐到动作的生成的话,还需要自己重写一些dataset
1 from tqdm import tqdm 2 import torch 3 import torchvision as tv 4 from torch.utils.data import DataLoader 5 import torch.nn as nn 6 from Config import Config 7 from Model.Generation import Generation 8 from Model.Discrimination import Discrimination 9 10 opt = Config() 11 12 def train(**kwargs): 13 # 配置属性 14 # 如果函数无字典输入则使用opt中设定好的默认超参数 15 for k_, v_ in kwargs.items(): 16 setattr(opt, k_, v_) 17 18 # device(设备),分配设备 19 if opt.gpu: 20 device = torch.device("cuda") 21 else: 22 device = torch.device('cpu') 23 24 # 数据预处理1 25 # transforms 模块提供一般图像转换操作类的功能,最后转成floatTensor 26 # tv.transforms.Compose用于组合多个tv.transforms操作,定义好transforms组合操作后,直接传入图片即可进行处理 27 # tv.transforms.Resize,对PIL Image对象作resize运算, 数值保存类型为float64 28 # tv.transforms.CenterCrop, 中心裁剪 29 # tv.transforms.ToTensor,将opencv读到的图片转为torch image类型(通道,像素,像素),且把像素范围转为[0,1] 30 # tv.transforms.Normalize,执行image = (image - mean)/std 数据归一化操作,一参数是mean,二参数std 31 # 因为是三通道,所以mean = (0.5, 0.5, 0.5),从而转成[-1, 1]范围 32 transforms = tv.transforms.Compose([ 33 # 3*96*96 34 tv.transforms.Resize(opt.img_size), # 缩放到 img_size* img_size 35 # 中心裁剪成96*96的图片。因为本实验数据已满足96*96尺寸,可省略 36 # tv.transforms.CenterCrop(opt.img_size), 37 38 # ToTensor 和 Normalize 搭配使用 39 tv.transforms.ToTensor(), 40 tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) 41 ]) 42 43 # 加载数据并使用定义好的transforms对图片进行预处理,这里用的是直接定义法 44 # dataset是一个包装类,将数据包装成Dataset类,方便之后传入DataLoader中 45 # 写法2: 46 # 定义类Dataset(Datasets)包装类,重写__getitem__(进行transforms系列操作)、__len__方法(获取样本个数) 47 # ### 两种写法有什么区别 48 dataset = tv.datasets.ImageFolder(root=opt.data_path, transform=transforms) 49 50 # 数据预处理2 51 # 查看drop_last操作, 52 dataloader = DataLoader( 53 dataset, # 数据加载 54 batch_size=opt.batch_size, # 批处理大小设置 55 shuffle=True, # 是否进行洗牌操作 56 # num_workers=opt.num_workers, # 是否进行多线程加载数据设置 57 drop_last=True # 为True时,如果数据集大小不能被批处理大小整除,则设置为删除最后一个不完整的批处理。 58 ) 59 60 # 初始化网络 61 netg, netd = Generation(opt), Discrimination(opt) 62 # 判断网络是否有权重数值 63 # ### storage存储 64 map_location = lambda storage, loc: storage 65 66 # torch.load模型加载,即有模型加载模型在该模型基础上进行训练,没有模型则从头开始 67 # f:类文件对象,如果有模型对象路径,则加载返回 68 # map_location:一个函数或字典规定如何remap存储位置 69 # net.load_state_dict将加载出来的模型数据加载到构建好的net网络中去 70 if opt.netg_path: 71 netg.load_state_dict(torch.load(f=opt.netg_path, map_location=map_location)) 72 if opt.netd_path: 73 netd.load_state_dict(torch.load(f=opt.netd_path, map_location=map_location)) 74 75 # 搬移模型到之前指定设备,本文采用的是cpu,分配设备 76 netd.to(device) 77 netg.to(device) 78 79 # 定义优化策略 80 # torch.optim包内有多种优化算法, 81 # Adam优化算法,是带动量的惯性梯度下降算法 82 optimize_g = torch.optim.Adam(netg.parameters(), lr=opt.lr1, betas=(opt.beta1, 0.999)) 83 optimize_d = torch.optim.Adam(netd.parameters(), lr=opt.lr2, betas=(opt.beta1, 0.999)) 84 85 # 计算目标值和预测值之间的交叉熵损失函数 86 # BCEloss:-w(ylog x +(1 - y)log(1 - x)) 87 # y为真实标签,x为判别器打分(sigmiod,1为真0为假),加上负号,等效于求对应标签下的最大得分 88 # to(device),用于指定CPU/GPU 89 criterions = nn.BCELoss().to(device) 90 91 # 定义标签,并且开始注入生成器的输入noise 92 true_labels = torch.ones(opt.batch_size).to(device) 93 fake_labels = torch.zeros(opt.batch_size).to(device) 94 95 # 生成满足N(1,1)标准正态分布,opt.nz维(100维),opt.batch_size个数的随机噪声 96 noises = torch.randn(opt.batch_size, opt.nz, 1, 1).to(device) 97 98 # 用于保存模型时作生成图像示例 99 fix_noises = torch.randn(opt.batch_size, opt.nz, 1, 1).to(device) 100 101 # 训练网络 102 # 设置迭代 103 for epoch in range(opt.max_epoch): 104 # tqdm(iterator()),函数内嵌迭代器,用作循环的进度条显示 105 for ii_, (img, _) in tqdm((enumerate(dataloader))): 106 # 将处理好的图片赋值 107 real_img = img.to(device) 108 109 # 开始训练生成器和判别器 110 # 注意要使得生成的训练次数小于一些 111 # 每一轮更新一次判别器 112 if ii_ % opt.d_every == 0: 113 # 优化器梯度清零 114 optimize_d.zero_grad() 115 116 # 训练判别器 117 # 把判别器的目标函数分成两段分别进行反向求导,再统一优化 118 # 真图 119 # 把所有的真样本传进netd进行训练, 120 output = netd(real_img) 121 # 用之前定义好的交叉熵损失函数计算损失 122 error_d_real = criterions(output, true_labels) 123 # 误差反向计算 124 error_d_real.backward() 125 126 # 随机生成的假图 127 # .detach() 返回相同数据的 tensor ,且 requires_grad=False 128 # .detach()做截断操作,生成器不记录判别器采用噪声的梯度 129 noises = noises.detach() 130 # 通过生成模型将随机噪声生成为图片矩阵数据 131 fake_image = netg(noises).detach() 132 # 将生成的图片交给判别模型进行判别 133 output = netd(fake_image) 134 # 再次计算损失函数的计算损失 135 error_d_fake = criterions(output, fake_labels) 136 # 误差反向计算 137 # 求导和优化(权重更新)是两个独立的过程,只不过优化时一定需要对应的已求取的梯度值。 138 # 所以求得梯度值很关键,而且,经常会累积多种loss对某网络参数造成的梯度,一并更新网络。 139 error_d_fake.backward() 140 141 # ‘’‘ 142 # 关于为什么要分两步计算loss: 143 # 我们已经知道,BCEloss相当于计算对应标签下的得分,那么我们 144 # 把真样本传入时,因为标签恒为1,BCE此时只有第一项,即真样本得分项 145 # 要补齐成前文提到的判别器目标函数,需要再添置假样本得分项,故两次分开计算梯度,各自最大化各自的得分(假样本得分是log(1-D(x))) 146 # 再统一进行梯度下降即可 147 # ’‘’ 148 # 计算一次Adam算法,完成判别模型的参数迭代 149 # 多个不同loss的backward()来累积同一个网络的grad,计算一次Adam即可 150 optimize_d.step() 151 152 # 训练判别器 153 if ii_ % opt.g_every == 0: 154 optimize_g.zero_grad() 155 # 用于netd作判别训练和用于netg作生成训练两组噪声需不同 156 noises.data.copy_(torch.randn(opt.batch_size, opt.nz, 1, 1)) 157 fake_image = netg(noises) 158 output = netd(fake_image) 159 # 此时判别器已经固定住了,BCE的一项为定值,再求最小化相当于求二项即G得分的最大化 160 error_g = criterions(output, true_labels) 161 error_g.backward() 162 163 # 计算一次Adam算法,完成判别模型的参数迭代 164 optimize_g.step() 165 166 # 保存模型 167 if (epoch + 1) % opt.save_every == 0: 168 fix_fake_image = netg(fix_noises) 169 tv.utils.save_image(fix_fake_image.data[:64], "%s/%s.png" % (opt.save_path, epoch), normalize=True) 170 171 torch.save(netd.state_dict(), 'sava_pra/' + 'netd_{0}.pth'.format(epoch)) 172 torch.save(netg.state_dict(), 'sava_pra/' + 'netg_{0}.pth'.format(epoch))
1 setattr(opt, k_, v_)
这个函数的作用是可以更改opt类里的属性k_的值为v_
晚上读代码的时候和组内的大佬一起讨论了一下这个transforms.compose里的resize是怎么做到的,我们本来以为是padding黑边,然后后来经过试验发现不是黑边,所以去读了一下文档看看是怎么说的,文档里说resize是线性插值的几种方法,在不设定的时候默认插值方法是InterpolationMode.BILINEAR,这也想想也对,如果插值黑边的话,对于原图的特征提取其实也是一种噪声,用插值的方法做出来的图不见得最好,但起码不会是一个坏的选择
接着是这里有一个lambda匿名函数,传入的参数是storage和loc,返回storage(目前不知道这个函数能干嘛,但是注释掉的话下面的那个torch.load里的maplocation会报错)
4、输出生成器的生成结果
1 import torch 2 import torchvision as tv 3 from Config import Config 4 from Model.Generation import Generation 5 from Model.Discrimination import Discrimination 6 7 opt = Config() 8 9 @torch.no_grad() 10 def generate(**kwargs): 11 # 用训练好的模型来生成图片 12 13 for k_, v_ in kwargs.items(): 14 setattr(opt, k_, v_) 15 16 device = torch.device("cuda") if opt.gpu else torch.device("cpu") 17 18 # 加载训练好的权重数据 19 netg, netd = Generation(opt).eval(), Discrimination(opt).eval() 20 # 两个参数返回第一个 21 map_location = lambda storage, loc: storage 22 23 # opt.netd_path等参数有待修改 24 netd.load_state_dict(torch.load('sava_pra/netd_399.pth', map_location=map_location), False) 25 netg.load_state_dict(torch.load('sava_pra/netg_399.pth', map_location=map_location), False) 26 netd.to(device) 27 netg.to(device) 28 29 # 生成训练好的图片 30 # 初始化512组噪声,选其中好的拿来保存输出。 31 noise = torch.randn(opt.gen_search_num, opt.nz, 1, 1).normal_(opt.gen_mean, opt.gen_std).to(device) 32 33 fake_image = netg(noise) 34 score = netd(fake_image).detach() 35 36 # 挑选出合适的图片 37 # 取出得分最高的图片 38 indexs = score.topk(opt.gen_num)[1] 39 40 result = [] 41 42 for ii in indexs: 43 result.append(fake_image.data[ii]) 44 45 # 以opt.gen_img为文件名保存生成图片 46 tv.utils.save_image(torch.stack(result), opt.gen_img, normalize=True, range=(-1, 1))
# @torch.no_grad():数据不需要计算梯度,也不会进行反向传播
这里取了64张照片出来,具体的做法是discriminator会给512张照片打分,然后用topk函数取64个分最高的出来,记录他们的下标到index里,遍历index然后用下标吧每张图像append到result中
这里说一下topk函数
1 import torch 2 3 list = [2,3,5,7,2,98,9,2,4,78,8] 4 t = torch.tensor(list).detach() 5 6 print(t.topk(3)) 7 print('-----------------') 8 print(t.topk(3)[0]) 9 print('-----------------') 10 print(t.topk(3)[1]) 11 print('-----------------')
打印结果为
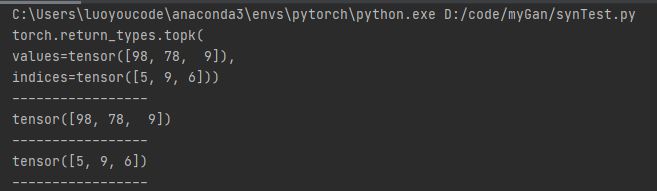
topk函数可以返回前k大的张量以及他们的下标
但是由于result是列表(相当于所有图在一行),所以下面用了一个stack把列表升维成了一张8*8的图组成的大图
最后我挑了一张图做了头像(粉毛妹子好耶!)
